
2020/7/29 数学推导+纯Python实现机器学习算法2:逻辑回归
https://mp.weixin.qq.com/s?__biz=MzI4ODY2NjYzMQ==&mid=2247484501&idx=1&sn=e378d74f3c46b402643c4fe13a26f162&chksm=ec3ba13
…
5/12
'dW': dW,
'db': db
}
return cost_list, params, grads
定义对测试数据的预测函数:
def predict(X, params):
y_prediction = sigmoid(np.dot(X, params['W']) + params['b'])
for i in range(len(y_prediction)):
if y_prediction[i] > 0.5:
y_prediction[i] = 1
else:
y_prediction[i] = 0
return y_prediction
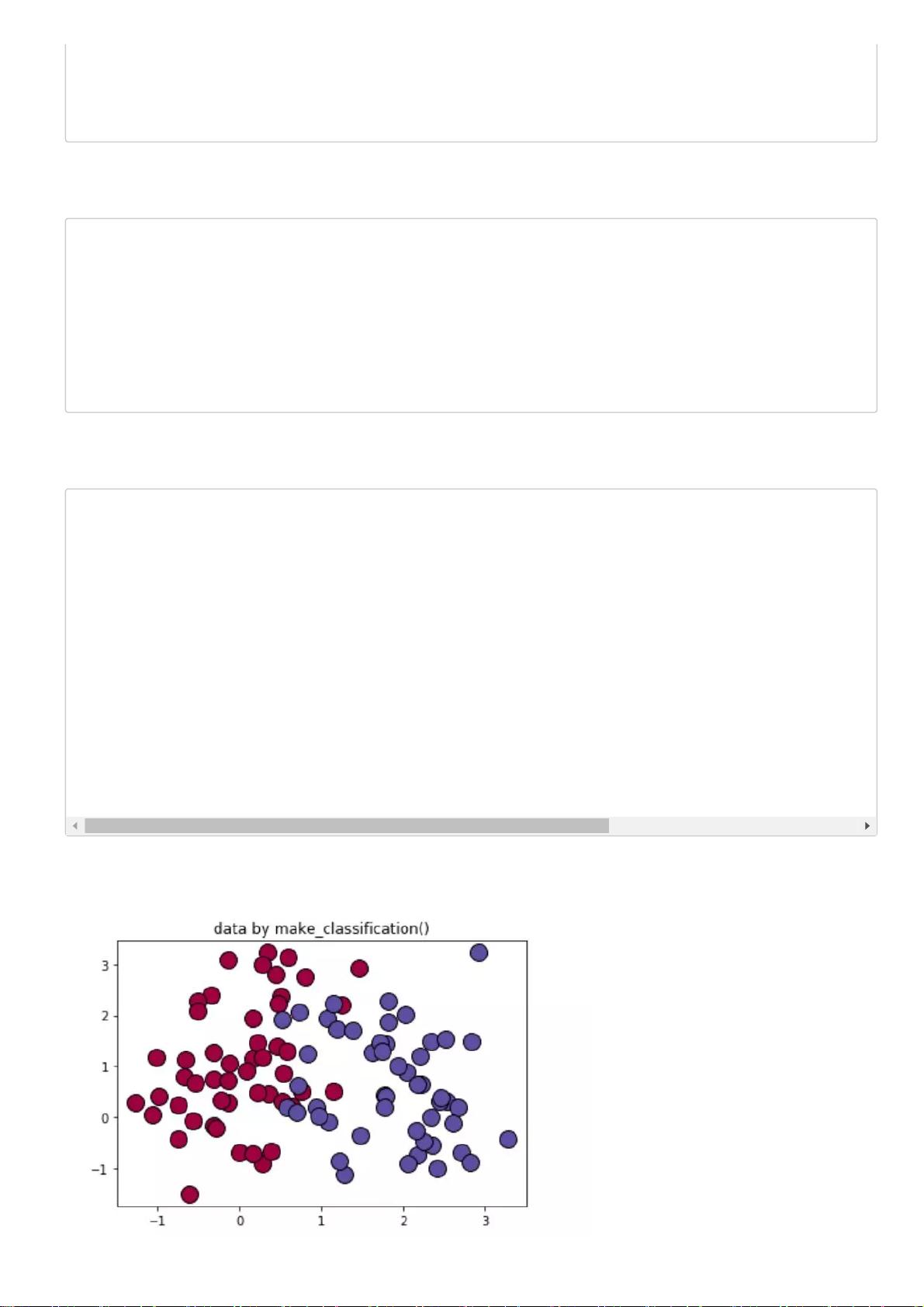
使用 sklearn 生成模拟的二分类数据集进行模型训练和测试:
数据分布展示如下:
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_classification
X,labels=make_classification(n_samples=100, n_features=2, n_redundant=0, n_informative=2
rng=np.random.RandomState(2)
X+=2*rng.uniform(size=X.shape)
unique_lables=set(labels)
colors=plt.cm.Spectral(np.linspace(0, 1, len(unique_lables)))
for k, col in zip(unique_lables, colors):
x_k=X[labels==k]
plt.plot(x_k[:, 0], x_k[:, 1], 'o', markerfacecolor=col, markeredgecolor="k",
markersize=14)
plt.title('data by make_classification()')
plt.show()



剩余251页未读,继续阅读

qq_33980816
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- JDK 17 Linux版本压缩包解压与安装指南
- C++/Qt飞行模拟器教员控制台系统源码发布
- TensorFlow深度学习实践:CNN在MNIST数据集上的应用
- 鸿蒙驱动HCIA资料整理-培训教材与开发者指南
- 凯撒Java版SaaS OA协同办公软件v2.0特性解析
- AutoCAD二次开发中文指南下载 - C#编程深入解析
- C语言冒泡排序算法实现详解
- Pointofix截屏:轻松实现高效截图体验
- Matlab实现SVM数据分类与预测教程
- 基于JSP+SQL的网站流量统计管理系统设计与实现
- C语言实现删除字符中重复项的方法与技巧
- e-sqlcipher.dll动态链接库的作用与应用
- 浙江工业大学自考网站开发与继续教育官网模板设计
- STM32 103C8T6 OLED 显示程序实现指南
- 高效压缩技术:删除重复字符压缩包
- JSP+SQL智能交通管理系统:违章处理与交通效率提升
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


