深度残差学习:ResNet在图像识别中的突破
下载需积分: 13 | PDF格式 | 352KB |
更新于2024-08-29
| 160 浏览量 | 举报
"《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》\n\n深度学习在图像识别领域的研究一直在不断深化,尤其是在卷积神经网络(Convolutional Neural Networks, CNN)的设计和优化上。该论文《Deep Residual Learning for Image Recognition》由Kaiming He、Xiangyu Zhang、Shaoqing Ren和Jian Sun等来自微软研究院的研究人员提出,他们针对深度网络训练中的挑战提出了革命性的解决方案——残差学习框架。\n\n传统的深层神经网络在训练时面临着梯度消失或爆炸的问题,使得网络的深度受到限制。论文的核心创新在于将每一层视为对输入特征的残差函数进行学习,而不是独立于输入的无参照函数。这种设计让模型能够更好地处理深层网络中的信息传递,减少了梯度传播中的问题,从而简化了训练过程。实验证明,这种残差网络(Residual Network, ResNet)不仅更容易优化,而且即使在网络深度大幅增加(如比VGG网络深8倍,达到152层)的情况下,仍能保持较低的复杂度。\n\n在ImageNet大规模视觉识别挑战赛(ILSVRC 2015)中,ResNet团队提交的模型实现了3.57%的错误率,赢得了分类任务的第一名,这表明其在实际应用中的优越性能。此外,论文还探讨了在CIFAR-10数据集上使用100层和1000层的残差网络,进一步验证了这一框架的有效性。\n\n深度表示的重要性在视觉识别任务中不可忽视,尤其是对于解决复杂的图像理解问题。通过ResNet的残差结构,研究人员揭示了深度增加并非导致性能下降的原因,而是深度与学习效率之间的有效平衡。这项工作不仅提升了深度学习模型的性能,也为后续的深度网络设计提供了新的思考方向,推动了整个计算机视觉领域的技术进步。\n总结来说,这篇论文在深度学习领域的重要贡献是提出了残差学习的概念,证明了深度网络在适当架构下可以突破深度限制,提高图像识别的准确性和模型的训练效率。这一成果对后来的深度学习模型如Inception-v4和Inception-ResNet产生了深远影响,展示了深度学习研究在解决实际问题上的强大潜力。"
Deep Residual Learning for Image Recognition
Kaiming He Xiangyu Zhang Shaoqing Ren Jian Sun
Microsoft Research
{kahe, v-xiangz, v-shren, jiansun}@microsoft.com
Abstract
Deeper neural networks are more difficult to train. We
present a residual learning framework to ease the training
of networks that are substantially deeper than those used
previously. We explicitly reformulate the layers as learn-
ing residual functions with reference to the layer inputs, in-
stead of learning unreferenced functions. We provide com-
prehensive empirical evidence showing that these residual
networks are easier to optimize, and can gain accuracy from
considerably increased depth. On the ImageNet dataset we
evaluate residual nets with a depth of up to 152 layers—8×
deeper than VGG nets [40] but still having lower complex-
ity. An ensemble of these residual nets achieves 3.57% error
on the ImageNet test set. This result won the 1st place on the
ILSVRC 2015 classification task. We also present analysis
on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance
for many visual recognition tasks. Solely due to our ex-
tremely deep representations, we obtain a 28% relative im-
provement on the COCO object detection dataset. Deep
residual nets are foundations of our submissions to ILSVRC
& COCO 2015 competitions
1
, where we also won the 1st
places on the tasks of ImageNet detection, ImageNet local-
ization, COCO detection, and COCO segmentation.
1. Introduction
Deep convolutional neural networks [22, 21] have led
to a series of breakthroughs for image classification [21,
49, 39]. Deep networks naturally integrate low/mid/high-
level features [49] and classifiers in an end-to-end multi-
layer fashion, and the “levels” of features can be enriched
by the number of stacked layers (depth). Recent evidence
[40, 43] reveals that network depth is of crucial importance,
and the leading results [40, 43, 12, 16] on the challenging
ImageNet dataset [35] all exploit “very deep” [40] models,
with a depth of sixteen [40] to thirty [16]. Many other non-
trivial visual recognition tasks [7, 11, 6, 32, 27] have also
1
http://image-net.org/challenges/LSVRC/2015/ and
http://mscoco.org/dataset/#detections-challenge2015.
0 1 2 3 4 5 6
0
10
20
iter. (1e4)
training error (%)
0 1 2 3 4 5 6
0
10
20
iter. (1e4)
test error (%)
56-layer
20-layer
56-layer
20-layer
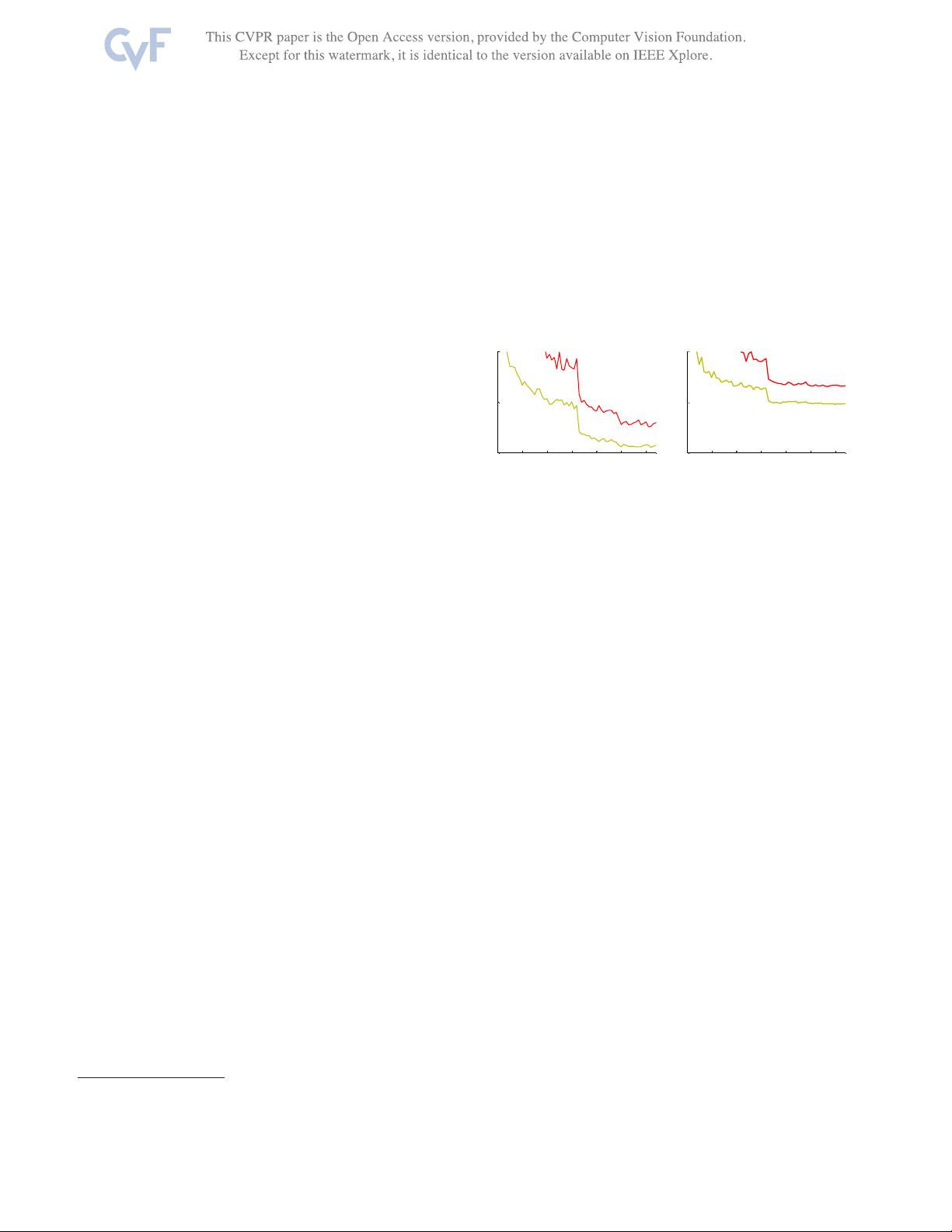
Figure 1. Training error (left) and test error (right) on CIFAR-10
with 20-layer and 56-layer “plain” networks. The deeper network
has higher training error, and thus test error. Similar phenomena
on ImageNet is presented in Fig. 4.
greatly benefited from very deep models.
Driven by the significance of depth, a question arises: Is
learning better networks as easy as stacking more layers?
An obstacle to answering this question was the notorious
problem of vanishing/exploding gradients [14, 1, 8], which
hamper convergence from the beginning. This problem,
however, has been largely addressed by normalized initial-
ization [23, 8, 36, 12] and intermediate normalization layers
[16], which enable networks with tens of layers to start con-
verging for stochastic gradient descent (SGD) with back-
propagation [22].
When deeper networks are able to start converging, a
degradation problem has been exposed: with the network
depth increasing, accuracy gets saturated (which might be
unsurprising) and then degrades rapidly. Unexpectedly,
such degradation is not caused by overfitting, and adding
more layers to a suitably deep model leads to higher train-
ing error, as reported in [10, 41] and thoroughly verified by
our experiments. Fig. 1 shows a typical example.
The degradation (of training accuracy) indicates that not
all systems are similarly easy to optimize. Let us consider a
shallower architecture and its deeper counterpart that adds
more layers onto it. There exists a solution by construction
to the deeper model: the added layers are identity mapping,
and the other layers are copied from the learned shallower
model. The existence of this constructed solution indicates
that a deeper model should produce no higher training error
than its shallower counterpart. But experiments show that
our current solvers on hand are unable to find solutions that
1
770
下载后可阅读完整内容,剩余8页未读,立即下载
相关推荐





twlklove
- 粉丝: 0
 我的内容管理
展开
我的内容管理
展开







最新资源
- C#实现程序A的监控启动机制
- Delphi与C#交互加密解密技术实现与源码分析
- 高效财务发票管理软件
- VC6.0编程实现删除磁盘空白文件夹工具
- w5x00-master.zip压缩包解析:W5200/W5500系列Linux驱动程序
- 数字通信经典教材第五版及其答案分享
- Extjs多表头设计与实现技巧
- VBA压缩包子技术未来展望
- 精选多类型导航菜单,总有您钟爱的一款
- 局域网聊天新途径:Android平台UDP技术实现
- 深入浅出神经网络模式识别与实践教程
- Junit测试实例分享:纯Java与SSH框架案例
- jquery xslider插件实现图片的流畅自动及按钮控制滚动
- MVC架构下的图书馆管理系统开发指南
- 里昂理工学院RecruteSup项目:第5年实践与Java技术整合
- iOS 13.2真机调试包使用指南及安装
