深入解析Spark shuffle过程:从高到低的对比与细节
Spark shuffle是分布式计算框架中的关键环节,它在从一个计算阶段过渡到下一个阶段时起到了数据交换的作用。在JerryLead的这一系列PDF教程中,第四部分深入探讨了Spark的shuffle细节,特别是与Hadoop MapReduce的比较。
首先,从宏观角度看,Spark的shuffle过程与MapReduce相似,但并非完全相同。在Spark中,Mapper(即ShuffleMapTask)将任务的输出分区,每个分区的数据被发送到不同的Reducer。Reducer在内存中临时存储数据,然后在接收到数据后进行聚合操作,最后进行进一步的处理,如一系列的transformation。这个过程可能涉及多个Reducer,包括下一阶段的ShuffleMapTask或ResultTask。
然而,从低级别实现上看,两者有显著差异。Hadoop MapReduce采用排序基础(sort-based)的方法,Mapper首先对数据进行排序,然后Reducer接收并合并这些已排序的数据。这种设计允许处理大规模数据,因为数据可以通过外部排序进行优化。而Spark采用哈希基础(hash-based),主要依赖HashMap进行聚合,避免了预先排序,这使得Spark更灵活但也可能导致性能受制于HashMap的效率。
在Hadoop中,数据处理过程被明确划分为多个步骤,如map、spill(溢写)、merge、shuffle和reduce等,每个阶段都有明确的任务。相比之下,Spark更侧重于Stage和transformation,这些操作通常内嵌在数据流动的逻辑中,没有明显区分的阶段。
此外,从实现角度考虑,MapReduce的顺序执行模式更适合于传统的编程思维,而Spark的设计则更倾向于并行和数据驱动。在Spark中,shuffle和数据的处理是在计算图中自然发生,而不是严格按步骤执行,这要求开发人员理解和处理复杂的依赖关系。
总结来说,Spark的shuffle是一个复杂且关键的组件,它利用内存缓冲和哈希策略实现高效的数据交换,同时保持了灵活性。理解其与MapReduce的区别,对于优化Spark性能和正确使用其分布式计算能力至关重要。通过学习这个系列的PDF,读者将能够深入了解Spark的工作原理和优化技术。
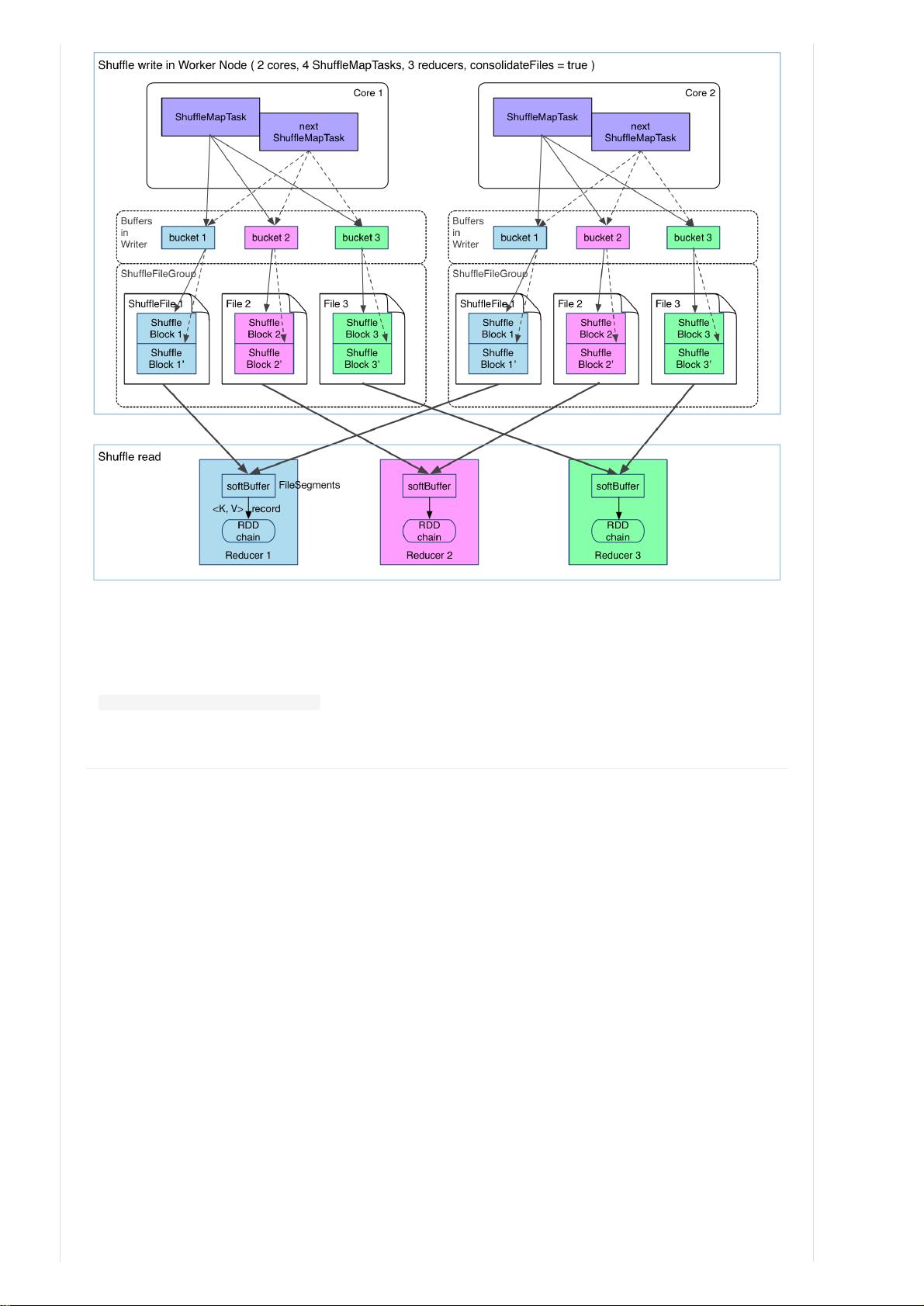
可以明显看出,在一个 core 上连续执行的 ShuffleMapTasks 可以共用一个输出文件 ShuffleFile。先执行完的
ShuffleMapTask 形成 ShuffleBlock i,后执行的 ShuffleMapTask 可以将输出数据直接追加到 ShuffleBlock i 后面,形成
ShuffleBlock i',每个 ShuffleBlock 被称为 FileSegment。下一个 stage 的 reducer 只需要 fetch 整个 ShuffleFile 就行
了。这样,每个 worker 持有的文件数降为 cores * R。FileConsolidation 功能可以通
过spark.shuffle.consolidateFiles=true来开启。
先看一张包含 ShuffleDependency 的物理执行图,来自 reduceByKey:
Shuffle read
剩余11页未读,继续阅读
相关推荐





ppulse
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- DWR中文教程:快速入门与实践指南
- Struts验证机制深度解析
- ArcIMS客户端选择指南:连接器与Viewer解析
- Spring AOP深度解析与实战
- 深入理解Hibernate查询语言HQL
- 改进遗传算法在智能组卷中的应用研究
- Hibernate 3.2.2官方教程:入门与基础配置
- Spring官方参考手册2.0.8版:IoC容器与AOP增强
- ABAP初学者指南:函数与关键功能解析
- ABAP实例详解:报表与对话程序结构与应用
- SAP SmartForm创建实例与测试教程
- JavaScript从入门到精通教程
- .NET 2.0时间跟踪系统设计与实现
- C++标准库教程与参考:Nicolai Josuttis著
- 项目管理流程与项目经理的关键能力
- B/S模式电子购物超市管理系统设计与实现
