Apache Kafka的Exactly Once语义详解
版权申诉
140 浏览量
更新于2024-06-21
收藏 1.1MB PDF 举报
"深入理解Apache Kafka的精确一次语义"
在Apache Kafka中,引入精确一次语义(Exactly-Once Semantics)是一项重要的改进,它旨在解决消息传递中的重复问题,从而提高数据处理的准确性和一致性。Kafka最初提供的是至少一次(At-Least-Once)的语义,保证每个消息至少被处理一次,但这种语义可能导致数据重复。本篇文档由Jason Gustafson、Apurva Mehta、Guozhang Wang和Sriram Subramaniam共同撰写,由Matthias J. Sax进行阐述,深入探讨了Kafka的新特性及其使用方法。
首先,Kafka原有的交付语义是分区内的顺序且至少一次的交付。这意味着消息将按照它们在生产者中发送的顺序被消费者读取,但因为生产者重试可能导致消息被多次处理,从而出现重复。例如,在与Apache Spark结合进行流处理时,通常采用读-处理-写模式,这就存在潜在的重复写入风险。
文档通过一个示例详细展示了重复写入的过程:生产者向经纪人(Broker)发送消息(k, v),经纪人将消息追加到主题分区中,并返回确认(ack)。然而,如果在网络通信中发生故障,生产者可能没有接收到确认,从而重试发送,导致同一消息被多次写入。
为了解决这个问题,Kafka引入了精确一次语义。这一特性通过协调生产者、消费者以及Kafka自身的行为,确保每个消息只被处理一次,同时保持顺序性。实现这一语义的关键技术包括Idempotent Producer(幂等生产者)和Transactional API(事务API),它们允许生产者执行跨多个分区的一致操作,且在失败后能够恢复到一致状态。
Idempotent Producer使得即使在重试情况下,生产者发送的消息也不会产生重复。幂等性意味着无论消息发送多少次,其结果都是一样的。而Transactional API则允许用户定义一系列操作为一个事务,要么全部成功,要么全部回滚,确保了数据的一致性。
使用这些新特性时,开发者需要注意配置和编程模式。例如,启用幂等性生产者需要设置适当的配置项,并确保消息的唯一标识符在重试时不改变。使用事务API时,需要正确管理事务边界,避免死锁或资源耗尽。
总结,Apache Kafka的精确一次语义是为了解决至少一次语义带来的重复数据问题,通过幂等性生产者和事务API提供了强一致性保证。这使得Kafka更适用于需要严格数据一致性的场景,如金融交易、审计日志记录等。正确理解和应用这些新特性,将有助于构建更可靠和精确的数据处理系统。
6
Confidential
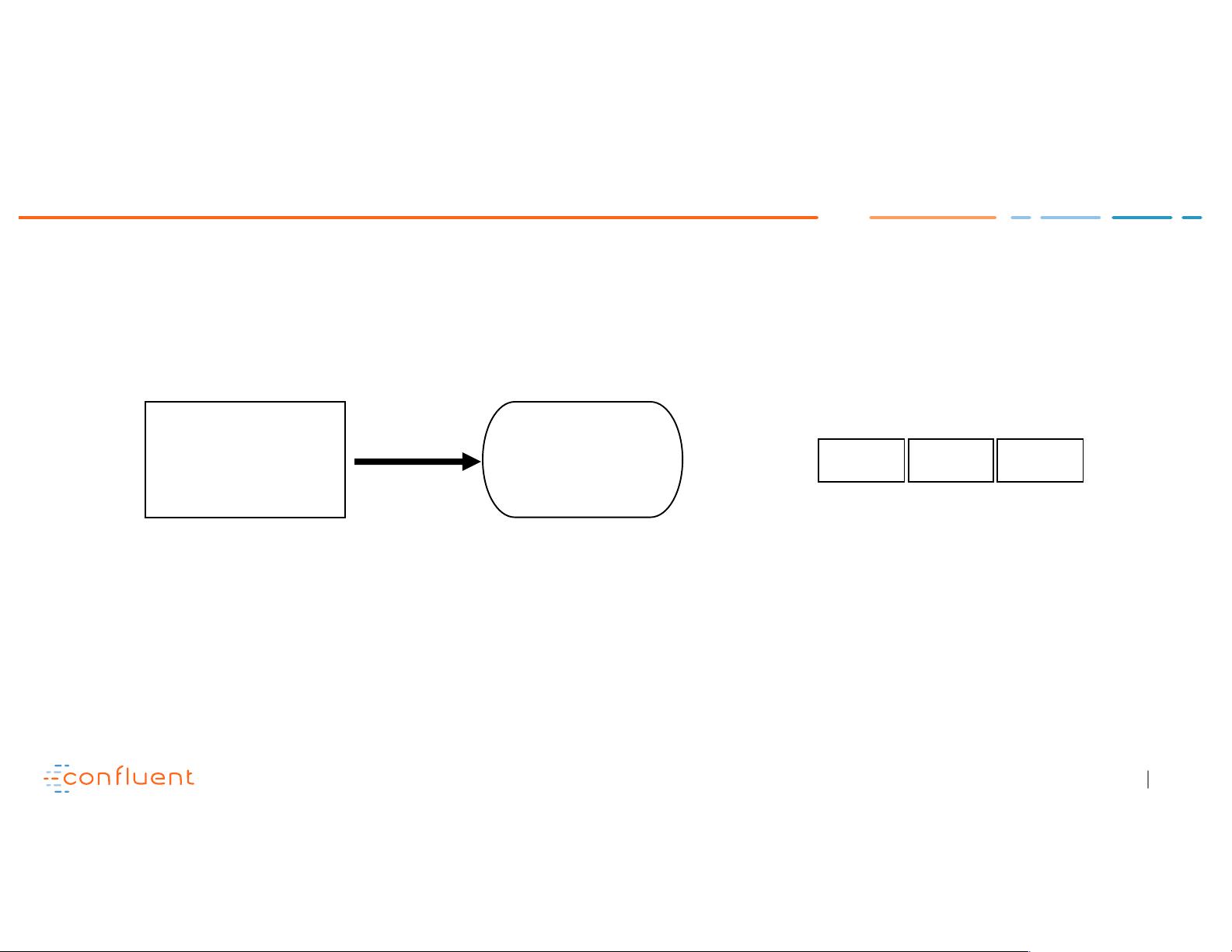
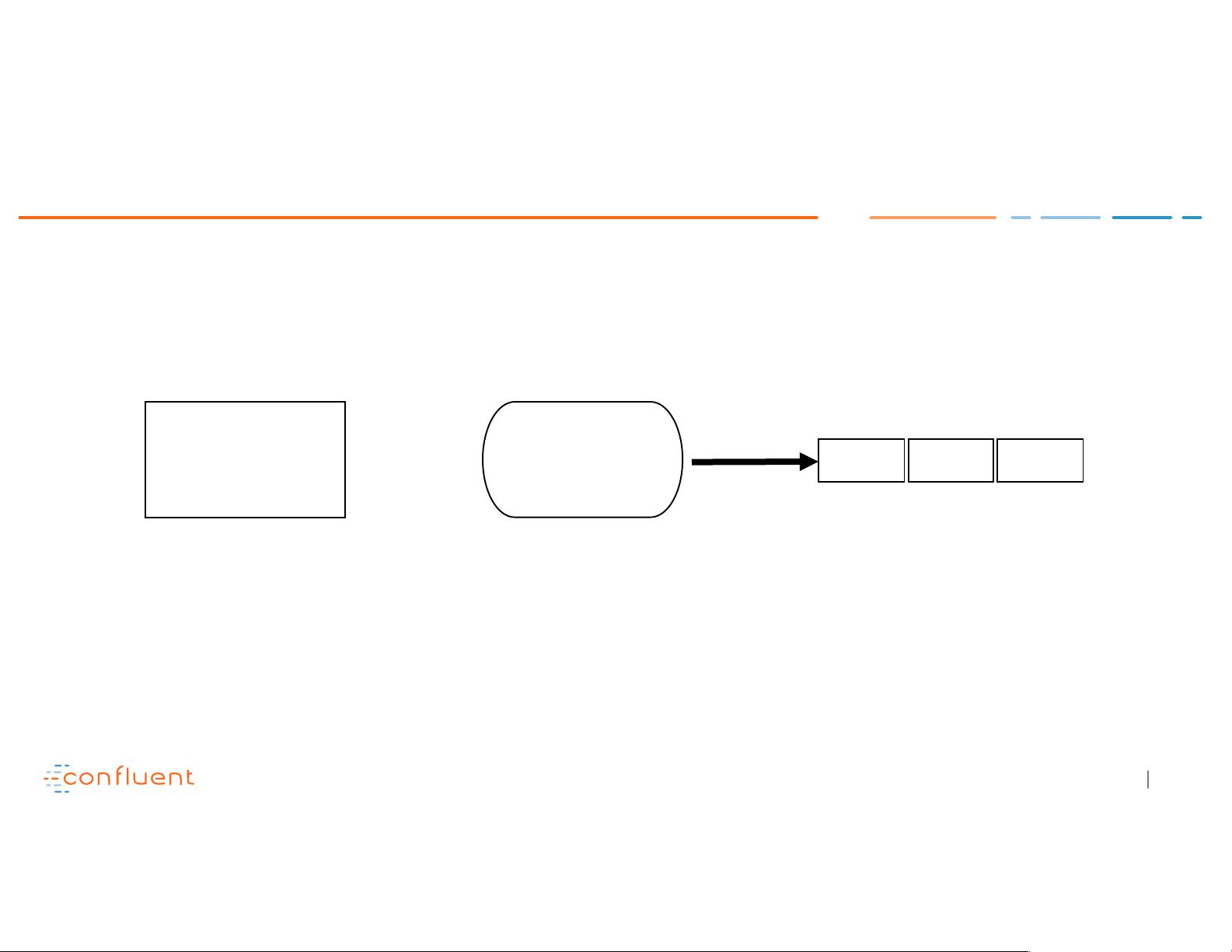
Example: duplicate write
Producer Broker
Topic Partition
send (k,v)
剩余32页未读,继续阅读
410 浏览量
2025-01-07 上传
2025-01-07 上传
2025-01-07 上传

weixin_40191861_zj
- 粉丝: 87
- 资源: 1万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- 100课AE系统教程,让你的视频玩转特效功能41-80.rar
- b7a-community-call-samples
- tinykv:基于TiKV模型构建分布式键值服务的课程
- 经典企业电脑模板
- 行业-强化练习-言语3+乌米+(讲义+笔记).rar
- libwdi:USB 设备的 Windows 驱动程序安装程序库-开源
- jQuery版本
- RBAP-Wiki:这是Roblox游戏的官方维基,称为“随机建筑和零件”。
- 字模提取软件合集有问题可以问我
- alien-filter
- pyslam:pySLAM在Python中包含一个单眼视觉Odometry(VO)管道。 它支持基于深度学习的许多现代本地功能
- SpringBoot之rpm打包文档.rar
- 距离标度:一种改进基于密度聚类的距离标度方法-matlab开发
- yarl:另一个URL库
- 信息系统项目管理师论文真题范文汇总.zip
- ICLR 2021上关于【NLP】主题的论文
