频繁项集(Frequent Itemset)挖掘算法笔记
需积分: 10 81 浏览量
更新于2024-10-29
收藏 873KB PDF 举报
"这篇笔记主要介绍了频繁项集(Frequent Itemset)的概念以及关联规则(Association Rules),并探讨了寻找频繁项集的算法,包括朴素算法和Apriori算法,同时还涉及了内存优化策略和多阶段算法。"
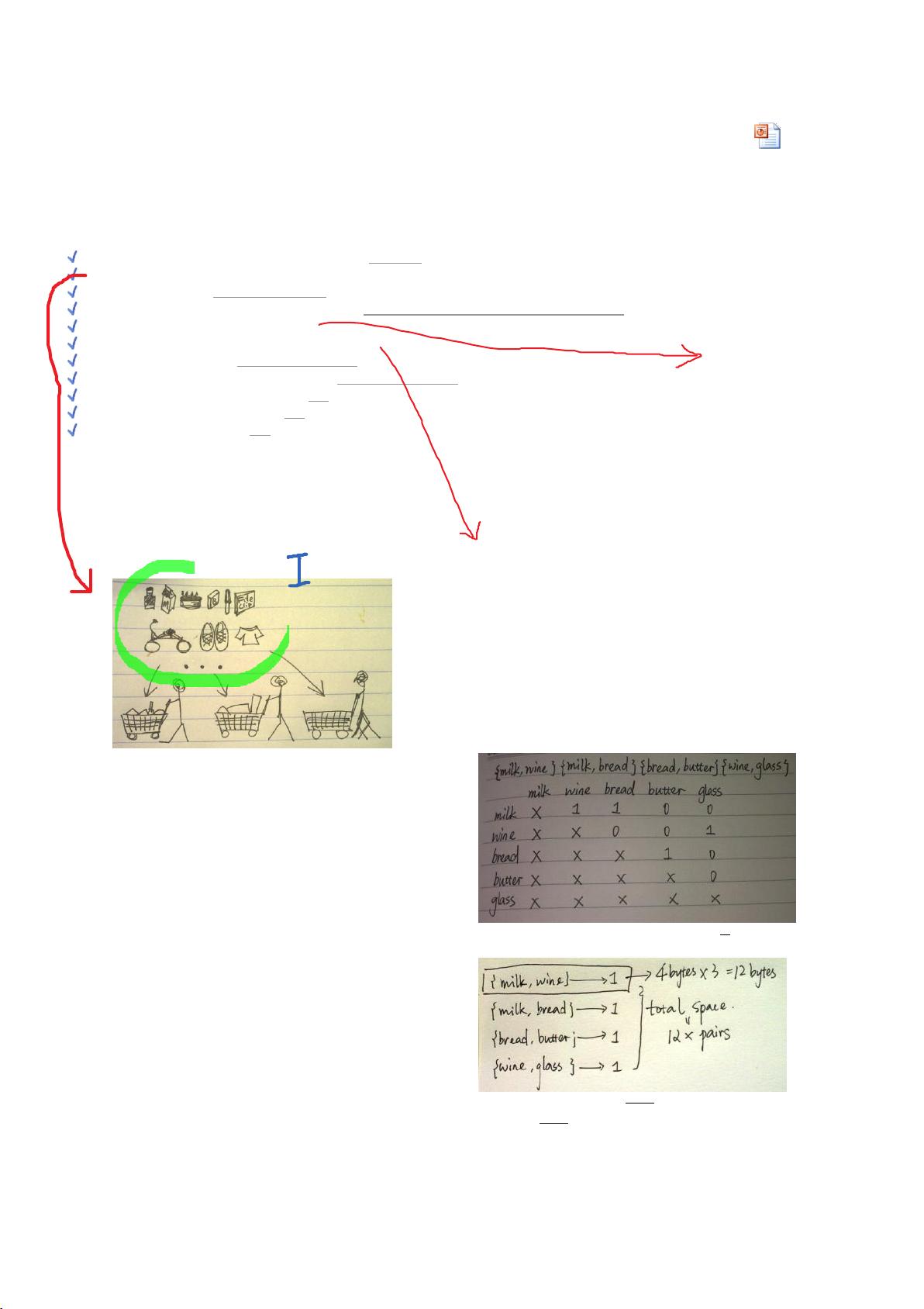
在数据挖掘领域,市场购物篮模型是一个常见的例子,用于分析消费者购买行为。在这个模型中,每个篮子代表一个客户的购买记录,而项集(itemset)则是一组被同时购买的商品。频繁项集是指在数据集中出现频率超过一定阈值的项集,通常这个阈值设定为总交易量的1%。
基本定义中,项集是一组商品,而购物篮(basket)是包含这些项的交易记录集合。支持度是衡量项集频繁程度的指标,即项集在所有篮子中出现的比例。例如,如果一个项集在1%的篮子中出现,那么它的支持度就是1%。
寻找频繁项集的算法可以扩展到不同大小的项集,比如从频繁对到频繁三元组等。在处理非连续的item_id时,可以使用哈希函数将其映射到连续空间以节省存储空间。计数方法通常有两种:三角矩阵和哈希表。前者在空间占用上随着项数量的增加呈线性增长,后者则更高效,尤其在查找和更新计数时。
朴素算法是最直观的方法,它逐块读取数据,对每个块中的项集计数。然而,这种方法效率较低,因为它需要扫描数据多次,计算所有可能的项集。为了解决这个问题,Apriori算法应运而生,它利用了“频繁项集的任何子集也必须是频繁的”这一特性,显著减少了候选项集的生成,提高了效率。
Apriori算法包括两个主要步骤:生成频繁项集和构建关联规则。在实现时,可以采取优化策略,如利用主内存(PCY算法)来减少磁盘I/O,或者采用多阶段算法,逐步找出频繁项集。
关联规则是描述项集间关系的表达式,形式为:“如果X发生,那么Y也倾向于发生”,其中X和Y是项集,且Y是X的子集。规则的可信度(confidence)是规则发生的概率,计算为支持度(X U Y) / 支持度(X)。
总结来说,这篇笔记涵盖了频繁项集挖掘的基本概念、算法和优化策略,对于理解数据挖掘中的关联规则分析具有重要价值。
The market-basket model(现实问题,引入)2 Models
1.
Basic definitions
2.
Association rules Association rules
3.
The computation model for frequent itemsets Computation model for Frequent Itemsets
4.
The distribution of frequent itemsets
5.
The naive algorithm for finding frequent itemsets
6.
The a-priori algorithm a-priori algorithm
7.
Implementation of the A-priori algorithm a-priori algorithm
8.
Making Better Use of Main Memory(PCY)
9.
When to Use the PCY algorithm(PCY)
10.
The multistage algorithm(PCY)
11.
Topic: Frequent-Itemset Mining & Algorithms for Finding Frequent Itemset
Basic definition
:set of items
:set of baskets
: 支持度阈值 --> frequent
Typically, a threshold around 1% of the
baskets is used.
1.
找频繁对(frequent pair)的算法基本都
能应用到找频繁三元组(frequent
triples)、四元组(quadruples)
2.
如果item_id不是从0开始的,就将
item_id用hash函数映射到
(节约空
间)
3.
另:有两种储存计数方法
一种是triangular matrix(三角矩阵),另一种是hash
table。
假设有
个items,那么上面表格所占空间为约为
假设有k个items,那么最多有
个pair,那么做多
占空间
小远
演示ppt
每次读一个block的baskets
1.
对这个block上的每一个
2.
3.
的出现次数加1
Naive Algorithm
Preparation for Presentation(6/4)
Thursday, June 03, 2010
3:17 PM
分区
DBMS
的第
1
页
下载后可阅读完整内容,剩余5页未读,立即下载
2008-11-23 上传
2008-12-31 上传
2021-04-30 上传
2019-02-08 上传
2021-05-12 上传
2020-02-11 上传
2019-04-18 上传
2017-03-28 上传
2021-04-29 上传

qin1537
- 粉丝: 0
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- matlab离散傅里叶变换平滑代码-awesome-geospatial:真骨-
- 带有Arduino Uno和蓝牙的汽车控制-项目开发
- Avalos World Server/Engine-开源
- 清新玫瑰花背景的唯美幻灯片模板免费下载
- windows opencv 编译, 下载 opencv_ffmpeg.dll等文件失败
- Cscms V4.1 BBDJ带cd刻录 U盘商城 伪静态列表月份.zip
- 定制处理游戏引擎:定制处理游戏引擎
- 离心泵管嘴受力的有限元分析及研究.rar
- readini.rar
- PineApple3D-开源
- 绿色植物信息网页模板
- java代码-33wzw 实训4-2
- 一个学习如何玩的游戏-项目开发
- ecoleta后端
- WeaponSoul RPG Game Engine-开源
- matlab导入excel代码-End-to-End-Data-Science-Resources:端到端数据科学资源
