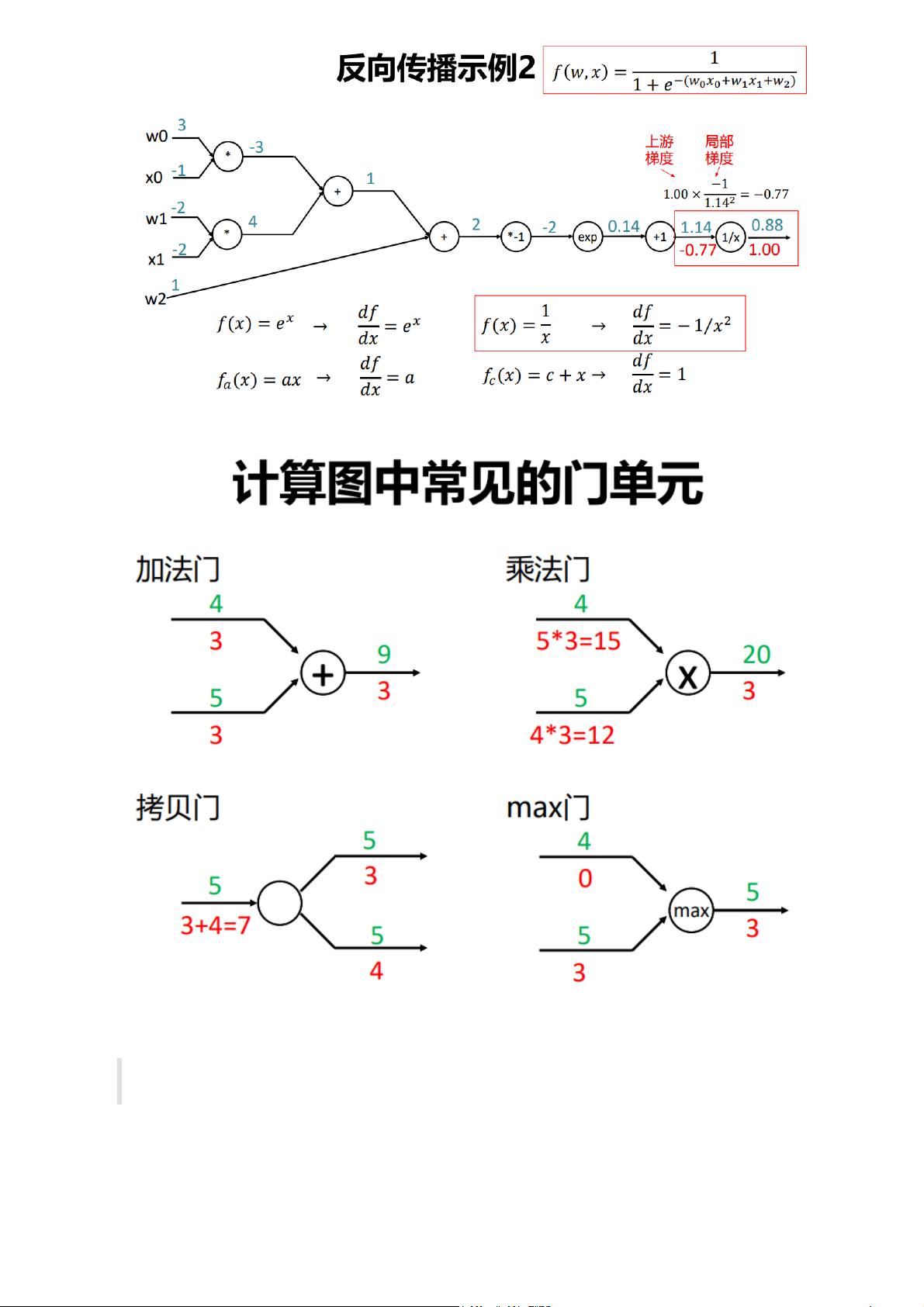
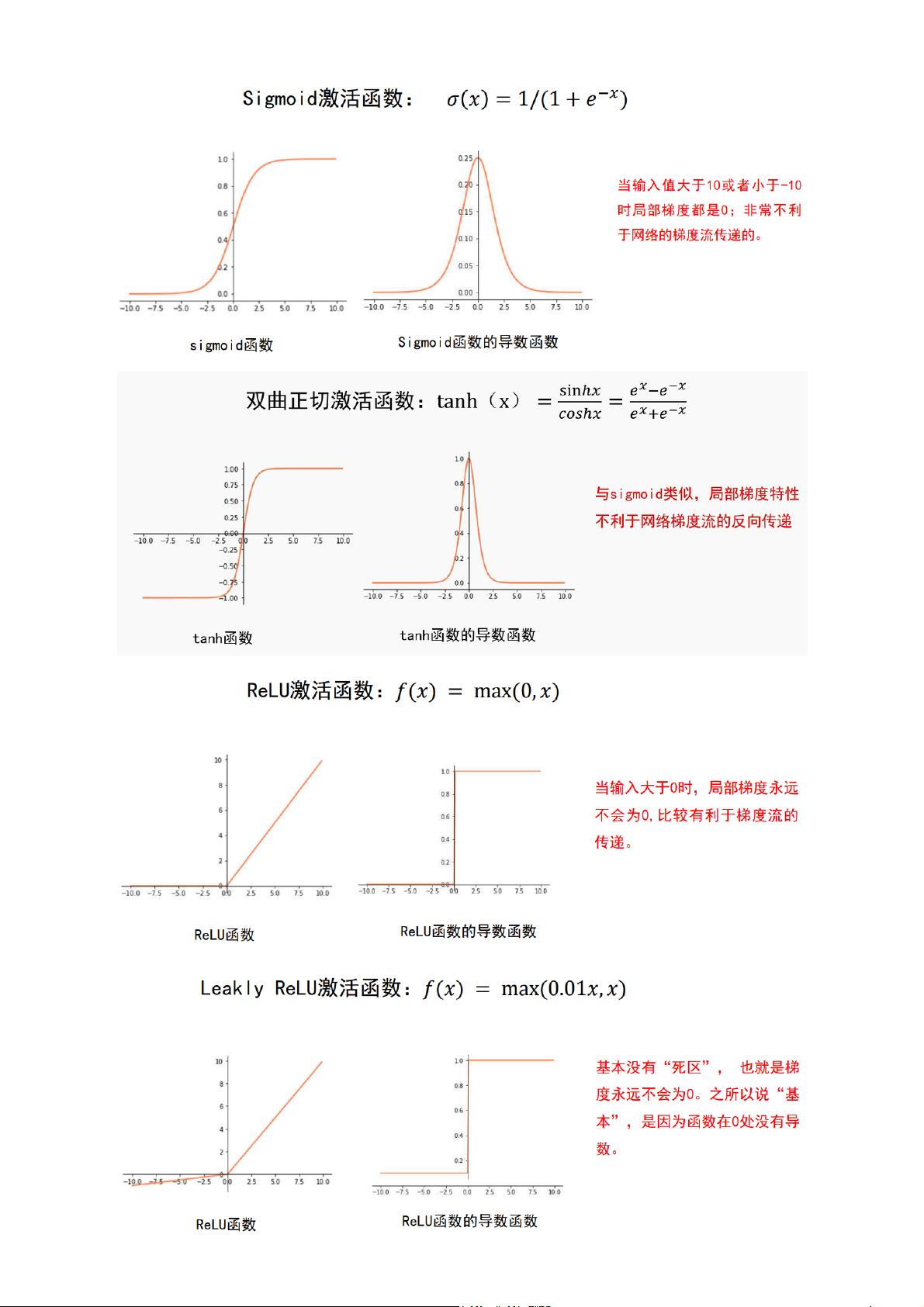
Mask-RCNN详解:实例分割与边界框增强的深度解析
版权申诉
本文是一篇深入解读Mask-RCNN技术的详细笔记,Mask-RCNN是计算机视觉领域的一个重要里程碑,它在实例分割任务中展现出了强大的性能。该模型起源于Faster R-CNN的扩展,旨在同时实现目标检测和高质量实例分割。
首先,Mask-RCNN的核心在于其实例分割能力。它解决了目标检测中的一个挑战,即不仅识别出图像中的物体,还能为每个物体生成一个像素级别的分割掩码,这对于诸如行人检测、车辆识别等场景尤其重要。相比于传统的目标检测模型如Faster R-CNN,Mask-RCNN新增了一个专门用于预测Mask的分支,每个Region of Interest (RoI) 都会得到一个独立的Mask预测,这确保了实例间的区分性。
在架构方面,Mask-RCNN通过RoIAlign层替代了RoIPool,解决了原始RoIPool可能导致的像素信息丢失问题,保持了空间位置信息的精确性,从而提高了分割效果。此外,Mask-RCNN采用独立预测每个类别的二元Mask,避免了类别之间的竞争,并依赖于网络的分类分支结果,提高了分割的精度。
Mask-RCNN的成功体现在多个数据集上的优异表现,如COCO数据集,它不仅在目标检测任务中表现出色,还在人体姿态估计中通过将关键点转换为one-hot二元掩码,实现了更为精细的定位。同时,模型在GPU上的运行效率也得到了良好的保证。
相关工作部分介绍了R-CNN系列的发展,从最初的候选区域提取和独立处理,到Faster R-CNN引入区域提议网络(RPN)的注意力机制,再到Mask-RCNN的实例分割提升。这些模型的进步展示了计算机视觉技术在目标检测领域的逐步演进。
Mask-RCNN作为一个深度学习模型,不仅革新了目标检测的方法,还推动了实例分割技术的发展,成为了现代计算机视觉研究的重要组成部分。通过理解Mask-RCNN的工作原理、结构优化和性能优势,可以更好地应用于实际场景,如自动驾驶、医疗影像分析等领域。



点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-05-10 上传
2023-08-23 上传
2021-11-15 上传
2022-11-11 上传
2022-06-22 上传
2022-06-20 上传


LetsonH
- 粉丝: 815
- 资源: 36
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
