Scrapy爬虫框架入门:安装与项目创建
117 浏览量
更新于2024-08-31
收藏 314KB PDF 举报
"Scrapy爬虫1 - 网络爬虫原理,Scrapy框架结构,爬虫步骤,安装Scrapy的常见问题及其解决方法,Scrapy项目创建和执行流程,以及Scrapy爬虫代码示例"
在IT行业中,网络爬虫是一种用于自动化收集大量网页数据的工具,而Scrapy是一个强大的Python爬虫框架,广泛应用于数据抓取和处理。本资源主要介绍了Scrapy的基本概念和操作流程。
首先,理解网络爬虫原理是至关重要的。网络爬虫通过模拟浏览器行为,遵循HTTP协议,自动请求网页并解析其中的数据。它通常包括四个基本步骤:需求分析(确定要爬取的数据和目标)、创建项目(搭建项目结构)、分析页面(理解网页结构和数据位置)、实现爬虫(编写代码抓取和处理数据)以及运行爬虫(执行爬虫脚本并保存结果)。
在使用Scrapy时,安装可能会遇到问题。例如,Scrapy依赖于Twisted库,如果安装过程中出现错误,可以尝试先单独安装Twisted,或者使用conda环境进行安装。如描述中所述,可以通过两种解决方法:一是从特定网址下载Twisted安装包,二是通过conda命令行工具安装Scrapy。
创建Scrapy项目通常包括以下步骤:
1. 打开命令行工具。
2. 在指定的工作目录(此处为myScrapy)下创建一个名为qidian_hot的新项目,命令为`scrapy startproject qidian_hot myScrapy`。
3. 使用集成开发环境(如PyCharm)打开新创建的项目。
4. 在项目的`spiders`包内创建爬虫文件(例如`qidian_hot_spiders.py`)。
5. 在这个文件中编写Scrapy爬虫代码。
下面是一个简单的Scrapy爬虫代码示例,用于爬取起点中文网的热门销售书籍信息:
```python
# coding:utf-8
from scrapy import Request
from scrapy.spiders import Spider
class HotSalesSpider(Spider):
name = "hot" # 爬虫名称
start_urls = ["https://www.qidian.com/rank/hotsales?style=1&page=1"]
def parse(self, response):
# 数据解析,爬到的网页自动发给这个函数分析
list_selector = response.xpath("//div[@class='book-mid-info']")
for one_selector in list_selector:
# 获取小说信息
name = one_selector.xpath("h4/a/text()").extract()[0] # 获取书名
author = one_selector.xpath("p[1]/a[1]/text()").extract()[0] # 获取作者
type = one_selector.xpath("p[1]/a[2]/text()").extract()[0] # 获取类型
form = one_
```
在这个例子中,`HotSalesSpider`继承自Scrapy的`Spider`类,定义了爬虫的名称和起始URL。`parse`方法是默认的回调函数,用于处理每个请求返回的响应。XPath选择器被用来定位网页上的元素,提取所需信息,如书籍名称、作者和类型等。
Scrapy提供了一套完整的框架,使得开发者能够快速地构建、测试和维护网络爬虫。通过学习和掌握Scrapy,开发者可以高效地处理大量网页数据,为数据分析、市场研究、竞争情报等领域提供有力的支持。
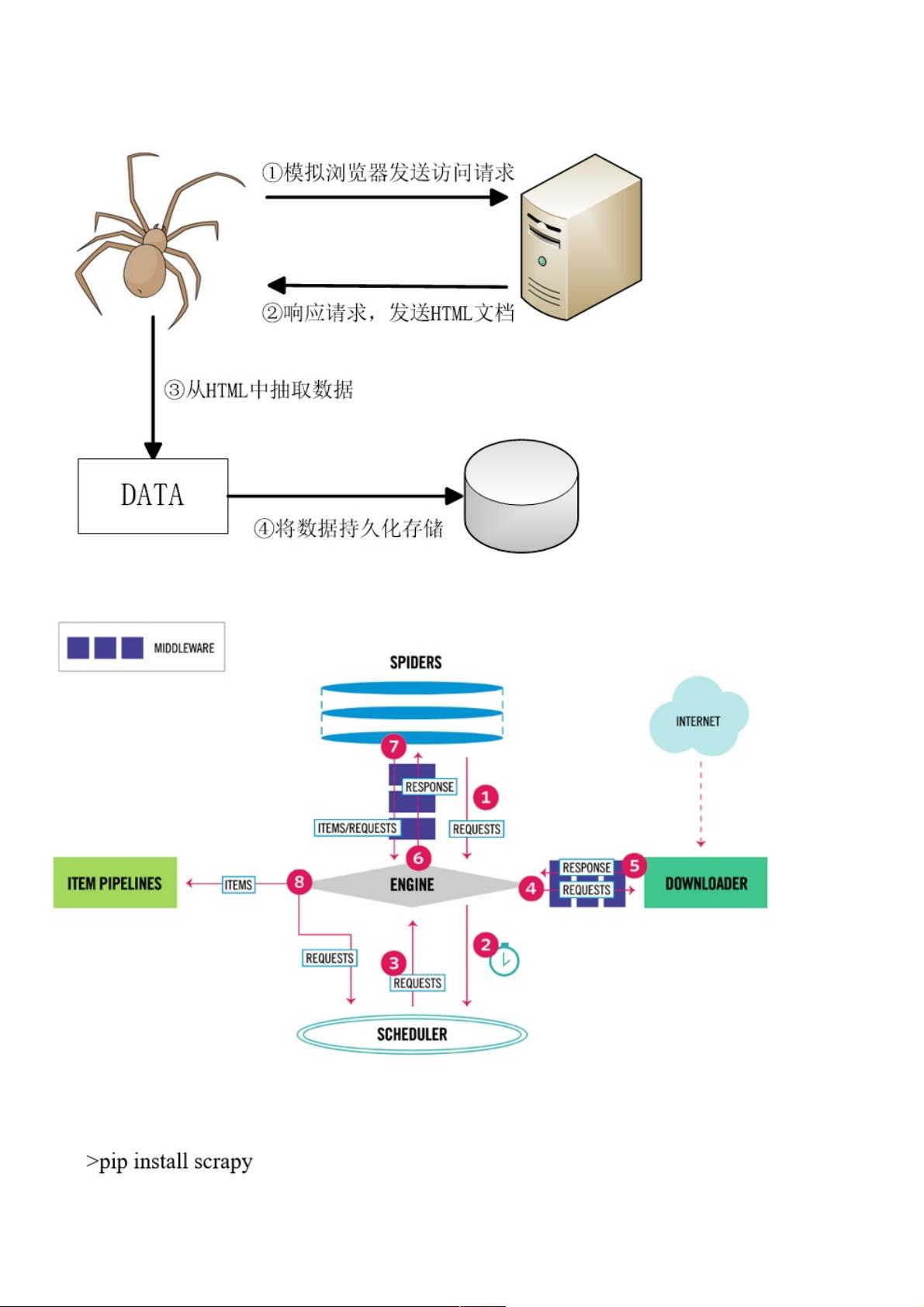
Scrapy爬虫爬虫 1
网络爬虫原理
Scrapy框架结构
爬虫步骤:需求分析->创建项目->分析页面->实现爬虫->运行爬虫
安装Scrapy
常见安装错误
下载后可阅读完整内容,剩余3页未读,立即下载
2024-04-26 上传
2022-06-12 上传
2021-06-19 上传
2023-06-08 上传
2023-04-05 上传
2023-05-26 上传
2023-05-13 上传
2023-03-04 上传
2023-05-27 上传

weixin_38653602
- 粉丝: 6
- 资源: 937
 我的内容管理
展开
我的内容管理
展开







最新资源
- OptiX传输试题与SDH基础知识
- C++Builder函数详解与应用
- Linux shell (bash) 文件与字符串比较运算符详解
- Adam Gawne-Cain解读英文版WKT格式与常见投影标准
- dos命令详解:基础操作与网络测试必备
- Windows 蓝屏代码解析与处理指南
- PSoC CY8C24533在电动自行车控制器设计中的应用
- PHP整合FCKeditor网页编辑器教程
- Java Swing计算器源码示例:初学者入门教程
- Eclipse平台上的可视化开发:使用VEP与SWT
- 软件工程CASE工具实践指南
- AIX LVM详解:网络存储架构与管理
- 递归算法解析:文件系统、XML与树图
- 使用Struts2与MySQL构建Web登录验证教程
- PHP5 CLI模式:用PHP编写Shell脚本教程
- MyBatis与Spring完美整合:1.0.0-RC3详解
