信源编码与香农编码原理
 已收录资源合集
已收录资源合集
需积分: 0 127 浏览量
更新于2024-08-05
收藏 344KB PDF 举报
"C2 实验三四(预习)1 - 关于通信系统模型与信源编码的介绍"
本文主要探讨了通信系统模型以及信源编码的相关概念,这对于理解和操作网络及前端开发至关重要。首先,通信系统模型是一个基本的框架,用于描述信息从信源到信宿的传输过程。在图1所示的模型中,信源编码位于系统的起始位置,它负责将原始信息转化为适合传输的形式。
信源编码是信息处理的关键步骤,其定义是将信源产生的数据转换为更紧凑的比特流,目的是提高通信效率并减少传输中的冗余。这包括数据压缩和模拟信号的数字化,确保信息能够无失真地被接收和解码。信源编码可以根据不同的标准进行分类,例如,根据信源统计特性的已知与否、失真情况、记忆性等,常见的编码类型包括分组码、非分组码、等长码和变长码。
在无失真信源编码中,统计匹配编码和解除相关性编码是常用的技术,如香农码、哈夫曼码和算术编码。这些编码方法旨在最小化码字的平均长度,同时最大化信息的承载能力。对于允许一定失真的信源编码,矢量量化编码是一个典型的例子,它基于信息率失真函数。
接下来,文章介绍了香农编码,这是基于香农第一定理的一种编码方式。该定理揭示了平均码长与信源符号概率之间的关系,指出存在一种编码方法,使得码字的平均长度接近信息量的极限。香农编码的码字长度lij满足 IntelliJ(ksi) ≤ lij ≤ IntelliJ(ksi) + 1,其中IntelliJ(ksi)是信源符号ksi的信息量, pij 是ksi的出现概率。编码后的平均码长可以由所有符号的概率和其对应的码长计算得出。
预习本实验内容,你需要理解通信系统的基本结构,掌握信源编码的定义、作用和分类,并深入理解香农编码的工作原理和计算公式。这对于后续在网络和前端开发中涉及数据传输和优化的部分将提供理论基础。
1
实验三、实验四
预习材料
一、 信源编码
1.1 通信系统模型
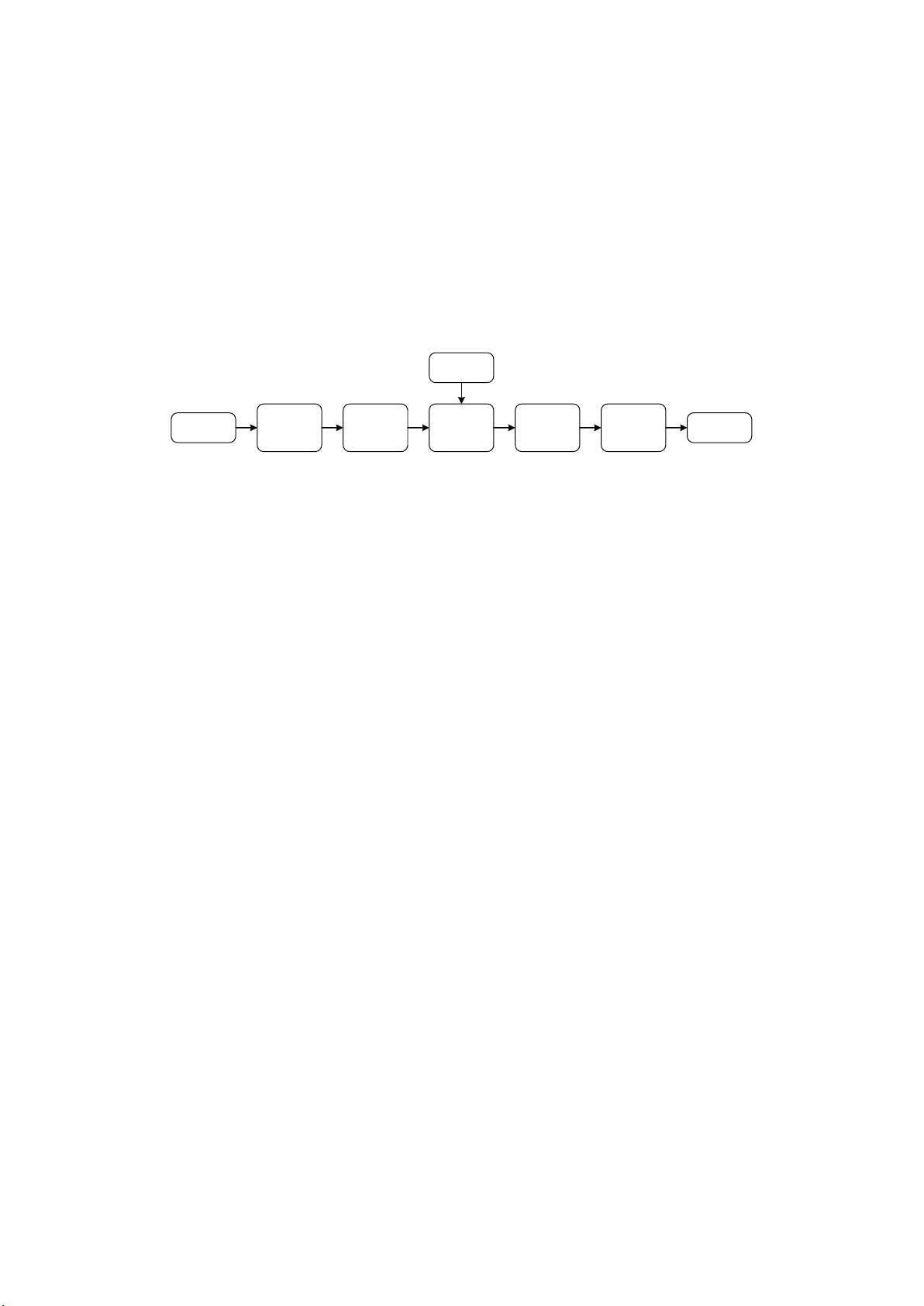
一般的通信系统模型如图 1 所示:
信源
信源
编码
信道
编码
信道
传输
信道
译码
信源
译码
信宿
噪声
图 1 通信系统模型
可以发现,信源编码处于通信系统模型的最前端,是信息进行传递时的第一
个步骤,对信息传输具有重要意义。
1.2 信源编码的定义
在计算机科学和信息论中,信源编码是按照特定的编码机制用比未经编码少
的数据比特(或者其它信息相关的单位)表示信息的过程。信源编码是一种以提
高通信有效性为目的而对信源符号进行的变换,或者说为了减少或消除信源冗余
度而进行的信源符号变换。具体说,就是针对信源输出符号序列的统计特性来寻
找某种方法,把信源输出符号序列变换为最短的码字序列,使后者的各码元所载
荷的平均信息量最大,同时又能保证无失真地恢复原来的符号序列。
1.3 信源编码的作用
信源编码的作用之一是,即通常所说的数据压缩;作用之二是将信源的模拟
信号转化成数字信号,以实现模拟信号的数字化传输。
1.4 信源编码的分类
根据信源的性质进行分类,则有信源统计特性已知或未知、无失真或限定失
真、无记忆或有记忆信源的编码;按编码方法进行分类可分为分组码或非分组码、
等长码或变长码等。然而最常见的是讨论统计特性已知条件下,离散、平稳、无
失真信源的编码,消除这类信源剩余度的主要方法有统计匹配编码和解除相关性
下载后可阅读完整内容,剩余5页未读,立即下载
718 浏览量
363 浏览量
2022-08-08 上传
132 浏览量
206 浏览量
171 浏览量
2023-07-14 上传
2023-06-12 上传
257 浏览量

丽龙
- 粉丝: 29
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页自动刷新工具 v1.1 - 自定义时间间隔与关机
- pt-1.4协程源码深度解析
- EP4CE6E22C8芯片三相正弦波发生器设计与实现
- 高效处理超大XML文件的查看工具介绍
- 64K极限挑战:国际程序设计大赛优秀3D作品展
- ENVI软件全面应用教程指南
- 学生档案管理系统设计与开发
- 网络伪书:社区驱动的在线音乐制图平台
- Lettuce 5.0.3中文API文档完整包下载指南
- 雅虎通Yahoo! Messenger v0.8.115即时聊天功能详解
- 将Android手机转变为IP监控摄像机
- PLSQL入门教程:变量声明与程序交互
- 掌握.NET三层架构:实例学习与源码解析
- WPF中Devexpress GridControl分组功能实例分析
- H3Viewer: VS2010专用高效帮助文档查看工具
- STM32CubeMX LED与按键初始化及外部中断处理教程
