动手编写网络爬虫:JAVA实现与URL解析
需积分: 11 111 浏览量
更新于2024-07-28
收藏 2.49MB PDF 举报
"网络爬虫netspider是关于使用JAVA实现网络爬虫程序的介绍,旨在让读者理解网络爬虫的工作原理并具备编写简单爬虫的能力。内容涵盖网络爬虫的基础概念、URL的理解、网页抓取的方法以及HTTP状态码的处理。通过学习,你可以自行抓取互联网上的各种信息,满足数据整合、数据挖掘等需求。"
网络爬虫是一种自动化程序,用于遍历互联网并抓取网页内容。在Java中实现网络爬虫,通常会利用相关的库来简化工作,如Jsoup、Apache HttpClient或OkHttp等。这些库提供了方便的API,用于解析HTML、发送HTTP请求和处理响应。
1.1 抓取网页
抓取网页的核心是理解URL(统一资源定位符)和HTTP协议。URL是每个网页在网络上的唯一标识,包含了访问协议(如http或https)、主机名和路径。例如,"http://www.example.com/path/to/page"就是一个典型的URL。当你在浏览器中输入URL并按下回车,浏览器就向指定的服务器发送一个HTTP GET请求,请求获取该URL指向的资源。
1.1.1 深入理解URL
URI(通用资源标识符)比URL更为广泛,它不仅包括URL,还可以是其他类型的资源标识,如URN(统一资源名称)。URL是URI的一个子集,专门用于定位可以通过网络访问的资源。在Java中,可以使用java.net.URL类来处理和解析URL。
1.1.2 发送HTTP请求
在Java中,可以使用HttpURLConnection或者HttpClient类发送HTTP请求。这些类允许设置请求头、指定HTTP方法(如GET或POST),并处理返回的HTTP响应。HTTP响应中包含了一个状态码,例如200表示成功,404表示未找到,500表示服务器错误等。理解这些状态码对于调试和优化爬虫至关重要。
1.2 解析HTML和提取数据
抓取到网页后,通常需要解析HTML并提取所需数据。Jsoup是一个强大的库,它可以方便地解析DOM结构,并提供CSS选择器来定位元素。例如,你可以使用Jsoup的select()方法来选取特定的HTML标签,然后提取其文本内容。
1.3 处理HTTP状态码
在抓取过程中,遇到不同的HTTP状态码需要采取相应的策略。例如,当遇到404状态码时,可能需要跳过该链接;遇到503(服务不可用)时,可能需要稍后再重试。理解并正确处理这些状态码能提高爬虫的稳定性和效率。
1.4 爬虫的进阶
除了基础的网页抓取,网络爬虫还需要考虑其他因素,如反爬虫机制、数据存储、并发抓取、分布式爬虫等。例如,使用代理IP可以避免被目标网站封禁,数据库或文件系统用于存储抓取的数据,多线程或异步处理可以加快爬取速度,而分布式爬虫则能处理更大规模的数据抓取任务。
通过学习网络爬虫,你可以创建自己的数据抓取工具,无论是用于商业分析、研究项目还是个人兴趣,都能灵活获取并利用互联网上的信息。但同时要注意,合法和道德的爬虫实践是必要的,尊重网站的robots.txt文件,避免对目标服务器造成过大压力。
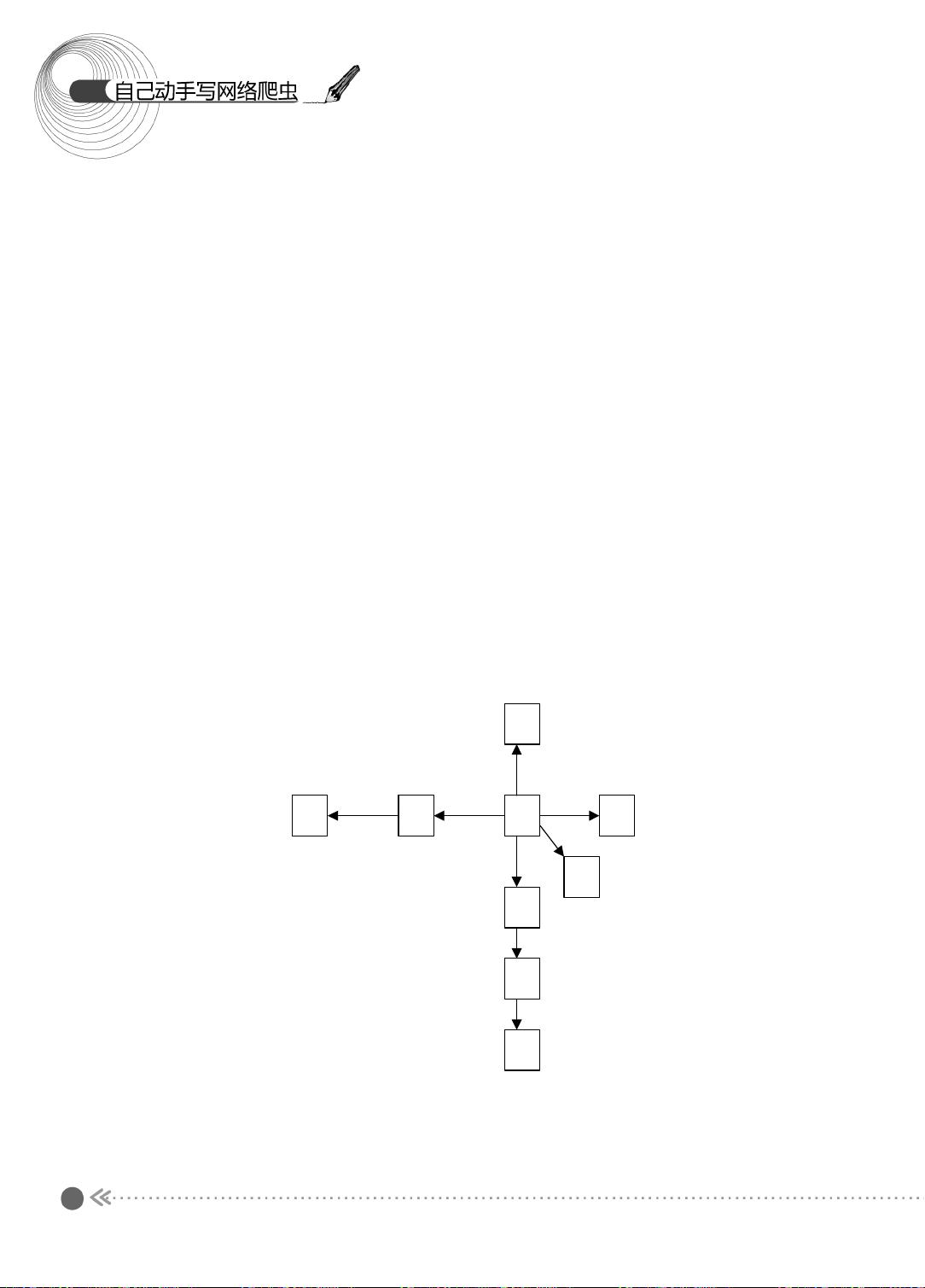
12
1
的遍历的方式对互联网这个超级大 “ 图 ” 进行访问。图的遍历通常可分为宽度优先遍历和
深度优先遍历两种方式。但是深度优先遍历可能会在深度上过 “ 深 ” 地遍历或者陷入 “ 黑
洞 ” ,大多数爬虫都不采用这种方式。另一方面,在爬取的时候,有时候也不能完全按照
宽度优先遍历的方式 , 而是给待遍历的网页赋予一定的优先级 , 根据这个优先级进行遍历
,
这种方法称为带偏好的遍历。本小节会分别介绍宽度优先遍历和带偏好的遍历。
1.2.1 图的宽度优先遍历
下面先来看看图的宽度优先遍历过程 。 图的宽度优先遍历 (BFS) 算法是一个分层搜索的
过程,和树的层序遍历算法相同。在图中选中一个节点,作为起始节点,然后按照层次遍
历的方式,一层一层地进行访问。
图的宽度优先遍历需要一个队列作为保存当前节点的子节点的数据结构。具体的算法
如下所示:
(1) 顶点 V 入队列。
(2) 当队列非空时继续执行,否则算法为空。
(3) 出队列,获得队头节点 V ,访问顶点 V 并标记 V 已经被访问。
(4) 查找顶点 V 的第一个邻接顶点 col 。
(5) 若 V 的邻接顶点 col 未被访问过,则 col 进队列。
(6) 继续查找 V 的其他邻接顶点 col ,转到步骤 (5) ,若 V 的所有邻接顶点都已经被访
问过,则转到步骤 (2) 。
下面,我们以图示的方式介绍宽度优先遍历的过程,如图 1.3 所示。
G
B
A
C
D
F
E
I
H
图 1.3 宽度优先遍历过程

剩余67页未读,继续阅读
点击了解资源详情
2008-07-18 上传
2009-12-08 上传
2009-09-15 上传
2011-11-16 上传
2009-11-09 上传
2017-03-27 上传
2015-07-02 上传
2018-04-16 上传

dangdang1124
- 粉丝: 0
- 资源: 5
 我的内容管理
展开
我的内容管理
展开







最新资源
- Python中快速友好的MessagePack序列化库msgspec
- 大学生社团管理系统设计与实现
- 基于Netbeans和JavaFX的宿舍管理系统开发与实践
- NodeJS打造Discord机器人:kazzcord功能全解析
- 小学教学与管理一体化:校务管理系统v***
- AppDeploy neXtGen:无需代理的Windows AD集成软件自动分发
- 基于SSM和JSP技术的网上商城系统开发
- 探索ANOIRA16的GitHub托管测试网站之路
- 语音性别识别:机器学习模型的精确度提升策略
- 利用MATLAB代码让古董486电脑焕发新生
- Erlang VM上的分布式生命游戏实现与Elixir设计
- 一键下载管理 - Go to Downloads-crx插件
- Java SSM框架开发的客户关系管理系统
- 使用SQL数据库和Django开发应用程序指南
- Spring Security实战指南:详细示例与应用
- Quarkus项目测试展示柜:Cucumber与FitNesse实践
