2008年Xiaojin Zhu的半监督学习综述:关键方法与进展
半监督学习(Semi-Supervised Learning Literature Survey)是计算机科学领域的一个重要研究方向,它关注在数据集中只有部分样本有标记的情况下,如何利用未标记数据提高模型的性能和泛化能力。这篇综述由Xiaojin Zhu在2008年撰写,针对的是当时的研究现状和主要方法论,旨在为读者提供一个深入理解半监督学习的框架。
首先,文章提出了半监督学习的常见问题(FAQ),涵盖了为何在数据标记不足时仍能有效学习、以及这种方法的优势和限制。关键在于如何利用未标记数据来克服标记数据的稀疏性。
接下来,讨论了生成模型(Generative Models),包括模型的可识别性(Identifiability)、模型的正确性(Model Correctness)和局部极大值(EMLocal Maxima)问题。这些模型试图通过构建数据的概率分布来理解和预测未标记样本,例如通过潜在类别变量进行聚类和标注。
鱼叉核函数(Fishер kernel)则被用于将半监督学习应用于更偏向于判别任务的学习方法中,这种技术能够将非线性特征转换为线性可分离的表示,从而提高分类性能。
自我训练(Self-Training)是一种常见的半监督策略,它通过初始模型对未标记数据进行预测,然后用这些预测结果作为新的训练样本来迭代提升模型。这种方法强调了模型的自我学习能力。
Co-Training和多视图学习(Co-Training and Multi-view Learning)是另一种协作学习的方法,通过不同视角对同一数据集进行分析,以增强模型的鲁棒性和准确性。Co-Training关注两个或多个互相独立的特征子集之间的联合学习,而Multi-view Learning则更广泛地探索数据的不同表现形式。
避免在稠密区域修改模型(Avoiding Changes in Dense Regions)是半监督学习中的一个重要挑战,文章探讨了如何在保持模型稳定的同时,有效地利用未标记数据。这包括转导支持向量机(Transductive SVMs,S3VMs)、高斯过程(Gaussian Processes)、信息正则化(Information Regularization)、熵最小化(Entropy Minimization)等策略,以及与图模型的关联。
图基方法(Graph-Based Methods)是半监督学习的另一大分支,它将数据视为图结构,通过节点间的相似性或关系进行建模。这些方法涉及图的正则化(如Mincut、Markov随机场、Gaussian随机场和Harmonic Functions)、局部和全局一致性、Tikhonov正则化、Manifold Regularization,以及基于谱理论的图核(Graph Kernels from the Spectrum of Laplacian)和谱图转换器(Spectral Graph Transducer)。
总结来说,这篇综述深入剖析了半监督学习的各种核心方法和技术,展示了在缺乏大量标记数据的情况下,如何巧妙利用未标记数据进行模型训练和优化,是研究者和实践者理解这一领域的重要参考资料。
−6 −4 −2 0 2 4 6
−6
−4
−2
0
2
4
6
Class 1
Class 2
−6 −4 −2 0 2 4 6
−6
−4
−2
0
2
4
6
−6 −4 −2 0 2 4 6
−6
−4
−2
0
2
4
6
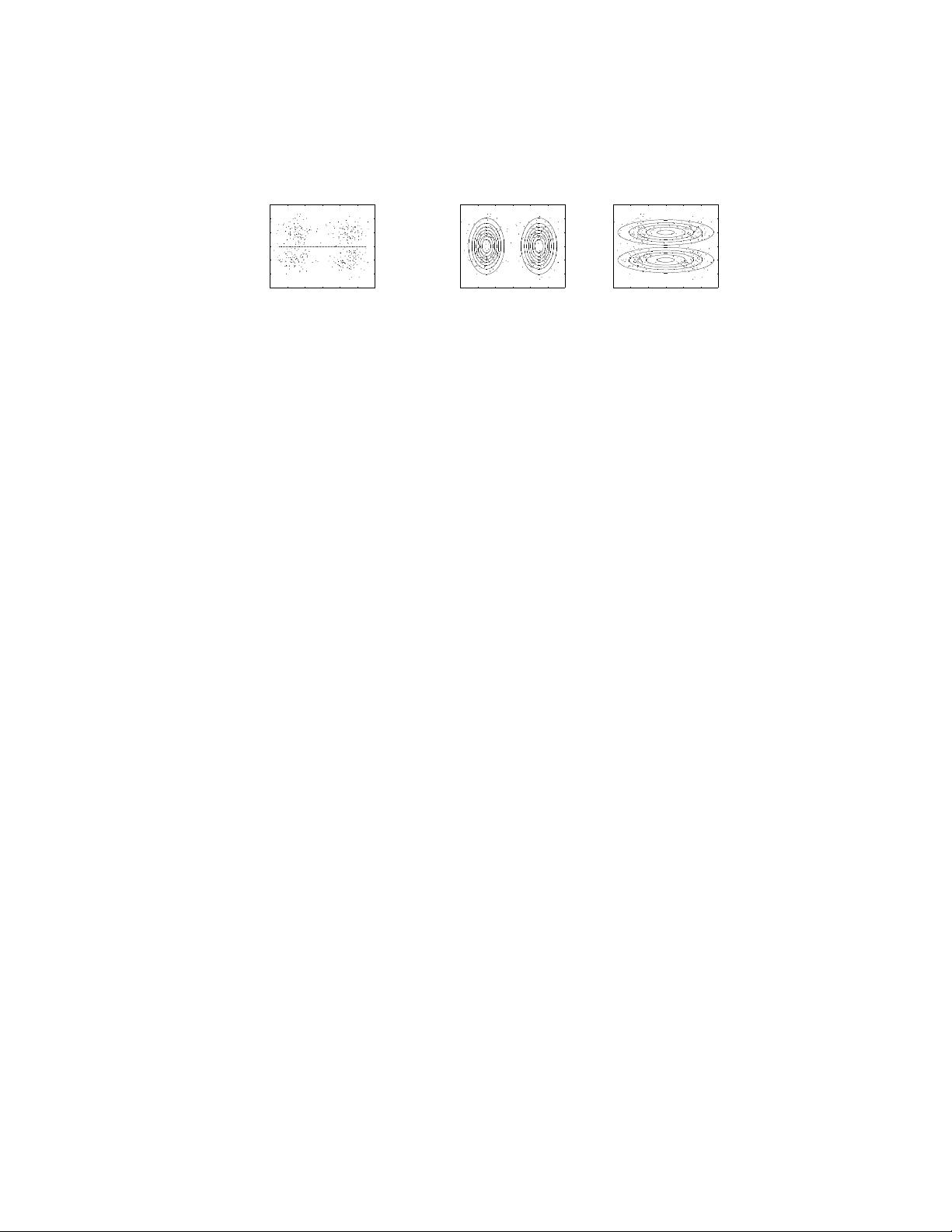
(a) Horizontal class separation (b) High probability (c) Low probability
Figure 3: If the model is wrong, higher likelihood may lead to lower classification
accuracy. For example, (a) is clearly not generated from two Gaussian. If we insist
that each class is a single Gaussian, (b) will have higher probability than (c). But
(b) has around 50% accuracy, while (c)’s is much better.
2.3 EM Local Maxima
Even if the mixture model assumption is correct, in practice mixture components
are identified by the Expectation-Maximization (EM) algorithm (Dempster et al.,
1977). EM is prone to local maxima. If a local maximum is far from the global
maximum, unlabeled data may again hurt learning. Remedies include smart choice
of starting point by active learning (Nigam, 2001).
2.4 Cluster-and-Label
We shall also mention that instead of using an probabilistic generative mixture
model, some approaches employ various clustering algorithms to cluster the whole
dataset, then label each cluster with labeled data, e.g. (Demiriz et al., 1999) (Dara
et al., 2002). Although they can perform well if the particular clustering algorithms
match the true data distribution, these approaches are hard to analyze due to their
algorithmic nature.
2.5 Fisher kernel for discriminative learning
Another approach for semi-supervised learning with generative models is to con-
vert data into a feature representation determined by the generative model. The new
feature representation is then fed into a standard discriminative classifier. Holub
et al. (2005) used this approach for image categorization. First a generative mix-
ture model is trained, one component per class. At this stage the unlabeled data can
be incorporated via EM, which is the same as in previous subsections. However
instead of directly using the generative model for classification, each labeled ex-
ample is converted into a fixed-length Fisher score vector, i.e. the derivatives of log
likelihood w.r.t. model parameters, for all component models (Jaakkola & Haus-
sler, 1998). These Fisher score vectors are then used in a discriminative classifier
10


剩余59页未读,继续阅读
1847 浏览量
118 浏览量
222 浏览量
225 浏览量
169 浏览量
103 浏览量
216 浏览量

ght1102
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Socioleads-crx: 社交媒体潜在客户监控扩展
- LMJDropdownMenu 3.0.0:高效易用的下拉菜单控件
- VirtualTreeView 7.4: Delphi 10.4的VCL控件发布
- JavaScript 实现的 Jump61 游戏解析
- 结构力学教程(II):全面解析与应用指南
- PHP实现ZIP文件解压缩功能的类
- Java封装核心库的Go语言应用
- HTML模板新手快速入门指南
- Android Studio中AsycTask基础实例源码分享
- 探索移动世界的无限可能
- 掌握Python爬虫:封装xpath与request库的实践
- 奥斯陆大学INF5750项目:FacilityRegistryApp应用程序开发
- 51单片机实现智能电子琴设计与应用
- VC实现简易邮件收发程序示例
- hapi-browser-log插件:捕获并记录客户端JavaScript错误
- Syn.Speech:适用于Mono和.NET的高效语音识别引擎
