
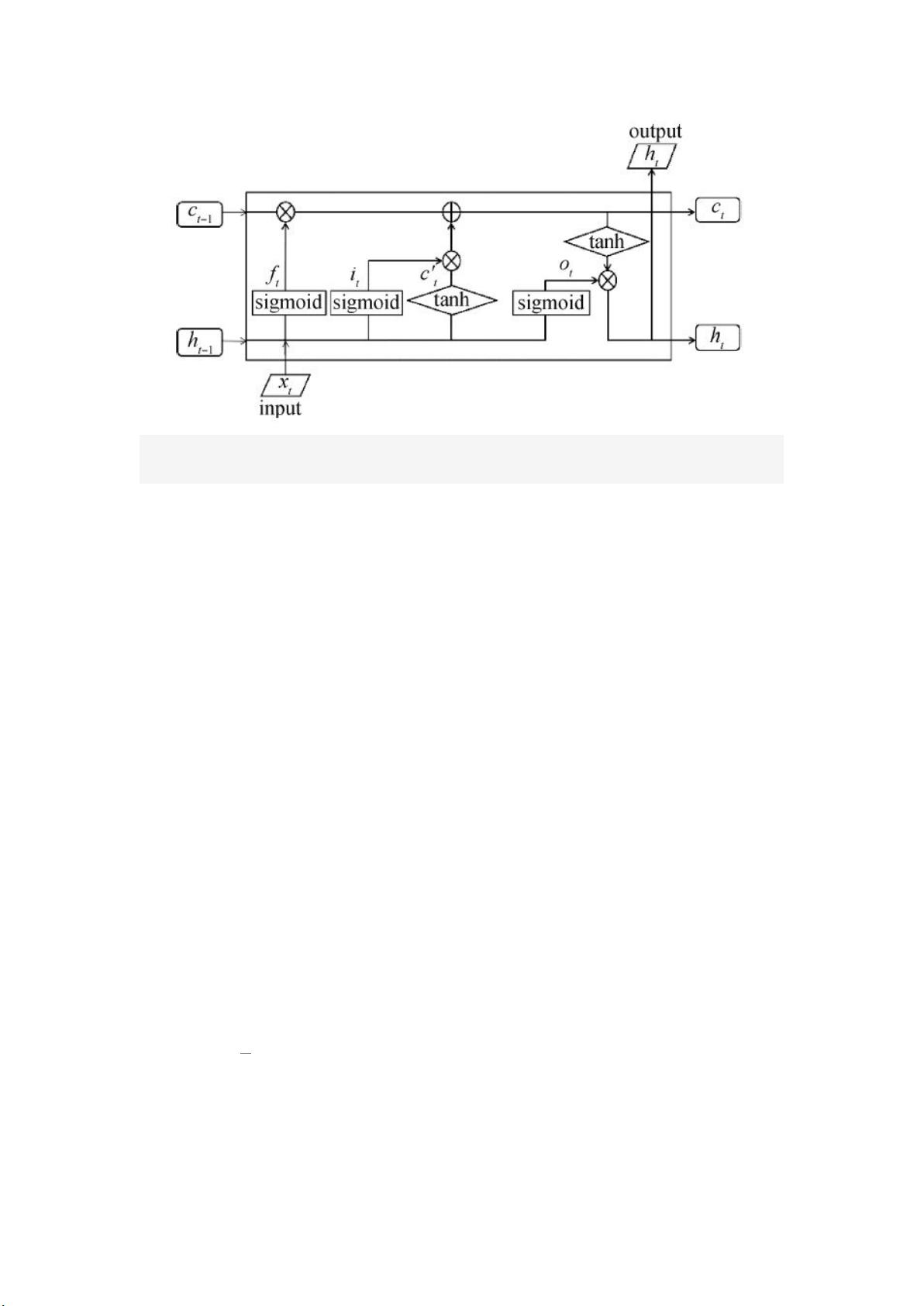
图 2LSTM 神经网络模型
Fig.2LSTM Model
LSTM 循环单元中输入数据 x(t),隐藏层输出 h(t)。其中 h(t)的表达
形式比较复杂,包括三个门结构:输入门 i(Input Gate)决定加入多少新信息;遗
忘门 f(Forget Gate)决定丢弃多少旧信息;输出门 o(Output Gate)控制输出
到下一个单元多少信息以及一个记忆控制器 c 存储当前单元的信息。整个过程如
公式(1)-公式(5)所示,其中 W 和 b 为模型参数,tanh 为双曲正切函数。
ft=σ(Wf∙[ht−1,xt]+bf)ft=σ(Wf∙[ht-1,xt]+bf)
(1)
it=σ(Wi∙[ht−1,xt]+bi )it=σ(Wi∙[ht-1,xt]+bi)
(2)
ct=ft⊗ct−1+it⊗tanh(W c∙[ht−1,xt]+bc)ct=ft⊗ct-1+it⊗tanh(Wc∙[ht-
1,xt]+bc)
(3)
ot=σ(Wo∙[ht−1,xt]+bo)ot=σ(Wo∙[ht-1,xt]+bo)
(4)
ht=ot⊗tanh(ct)ht=ot⊗tanh(ct)
(5)
然而 ,LSTM 模 型只能 在一 个方 向上处 理信息 , 忽 视了对下 文信息的 依赖。
Schuster 等
[11
]
提出双向循环神经网络(BRNN),每一个训练序列向前和向后分
别是两个循环神经网络,而用 LSTM 模型的循环单元替代 BRNN 模型中的单元,
既能从上下两个方向处理单元信息,又能处理信息的长期依赖关系。
因此,本文采用双向 LSTM 模型与 CRF 模型相结合的方式,构建 LSTM-CRF
模型。该模型通过在双向 LSTM 模型的隐藏层后加入一层 CRF 线性层,实现线性
剩余16页未读,继续阅读

罗伯特之技术屋
- 粉丝: 4359
- 资源: 1万+

下载权益

电子书特权

VIP文章

课程特权
开通VIP
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


