东南大学信息学院:朱恩、胡庆生专用集成电路课程与发展趋势
本资源是一份东南大学信息科学与工程学院的专用集成电路课程讲义,由朱恩和胡庆生教授编著。课程内容涵盖了集成电路设计的基本原理和历史发展,重点讨论了微电子技术中的重要里程碑,特别是集成电路(ASIC)的发展趋势。以下是部分知识点概述:
1. **集成电路起源与发展**:课程以晶体管的发明作为起点,介绍了1947年贝尔实验室三位科学家(威廉·肖克利、沃尔特·布拉坦和约翰·巴丁)的贡献,并提及了1958年德州仪器公司Jack Kilby的首款集成电路,以及他因此获得的2000年诺贝尔物理学奖。
2. **微处理器历程**:课程详细列举了Intel公司在1971年到2000年间推出的一系列微处理器,如4004、8080、80286、80386、80486、Pentium、Pentium Pro和Pentium-4,展示了集成电路技术的飞速进步。
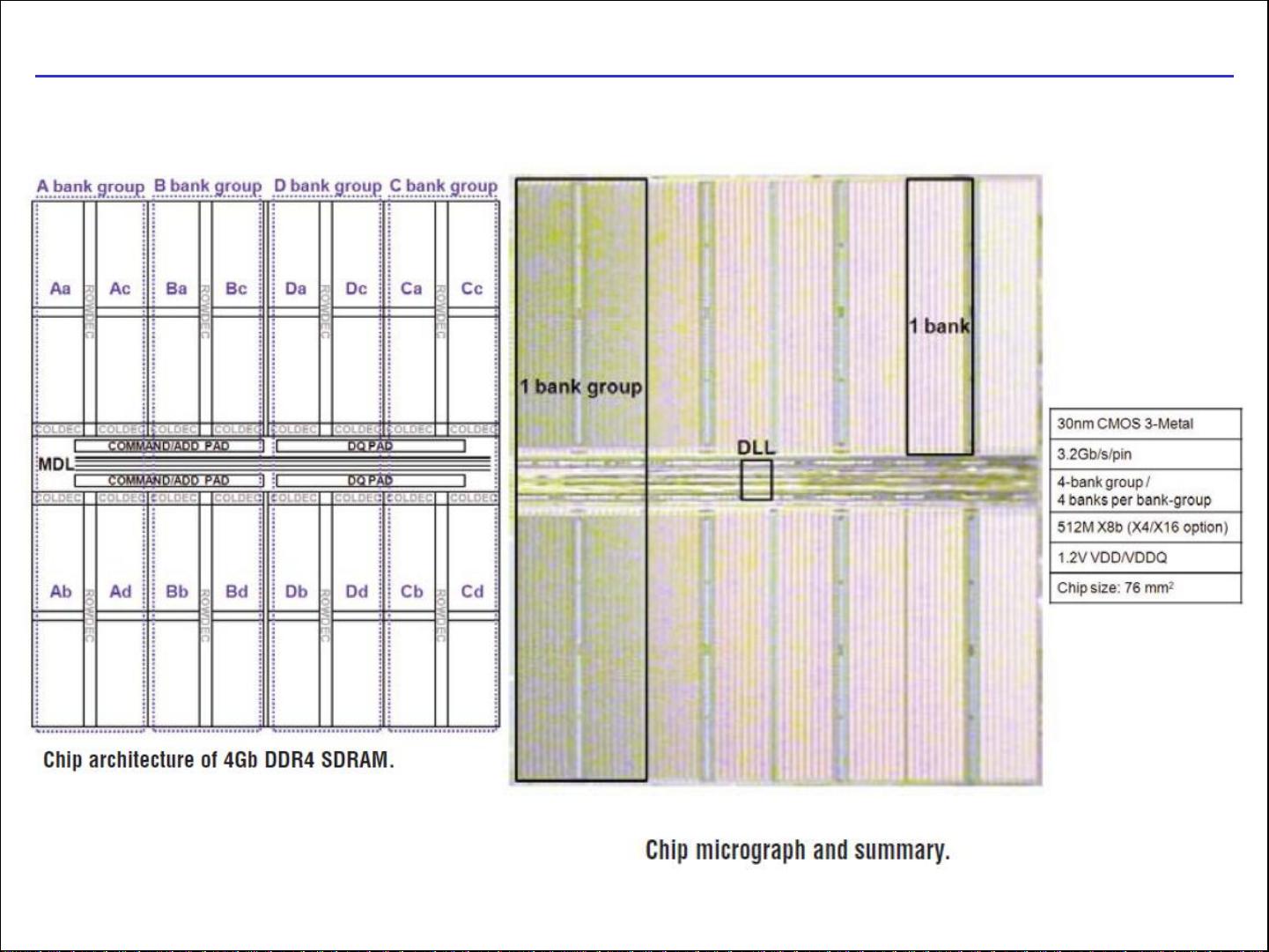
3. **工艺技术进步**:讲解了Intel采用的90nm、32nm、22nm等先进半导体制造工艺,以及这些工艺对处理器性能的影响,比如Intel i7处理器的四核结构,带有14亿个晶体管,以及4Gb DDR4 SDRAM的出现。
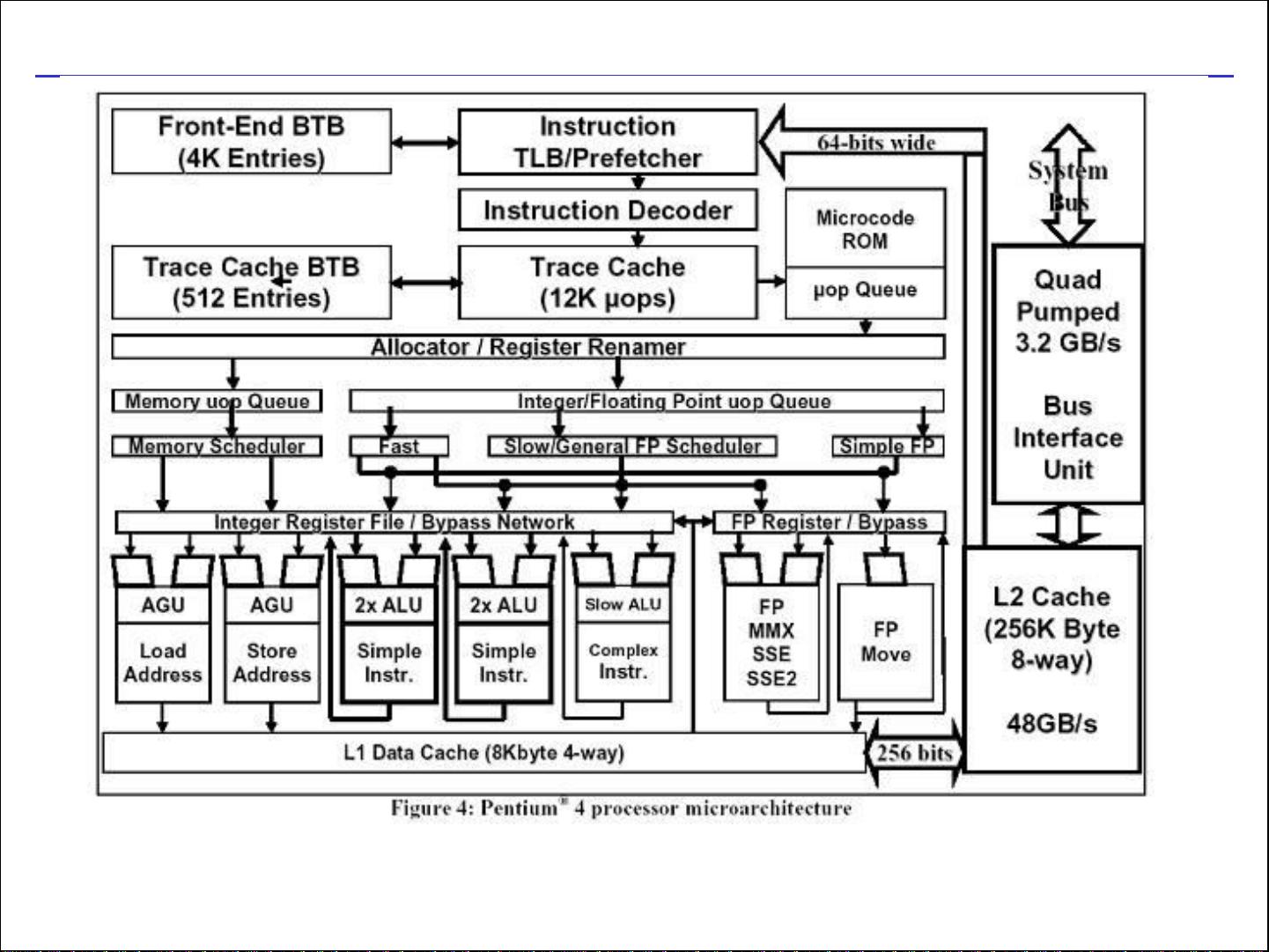
4. **处理器架构和非CPU类VLSI芯片**:介绍了Intel Pentium 4处理器的系统架构,强调了其内部复杂的功能模块,包括协处理器和高速内存接口。同时,课程还提到了非CPU类的VLSI芯片,如用于存储的高密度内存。
5. **半导体制造技术前沿**:展示了当前半导体制造商如Intel、三星、意法半导体和IBM在纳米技术方面的最新进展,这反映了半导体行业的不断创新和竞争。
通过这个课程,学生可以深入了解专用集成电路设计的基础理论,以及它在现代信息技术中的关键角色,以及技术演进背后的驱动力。对于那些希望从事芯片设计或微电子领域的专业人士来说,这份资料提供了宝贵的历史背景和实用知识。
511 浏览量
2009-11-25 上传
384 浏览量
143 浏览量
293 浏览量

DeanRossi
- 粉丝: 7
- 资源: 51
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于ADO数据访问技术的等边角钢参数化设计.doc
- 如何实现无刷新的DropdownList联动效果
- 网络工程投标书样本2009
- VS2005(c#)项目调试问题解决方案集锦(五)
- VS2005(c#)项目调试问题解决方案集锦(四)
- 《python核心笔记》
- H.264_中英文对照翻译(AVS264 V1.0)
- java cook book
- PHP在Web开发领域的优势
- Spring 入门书籍
- 《微内核工作流引擎体系结构与部分解决方案参考》
- PHP初学者头疼问题总结
- ArcObjects+GIS应用开发——基于C#.NET
- 工作流引擎核心调度算法与PetriNet_胡长城.pdf
- 《工作流模型分析》胡长城
- c8051f020文档资料
