深度学习中的注意力机制综述
需积分: 48 80 浏览量
更新于2024-07-05
收藏 3.34MB PDF 举报
"这篇文档是关于深度学习中注意力机制的综合调查,涵盖了各种注意力模型、统一的符号表示、全面的分类体系以及模型评估方法。文章还探讨了基于此框架的注意力模型结构表征,并展望了该领域的未来研究方向。关键词包括注意力模型、深度学习、监督学习、神经网络和计算机视觉。"
深度学习中的注意力机制已经成为提高模型性能的关键工具,特别是在处理大量数据和复杂任务时。这种机制源自于模仿人类的注意力模式,最初在计算机视觉领域得到应用,旨在降低图像处理的计算复杂度并提高性能。通过聚焦图像的特定部分,模型能够更有效地理解和解析输入信息。
注意力机制的种类繁多,包括自注意力(self-attention)、全局注意力(global attention)、局部注意力(local attention)等。它们在自然语言处理(NLP)、语音识别、图像识别等领域有着广泛的应用。例如,在NLP中,注意力机制允许模型在理解长句子时重点关注关键信息,从而改善翻译质量和语义理解。
文章提出了一种通用的注意力模型框架,它包括一个基本的注意力模型、统一的符号系统和一个全面的注意力机制分类。这个框架有助于理解和比较不同的注意力模型,为研究人员提供了标准化的视角。同时,文中回顾了评估注意力模型性能的各种指标,如注意力权重的可视化、BLEU分数、ROUGE分数等,这些指标可以帮助评估模型是否有效地关注到输入中的重要信息。
此外,文章还讨论了如何根据提出的框架来表征注意力模型的结构。这可能涉及到分析注意力分布、注意力路径等,以揭示模型的学习行为和决策过程。这种方法对于理解模型的黑盒性质和改进模型设计至关重要。
最后,作者对未来的研究方向进行了展望,可能包括更高效、更具解释性的注意力机制、结合其他机器学习范式(如强化学习)的注意力模型,以及在新兴领域(如多模态学习)中的应用。随着深度学习和人工智能的发展,注意力机制将继续扮演重要角色,推动模型的性能提升和理解能力的增强。
4
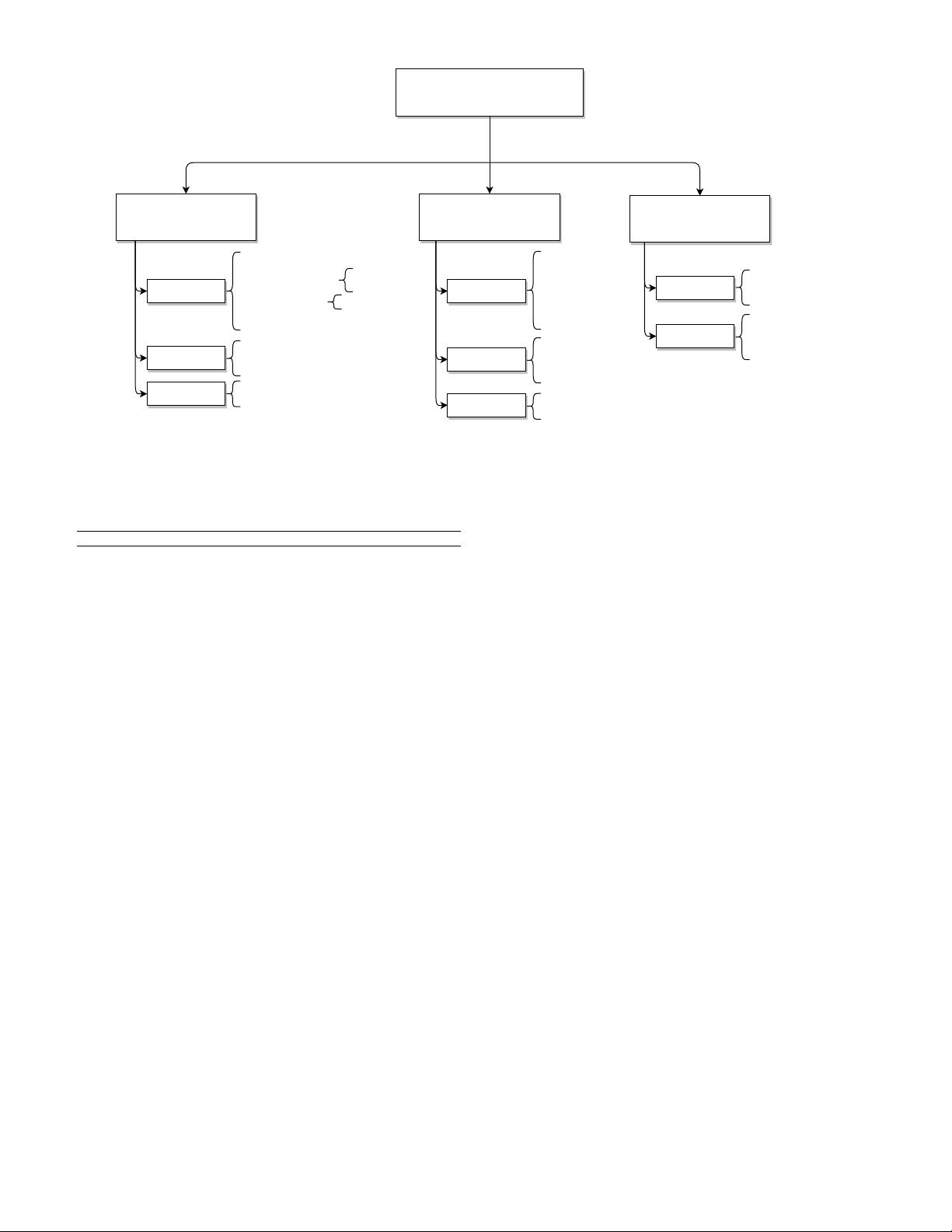
Attention Mechanisms
Feature-Related
Query-Related
General
Multiplicity
Levels
Representations
Scoring
Alignment
Multiplicity
Type
Dimensionality
Singular Features Attention
Coarse-Grained Co-Attention
Fine-Grained Co-Attention
Multi-Grained Co-Attention
Rotatory Attention
Single-Level Attention
Attention-via-Attention
Hierarchical Attention
Single-Representational Attention
Multi-Representational Attention
Additive Scoring
Multiplicative Scoring
Scaled Multiplicative Scoring
General Scoring
Biased General Scoring
Activated General Scoring
Similarity Scoring
Global/Soft Alignment
Hard Alignment
Local Alignment
Reinforced Alignment
Single-Dimensional Attention
Multi-Dimensional Attention
Basic Queries
Specialized Queries
Self-Attentive Queries
Alternating Co-Attention
Interactive Co-Attention
Parallel Co-Attention
Singular Query Attention
Multi-Head Attention
Multi-Hop Attention
Capsule-Based Attention
Fig. 3. A taxonomy of attention mechanisms.
TABLE 1
Notation.
Symbol Description
F Matrix of size d
f
× n
f
containing the feature vectors
f
1
, . . . , f
n
f
∈ R
d
f
as columns. These feature vectors
are extracted by the feature model.
K Matrix of size d
k
× n
f
containing the key vectors
k
1
, . . . , k
n
f
∈ R
d
k
as columns. These vectors are used
to calculate the attention scores.
V Matrix of size d
v
× n
f
containing the value vectors
v
1
, . . . , v
n
f
∈ R
d
v
as columns. These vectors are used
to calculate the context vector.
W
K
Weights matrix of size d
k
× d
f
used to create the K
matrix from the F matrix.
W
V
Weights matrix of size d
v
× d
f
used to create the V
matrix from the F matrix.
q Query vector of size d
q
. This vector essentially repre-
sents a question, and is used to calculate the attention
scores.
c Context vector of size d
v
. This vector is the output of the
attention model.
e Score vector of size d
n
f
containing the attention scores
e
1
, . . . , e
n
f
∈ R
1
. These are used to calculate the atten-
tion weights.
a Attention weights vector of size d
n
f
containing the at-
tention weights a
1
, . . . , a
n
f
∈ R
1
. These are the weights
used in the calculation of the context vector.
orthogonal dimensions of an attention model. An attention
model can consist of a combination of techniques taken
from any or all categories. Some characteristics, such as
the scoring and alignment functions, are generally required
for any attention model. Other mechanisms, such as multi-
head attention or co-attention are not necessary in every
situation. Lastly, in Table 1, an overview of used notation
with corresponding descriptions is provided.
3.1 Feature-Related Attention Mechanisms
Based on a particular set of input data, a feature model
extracts feature vectors so that the attention model can
attend to these various vectors. These features may have
specific structures that require special attention mechanisms
to handle them. These mechanisms can be categorized to
deal with one of the following feature characteristics: the
multiplicity of features, the levels of features, or the repre-
sentations of features.
3.1.1 Multiplicity of Features
For most tasks, a model only processes a single input, such
as an image, a sentence, or an acoustic sequence. We refer
to such a mechanism as singular features attention. Other
models are designed to use attention based on multiple
inputs to allow one to introduce more information into the
model that can be exploited in various ways. However, this
does imply the presence of multiple feature matrices that
require special attention mechanisms to be fully used. For
example, [32] introduces a concept named co-attention to
allow the proposed visual question answering (VQA) model
to jointly attend to both an image and a question.
Co-attention mechanisms can generally be split up
into two groups [33]: coarse-grained co-attention and
fine-grained co-attention. The difference between the two
groups is the way attention scores are calculated based on
the two feature matrices. Coarse-grained attention mecha-
nisms use a compact representation of one feature matrix
as a query when attending to the other feature vectors.
Fine-grained co-attention, on the other hand, uses all feature
vectors of one input as queries. As such, no information is
lost, which is why these mechanisms are called fine-grained.
As an example of coarse-grained co-attention, [32] pro-
poses an alternating co-attention mechanism that uses the
context vector (which is a compact representation) from one
attention module as the query for the other module, and
vice versa. Alternating co-attention is presented in Fig. 4.
Given a set of two input matrices X
(1)
and X
(2)
, features
are extracted by a feature model to produce the feature
matrices F
(1)
∈ R
d
(1)
f
×n
(1)
f
and F
(2)
∈ R
d
(2)
f
×n
(2)
f
, where d
(1)
f
剩余19页未读,继续阅读
2022-06-30 上传
2019-04-17 上传
2019-09-09 上传
2021-09-25 上传
2020-02-29 上传
2021-09-25 上传
2021-09-23 上传
2021-03-29 上传

努力+努力=幸运
- 粉丝: 3
- 资源: 136
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
