Greenplum大数据引擎:架构与技术深度解析
46 浏览量
更新于2024-08-28
收藏 417KB PDF 举报
"本文将深入探讨开源大数据引擎Greenplum的架构和技术特点,包括其Master/Slave架构、sharednothing架构(MPP)以及Master和Segment节点的角色与功能,同时涉及Master节点的高可用性策略。"
Greenplum,通常简称为GPDB,是一款基于PostgreSQL改造的开源数据仓库,专为大规模数据分析任务设计。与Hadoop相比,Greenplum在大数据存储、计算和分析方面表现出更高的效率。其核心技术是采用多节点并行处理的MPP(Massively Parallel Processing)架构,确保系统能够处理海量数据,并提供高效的查询性能。
在Greenplum的架构中,存在一个Master节点和多个Segment节点。Master节点是整个系统的控制中心,不存储用户数据,仅保存系统元数据。它负责接收客户端的请求,解析SQL语句,生成执行计划,并将这些任务分发给Segment节点。Segment节点是数据存储和计算的实体,每个节点上可以运行多个数据库,它们各自独立处理一部分数据,并将结果返回给Master节点进行整合。这种设计使得Greenplum能够通过增加节点数量实现线性扩展,提高系统处理能力。
在Master节点的高可用性方面,Greenplum采用了类似于Hadoop NameNode HA的机制。有一个Standby Master与Primary Master同步,确保Catalog和事务日志的一致性。一旦Primary Master发生故障,Standby Master能够立即接管,保证服务不间断。
Segment节点是Greenplum数据存储和计算的核心组件。每个Segment节点负责一部分数据的存储,并执行与之相关的查询操作。通过在Segment之间并行处理任务,Greenplum实现了数据的快速处理。Segment节点之间的通信通过节点间的网络互联实现,遵循sharednothing原则,即节点间不共享物理存储,减少数据冗余和复杂性,提高系统整体性能。
总结来说,Greenplum的架构设计旨在提供高效的大数据处理能力,通过MPP架构和Master-Segment模型实现数据的分布式存储和计算,同时通过Master节点的高可用性保障系统的稳定性和可靠性。这使得Greenplum成为企业级大数据解决方案的有力竞争者,特别适用于需要快速分析大规模数据的场景。
详解开源大数据引擎详解开源大数据引擎Greenplum的架构和技术特点的架构和技术特点
Greenplum的MPP架构
Greenplum(以下简称GPDB)是一款开源数据仓库。基于开源的PostgreSQL改造,主要用来处理大规模数据分析任务,相
比Hadoop,Greenplum更适合做大数据的存储、计算和分析引擎。
GPDB是典型的Master/Slave架构,在Greenplum集群中,存在一个Master节点和多个Segment节点,其中每个节点上可以运
行多个数据库。Greenplum采用shared nothing架构(MPP)。典型的Shared Nothing系统会集数据库、内存Cache等存储状
态的信息;而不在节点上保存状态的信息。节点之间的信息交互都是通过节点互联网络实现。通过将数据分布到多个节点上来
实现规模数据的存储,通过并行查询处理来提高查询性能。每个节点仅查询自己的数据。所得到的结果再经过主节点处理得到
最终结果。通过增加节点数目达到系统线性扩展。
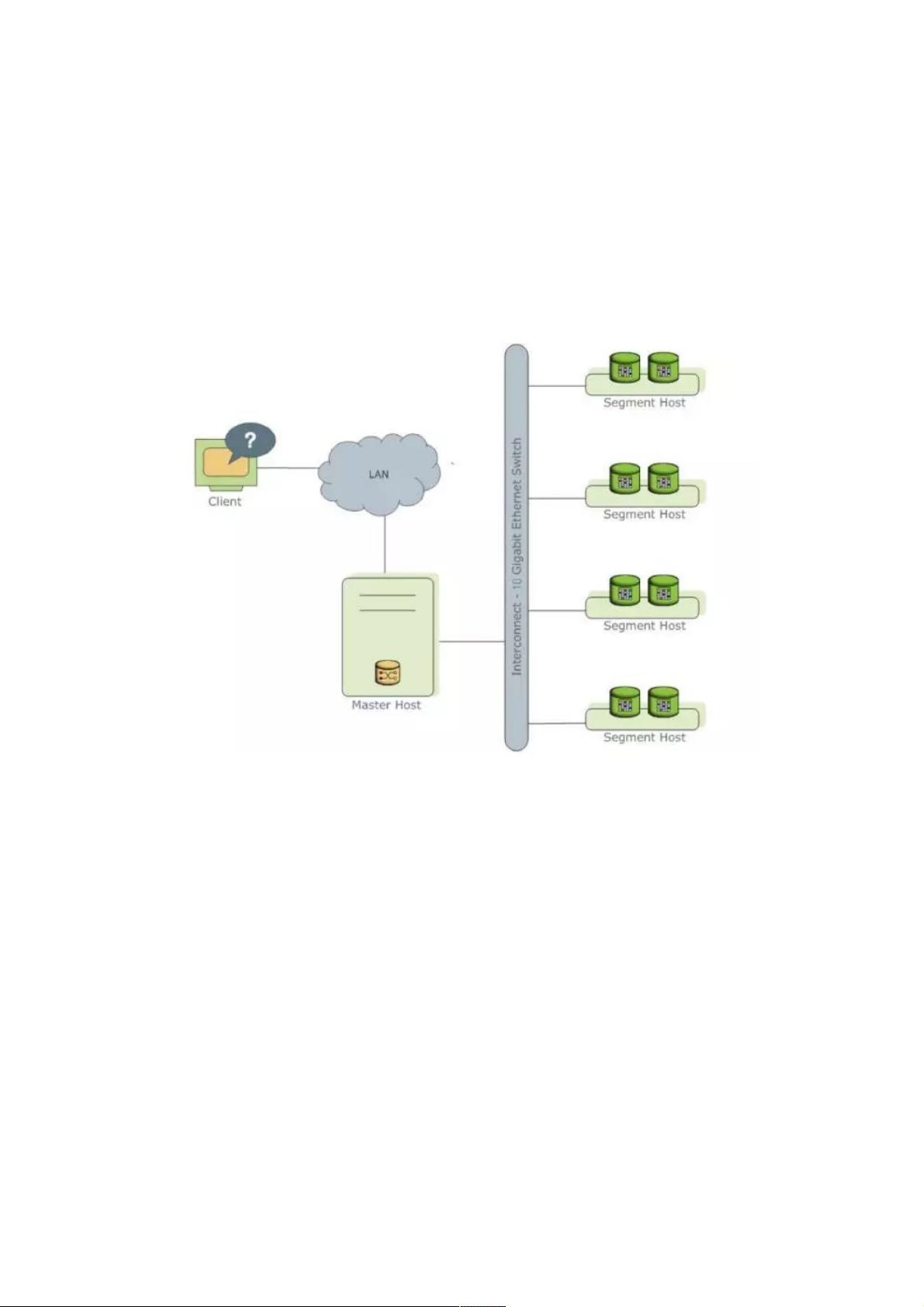
图1 GPDB的基本架构
如上图1为GPDB的基本架构,客户端通过网络连接到gpdb,其中Master Host是GP的主节点(客户端的接入点),Segment
Host是子节点(连接并提交SQL语句的接口),主节点是不存储用户数据的,子节点存储数据并负责SQL查询,主节点负责
相应客户端请求并将请求的SQL语句进行转换,转换之后调度后台的子节点进行查询,并将查询结果返回客户端。
Greenplum Master
Master只存储系统元数据,业务数据全部分布在Segments上。其作为整个数据库系统的入口,负责建立与客户端的连
接,SQL的解析并形成执行计划,分发任务给Segment实例,并且收集Segment的执行结果。正因为Master不负责计算,所
以Master不会成为系统的瓶颈。
Master节点的高可用(图2),类似于Hadoop的NameNode HA,如下图,Standby Master通过synchronization process,保
持与Primary Master的catalog和事务日志一致,当Primary Master出现故障时,Standby Master承担Master的全部工作。
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
169 浏览量
279 浏览量
187 浏览量
325 浏览量
5661 浏览量

weixin_38592548
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- VS2010环境Qt链接MySQL数据库测试程序
- daycula-vim主题:黑暗风格的Vim色彩方案
- HTTPComponents最新版本发布,客户端与核心组件升级
- Android WebView与JS互调的实践示例
- 教务管理系统功能全面,操作简便,适用于winxp及以上版本
- 使用堆栈实现四则运算的编程实践
- 开源Lisp实现的联合生成算法及多面体计算
- 细胞图像处理与模式识别检测技术
- 深入解析psimedia:音频视频RTP抽象库
- 传名广告联盟商业正式版 v5.3 功能全面升级
- JSON序列化与反序列化实例教程
- 手机美食餐饮微官网HTML源码开源项目
- 基于联合相关变换的图像识别程序与土豆形貌图片库
- C#毕业设计:超市进销存管理系统实现
- 高效下载地址转换器:迅雷与快车互转
- 探索inoutPrimaryrepo项目:JavaScript的核心应用
