




SELF-INSTRUCT:提升预训练语言模型的指令理解能力
需积分: 1 16 浏览量
更新于2024-06-17
收藏 4.13MB PDF 举报
"self-instruct 自动生成指令数据是 ACL2023 上提出的一种新框架,旨在提高预训练语言模型的指令执行能力。该框架通过利用模型自身的生成能力,自动生成指令、输入样本和输出样本,然后进行过滤和优化,用于微调原始模型,从而在没有大量人类编写指令数据的情况下也能提升模型的泛化能力。实验结果显示,该方法能显著提升模型在新任务上的零样本泛化性能。"
在当前的自然语言处理领域,大型的“指令调优”语言模型(如经过微调以响应指令的模型)已经展示出在零样本情况下处理新任务的出色能力。然而,这些模型严重依赖于人类编写的指令数据,而这些数据在数量、多样性和创造性上往往有限,这限制了模型的泛化性能。SELF-INSTRUCT 框架就是为了克服这一挑战而提出的。
SELF-INSTRUCT 的工作流程如下:首先,它使用一个预训练的语言模型生成一系列指令、输入和期望的输出样本。这个过程是自动化的,允许模型在无监督的环境中自我学习和创造任务描述。接着,系统会执行一个过滤步骤,剔除无效或相似的生成样本,确保用于后续微调的数据质量。最后,这些经过筛选的指令和样例被用来微调原始的预训练模型,增强其理解并执行自动生成指令的能力。
实验中,研究人员将该方法应用于基础版的 GPT3 模型。结果显示,通过 SELF-INSTRUCT 方法,模型在新任务上的绝对性能提升了 33%,这表明这种方法对于提升模型的指令理解和执行效率具有显著效果。此外,这种方法的创新之处在于其自我强化的特性,可以利用模型自身的生成能力来不断优化其自身,无需大量的人工标注数据,降低了对昂贵且耗时的人工干预的依赖。
SELF-INSTRUCT 为提升语言模型的零样本学习和泛化能力提供了一个有效且高效的新途径,尤其在面对多样化和复杂任务时,这种自动化的指令生成和微调策略有望进一步推动人工智能在理解和执行任务方面的进步。
write
give
find
create
make
describe
design
generate
classify
have
explain
tell
identify
output
predict
detect
function
essay
letter
paragraph
example
list
set
advice
word
number
sentence
way
program
list
algorithm
function
list
story
sentence
program
situation
person
process
time
system
game
algorithm
structure
list
number
sentence
series
sentence
sentiment
article
text
list
array
coin
set
difference
concept
story
joke
sentiment
topic
number
word
sentiment
sarcasm
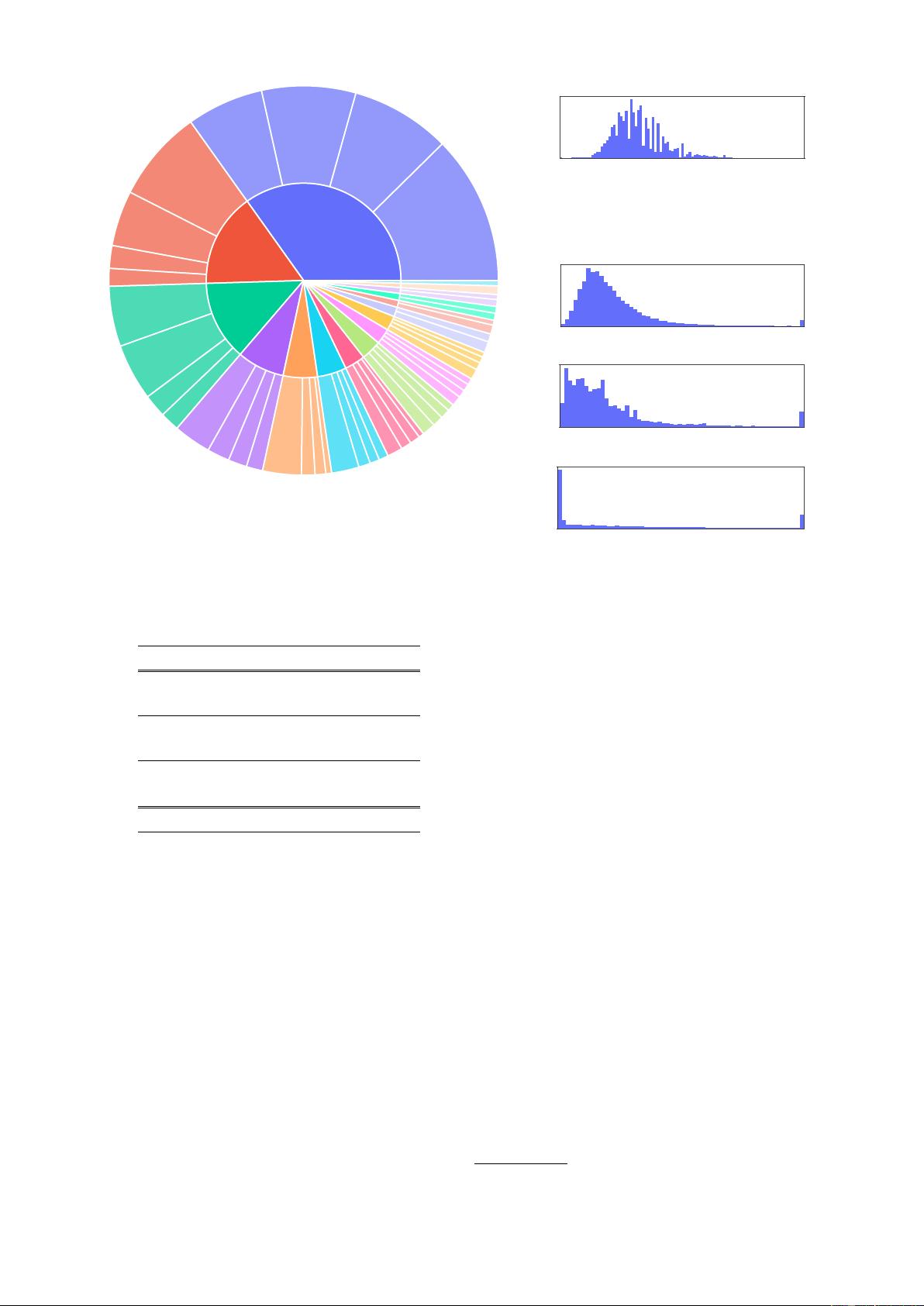
Figure 3: The top 20 most common root verbs (inner circle) and
their top 4 direct noun objects (outer circle) in the generated
instructions. Despite their diversity, the instructions shown here
only account for 14% of all the generated instructions because
many instructions (e.g., “Classify whether the user is satisfied
with the service.”) do not contain such a verb-noun structure.
0 0.2 0.4 0.6 0.8 1
0
1000
2000
3000
ROUGE-L Overlap with the Most Similar Seed Instruction
# Instructions
Figure 4: Distribution of the ROUGE-L scores
between generated instructions and their most
similar seed instructions.
10 20 30 40 50 60
0
2000
4000
6000
Instruction Length
# Instructions
10 20 30 40 50 60
0
1000
2000
3000
Input Length
# Inputs
10 20 30 40 50 60
0
10k
20k
30k
Onput Length
# Onputs
Figure 5: Length distribution of the generated
instructions, non-empty inputs, and outputs.
Quality Review Question Yes %
Does the instruction
describe a valid task?
92%
Is the input appropriate
for the instruction?
79%
Is the output a correct and acceptable
response to the instruction and input?
58%
All fields are valid 54%
Table 2: Data quality review for the instruction, input,
and output of the generated data. See Table 10 and
Table 11 for representative valid and invalid examples.
4 Experimental Results
We conduct experiments to measure and compare
the performance of models under various instruc-
tion tuning setups. We first describe our models
and other baselines, followed by our experiments.
4.1 GPT3
SELF-INST
: finetuning GPT3 on its
own instruction data
Given the instruction-generated instruction data, we
conduct instruction tuning with the GPT3 model
itself (“davinci” engine). As described in §2.3, we
use various templates to concatenate the instruction
and input, and train the model to generate the output.
This finetuning is done through the OpenAI fine-
tuning API.
8
We use the default hyper-parameters,
except that we set the prompt loss weight to 0, and
we train the model for 2 epochs. We refer the reader
to Appendix A.3 for additional finetuning details.
The resulting model is denoted by GPT3
SELF-INST
.
4.2 Baselines
Off-the-shelf LMs. We evaluate T5-LM (Lester
et al., 2021; Raffel et al., 2020) and GPT3 (Brown
et al., 2020) as the vanilla LM baselines (only pre-
training, no additional finetuning). These baselines
will indicate the extent to which off-the-shelf LMs
are capable of following instructions naturally im-
mediately after pretraining.
Publicly available instruction-tuned models.
T
0
and T
𝑘
-INSTRUCT are two instruction-tuned
models proposed in Sanh et al. (2022) and Wang
et al. (2022), respectively, and are demonstrated
to be able to follow instructions for many NLP
tasks. Both of these models are finetuned from
the T5 (Raffel et al., 2020) checkpoints and are pub-
licly available.
9
For both of these models, we use
8
See OpenAI’s documentation on finetuning.
9
T0 is available at here and T𝑘-INSTRUCT is here.
下载后可阅读完整内容,剩余22页未读,立即下载
181 浏览量
点击了解资源详情
137 浏览量
2024-09-16 上传
2024-11-07 上传
137 浏览量
2024-12-02 上传
2024-11-07 上传
2024-11-07 上传

qq_36401221
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开








最新资源
- RS232串口监听助手:提升监测效率与准确性
- QT5基础象棋游戏开发与STM32F429移植计划
- 全面解析网络下载工具与资源管理
- VC环境下连接MySQL所需头文件指南
- 使用Django创建基础博客系统的指南
- WordPress与Mastodon集成:自动发布通知插件
- 用Visual C++实现a到b间素数的计算程序
- 简易诈金花游戏实现与规则解析
- Chrome浏览器安装Flash插件教程及文件
- C语言函数大全详尽解读及用法示例
- 阿拉伯数字转汉字转换程序实现
- 掌握JS获取编辑器值的技巧
- _roketdock桌面美化软件 - 绿色免安装包功能体验_
- 深入探索UIPageViewController的翻页功能
- MastoTwitter实现:在Mastodon与Twitter间双向同步
- 跨平台html转pdf工具wkhtmltopdf使用教程






















