概率模型驱动的聚类集成算法:提升数据挖掘与机器学习效果
版权申诉
138 浏览量
更新于2024-07-02
1
收藏 3.88MB PDF 举报
"这篇论文探讨了基于概率模型的聚类集成算法在计算机研究中的应用,旨在提高聚类分析的鲁棒性和质量。作者分析并比较了现有的聚类集成技术,提出了新的概率模型方法,该方法假设不同聚类结果源于同一潜在聚类模型,通过EM算法寻找最优模型。实验结果显示,新算法优于一些已知的聚类集成算法,如CSPA、HCGPA、MCLA和EAC-AL。"
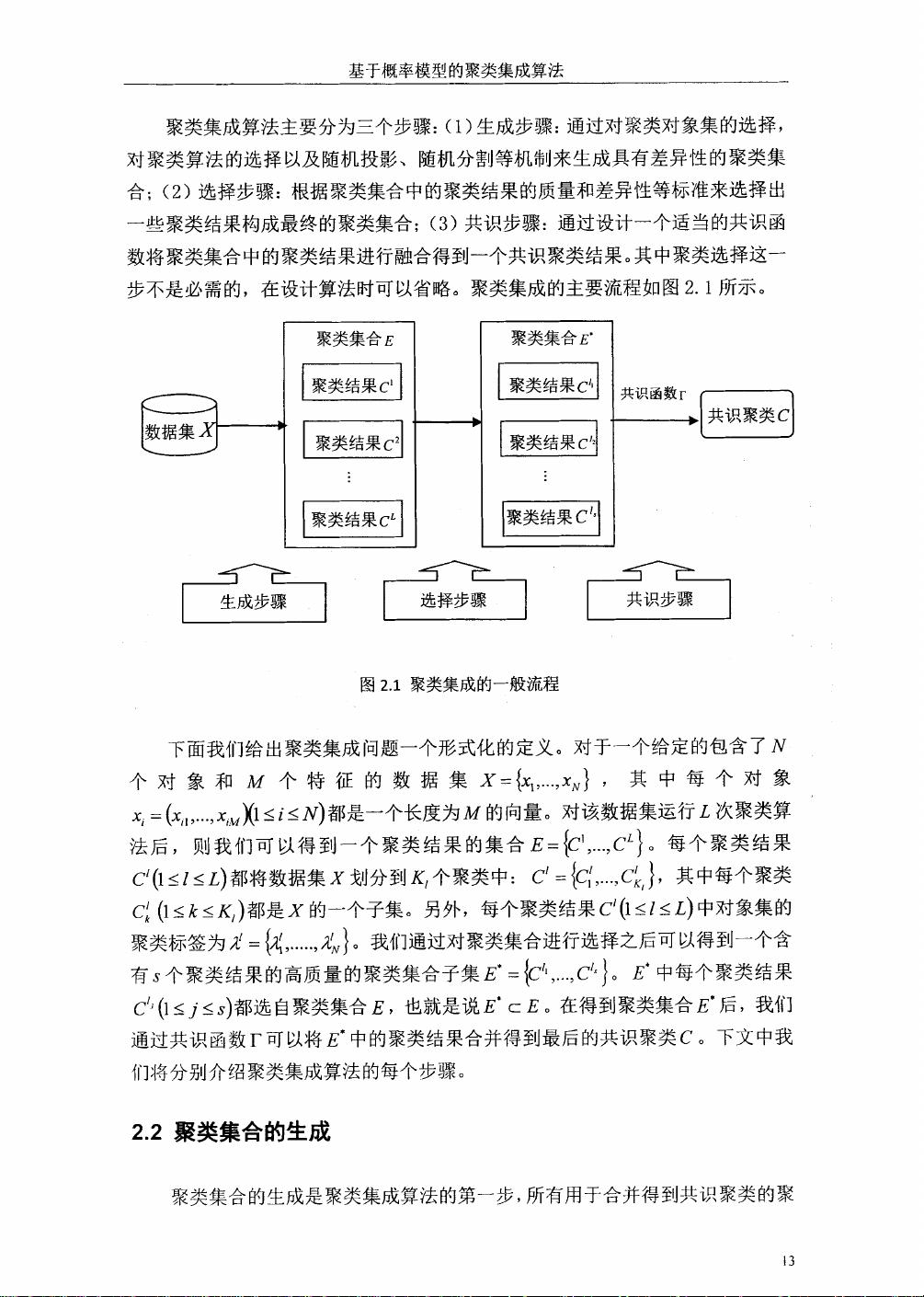
基于概率模型的聚类集成算法是解决聚类分析局限性的有效途径。传统的聚类算法,如K-means或层次聚类,往往基于特定的假设(如球形簇、距离度量等),这限制了它们在复杂数据集上的适用性。聚类集成技术通过整合多个独立或变异的聚类结果,可以捕捉数据的多样性和复杂性,从而提供更为稳健和准确的聚类。
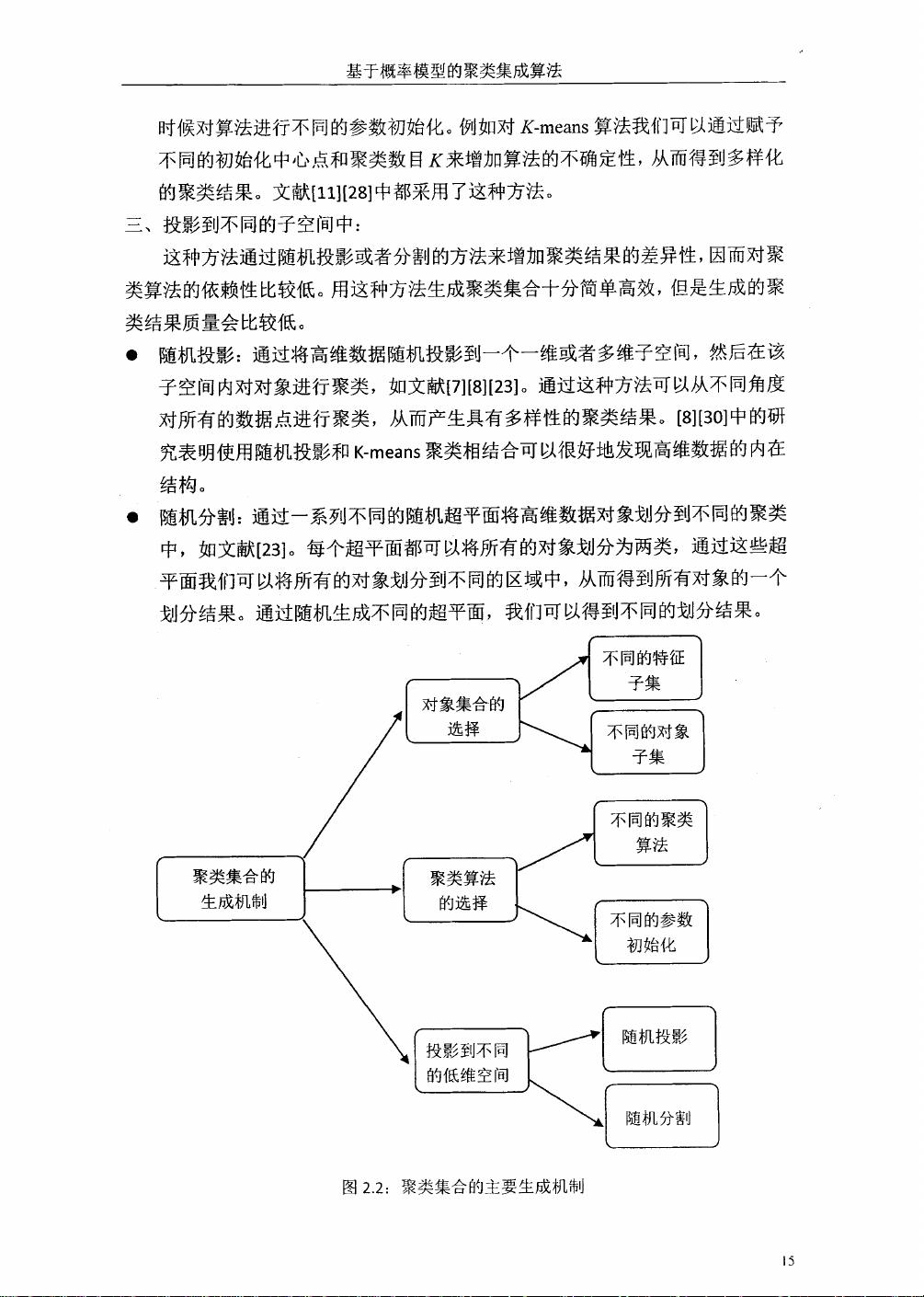
聚类集成技术主要包括三个核心环节:聚类集合的生成、选择和共识函数的设计。生成阶段涉及使用多种聚类算法或参数设置来产生多个聚类结果;选择阶段则考虑如何从这些结果中挑选出最有价值的信息;共识函数则是用来合并这些结果,形成最终的聚类共识。这篇论文聚焦于通过概率模型来改进这一过程。
论文提出的新算法基于概率论,假设所有观察到的聚类结果是由同一潜在聚类模型在不同概率参数控制下产生的。这种模型允许对数据集的内在结构有更灵活的建模,能更好地适应数据的多样性。采用的EM(期望最大化)算法是一种迭代优化方法,用于估计未知参数,在这里用于找到最能解释所有聚类结果的模型。
实验证明,新算法在性能上超过了CSPA(一致性聚类聚合)、HCGPA(层次聚类图的聚合)、MCLA(多视图聚类聚合)以及EAC-AL(增强的平均链接聚类)等算法。这意味着,基于概率模型的聚类集成算法在处理复杂和多样化数据时,能够提供更优的聚类结果,有助于提升数据分析的准确性和可靠性。
此研究对于数据挖掘和机器学习领域具有重要意义,特别是在大数据分析和模式识别中,可以有效地应对数据的不确定性和噪声,增强聚类分析的稳定性和有效性。未来的研究方向可能包括进一步优化概率模型,探索更多类型的共识函数,以及将这种方法扩展到其他机器学习任务中,如异常检测和特征选择。
万方数据

剩余50页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-07-21 上传
2021-12-19 上传
2022-12-24 上传
2021-08-08 上传
2022-12-17 上传
2022-11-02 上传

programyp
- 粉丝: 90
- 资源: 9323
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular程序高效加载与展示海量Excel数据技巧
- Argos客户端开发流程及Vue配置指南
- 基于源码的PHP Webshell审查工具介绍
- Mina任务部署Rpush教程与实践指南
- 密歇根大学主题新标签页壁纸与多功能扩展
- Golang编程入门:基础代码学习教程
- Aplysia吸引子分析MATLAB代码套件解读
- 程序性竞争问题解决实践指南
- lyra: Rust语言实现的特征提取POC功能
- Chrome扩展:NBA全明星新标签壁纸
- 探索通用Lisp用户空间文件系统clufs_0.7
- dheap: Haxe实现的高效D-ary堆算法
- 利用BladeRF实现简易VNA频率响应分析工具
- 深度解析Amazon SQS在C#中的应用实践
- 正义联盟计划管理系统:udemy-heroes-demo-09
- JavaScript语法jsonpointer替代实现介绍
