优化3D堆叠内存架构:提升多核处理器性能
需积分: 9 26 浏览量
更新于2024-10-28
收藏 594KB PDF 举报
"这篇论文探讨了3D堆叠内存架构在多核处理器中的应用,以优化性能。通过将内存直接堆叠在微处理器上,3D集成显著减少了两者之间的信号延迟。作者Gabriel H. Loh来自佐治亚理工学院计算学院。文中提到,之前的研究所关注的是2D DRAM的组织结构,而本文则研究了更激进的3D DRAM设计,以充分利用3D堆叠提供的额外带宽和晶体管数量。模拟结果显示,对3D-DRAM组织结构进行简单改进后,在四核处理器上运行内存密集型多程序工作负载时,性能可提升1.75倍。这种性能提升使得L2缓存的错误处理成为新的瓶颈,为此,作者提出了一种结合Vector Bloom Filter和动态MSHR容量调整的解决方案,以构建可扩展的L2缓存管理系统,解决这一问题。"
在多核处理器的设计中,3D堆叠内存架构是一个重要的优化方向。传统的2D内存组织结构在处理高速数据传输时存在延迟问题,而3D堆叠技术通过垂直堆叠内存和处理器,显著减少了数据传输的线延迟,从而提高了整体系统性能。论文指出,尽管已有研究考察了2D DRAM在3D堆叠中的应用,但并未充分挖掘3D堆叠带来的潜力。
本研究深入探索了更先进的3D DRAM组织策略,这些策略能够更好地利用3D堆叠所提供的die-to-die带宽以及额外的晶体管资源。通过这些改进,研究人员观察到在特定工作负载下,内存系统的性能有了显著提升,达到约1.75倍的加速效果。然而,这样的性能提升也暴露出一个新的问题:L2缓存的错误处理(L2 MisHandling Architecture,MHA)成为了系统性能的新瓶颈。
为了解决这个问题,作者引入了一个名为Vector Bloom Filter的数据结构,并结合动态MSHR(Miss Status Holding Register)容量调整机制。Vector Bloom Filter是一种高效的概率数据结构,用于近似检查元素是否存在,而动态MSHR调整则可以优化缓存响应时间。将这两者结合,能够在不牺牲太多性能的情况下,有效管理L2缓存,提高系统的整体效率和可扩展性。
3D堆叠内存架构为多核处理器的性能优化提供了新的思路,通过改进3D DRAM的组织方式和采用创新的数据结构与管理策略,可以克服现有技术的限制,进一步提升系统性能并解决由此产生的新挑战。这一研究对于未来高性能计算和数据中心的设计具有重要参考价值。
Layer 1
Layer 2
Layer 3
Layer 4
Through Silicon
Vias (TSVs)
Metal Layers
Transistors
10−50um
800−1000um
Bulk Silicon
Heat Sink
< 10um
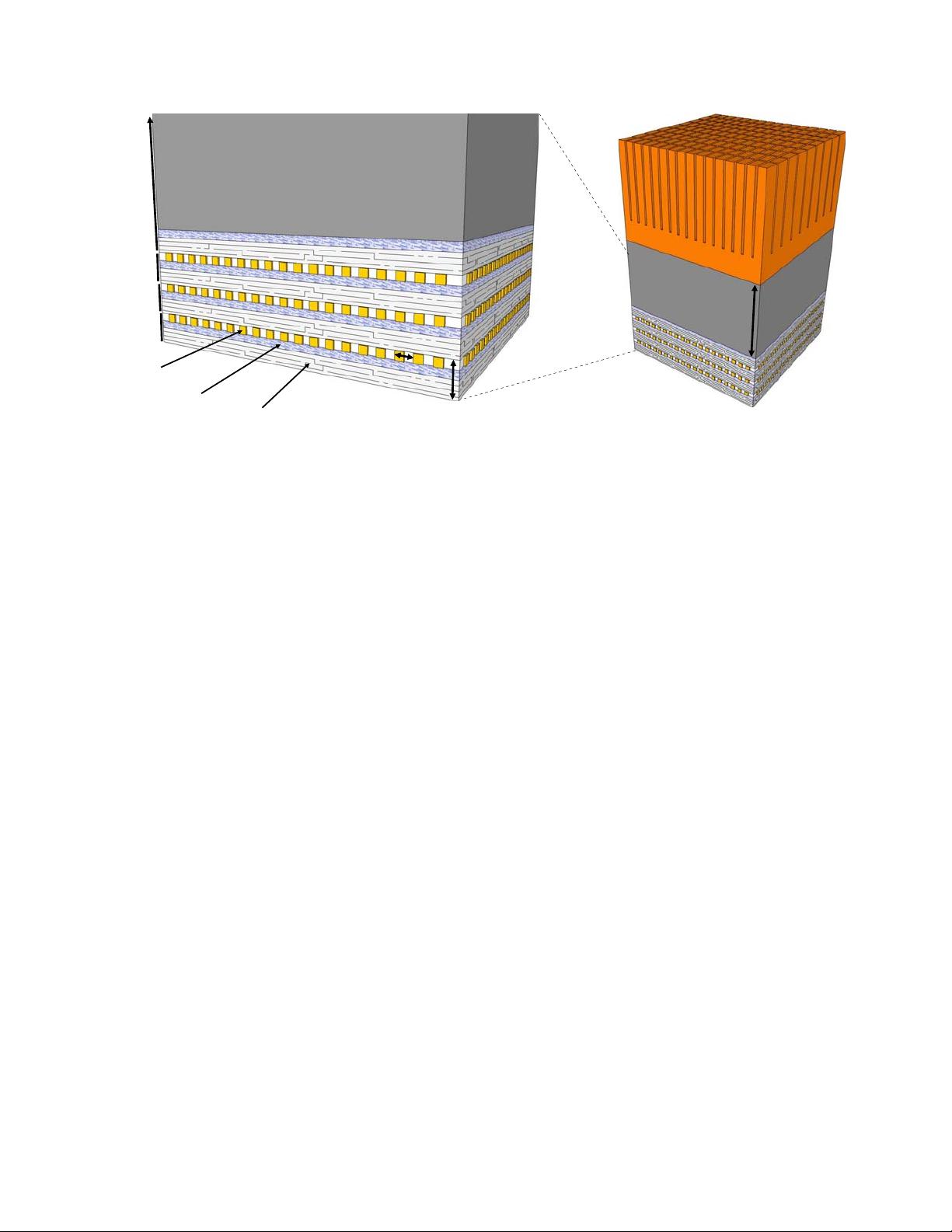
Figure 2. Cross-sectional view of 3D-stacked dies with a face-to-back topology (not drawn to scale).
typical metal routes, they are very short since each wafer
is thinned to only tens of microns. The TSVs have been
reported to have pitches of only 4-10μm [14]. Even at the
high-end with a 10μm TSV-pitch, a 1024-bit bus would only
require an area of 0.32mm
2
. To put that in perspective, a
1cm
2
chip could support over three hundred of these 1Kb
buses. For the purposes of stacking DRAM, the TSV size
and latency will likely not be a limiting factor for several
generations.
2.3. 3D-Stacked DRAM
Previous studies have already started exploring the perfor-
mance benefits of using 3D integration to stack main mem-
ory on top of a processor. Figure 3(a) shows a tradi-
tional 2D processor core with multiple layers of 3D-stacked
DRAM [20, 24, 26]. The 3D TSVs implement a vertical bus
across the layers to connect the DRAM layers to the proces-
sor core. Independent of the required latencies, the topol-
ogy and overall architecture of these processor-memory 3D
organizations are no different than that used in traditional
off-chip memories. Liu et al. [24] and Kgil et al. [20] do
consider using the dense TSV interface to implement wider
buses, which are traditionally limited by pin-count, but they
do not observe a large performance benefit due to the small
sizes of their workloads and critical-word-first delivery of
data from memory.
The previous approaches do not fully exploit 3D stack-
ing technology because the individual structures are all still
inherently two-dimensional. Tezzaron Corporation has an-
nounced “true” 3D DRAMs where the individual bitcell ar-
rays are stacked in a 3D fashion [38, 39]. Figure 3(b) shows
the overall organization. The top N layers consist of the
stacked DRAM bitcells; this stacked organization reduces
the lengths of internal buses, wordlines and bitlines, which
in turn reduces the access latency of the memory. The bot-
tom layer implements the various control and access circuits,
such as the row decoder, sense amplifiers, row buffers and
output drivers. The advantage of isolating the peripheral
circuitry to a separate, dedicated layer is that different pro-
cess technologies can be incorporated. The DRAM bitcells
are all implemented in a traditional NMOS technology opti-
mized for density, whereas the peripheral circuits are imple-
mented on a CMOS layer optimized for speed. The combi-
nation of reducing bitline capacitance and using high-speed
logic provides a 32% improvement in memory access time
(t
RAS
) for a five-layer DRAM (four layers of memory plus
one layer of logic). Note that this latency reduction is for
the memory array access itself, and this is additive with any
benefits due to placing the memory closer to the processor.
2.4. Methodology and Assumptions
In this section, we briefly describe the processor microar-
chitecture, memory system and 3D integration assumptions
that we use. We base our baseline processor on the Intel
45nm “Penryn” model [19], detailed in Table 1, extended
to a quad-core configuration. We use the SimpleScalar
toolset for the x86 ISA for performance evaluation [3], and
we extended it to perform cycle-level modeling of a multi-
core processor. The simulator models the contention for
cache/memory buses, MSHR capacity, traffic due to write-
back and prefetches, and memory controller request queue
capacity. For the DRAM, we model the low-level tim-
ing including precharge delays (including when it can be
overlapped with other commands), different timings for row
buffer hits and misses, and the effects of periodic DRAM
refreshing. We assume a memory controller implementation
that attempts to schedule accesses to the same row together
to increase row buffer hit rates [34]. For the off-chip DRAM,
we assume a refresh period of 64ms, and the on-chip ver-
455455
剩余11页未读,继续阅读
2018-09-01 上传
2021-03-10 上传
2021-07-12 上传
2021-07-06 上传
2021-03-04 上传
2021-07-05 上传
2021-03-27 上传
2021-07-12 上传
2021-05-31 上传

li18j_p
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
