内容反爬技术揭秘:以大众点评为例
"本文介绍了内容反爬技术,一种用于防止爬虫抓取网页数据的方法。内容反爬通过加密或替换网页内容来阻止爬虫获取有效信息,同时允许正常用户浏览。文章以大众点评为实例,展示了如何识别和解密经过内容反爬处理的数据。通过F12开发者工具分析,揭示了背景图像链接中的坐标与字典位置之间的关系,以及如何通过像素测量和文本长度计算来还原被替换的字符。"
内容反爬技术是针对爬虫的防御手段,旨在保护网站数据不被非法抓取。随着爬虫技术的发展,传统的反爬策略如IP限制、User-Agent检测等已经不够有效,因此内容反爬应运而生。这种技术通常涉及到对网页内容进行加密或替换,使得爬虫抓取到的数据无法直接使用。
在大众点评的例子中,内容反爬表现为将网页中的文字用<span>标签替换,并通过背景图像的坐标来隐藏真实内容。当用户正常访问时,浏览器能够根据这些坐标解析出正确的文字,而爬虫则无法理解其中的含义。例如,字符"的"被替换为<span>标签,其背景图像链接指向一个包含所有字符图像的字典文件。
通过分析,可以发现每个字符在字典中的位置与背景图像的坐标有关。坐标(-406.0px,-877.0px)可能对应字典中的某一行,而xlink:href="#30"中的数字30可能代表该行的索引。通过测量字典图像的尺寸,可以推断出每个字符的位置,结合<span>标签的宽度和高度,可以定位到具体的字符图像。
此外,注意到字典中每一行的textLength属性值随着字符串长度变化,这提示我们可以根据字符的位置和字典的宽度来计算字符在字符串中的位置。在这个例子中,"的"位于第30行,且根据文本长度和单个字符宽度可以确定其在字符串中的确切位置。
总结来说,内容反爬技术通过复杂的编码和隐藏机制来防止爬虫抓取数据。要解密这些内容,需要深入理解网页结构,利用开发者工具分析HTML和CSS,以及可能涉及的图像处理和坐标系统。这展示了反爬与爬虫之间不断升级的技术较量,同时也提醒我们在进行网络数据采集时需要遵守道德和法规,尊重网站的反爬策略。
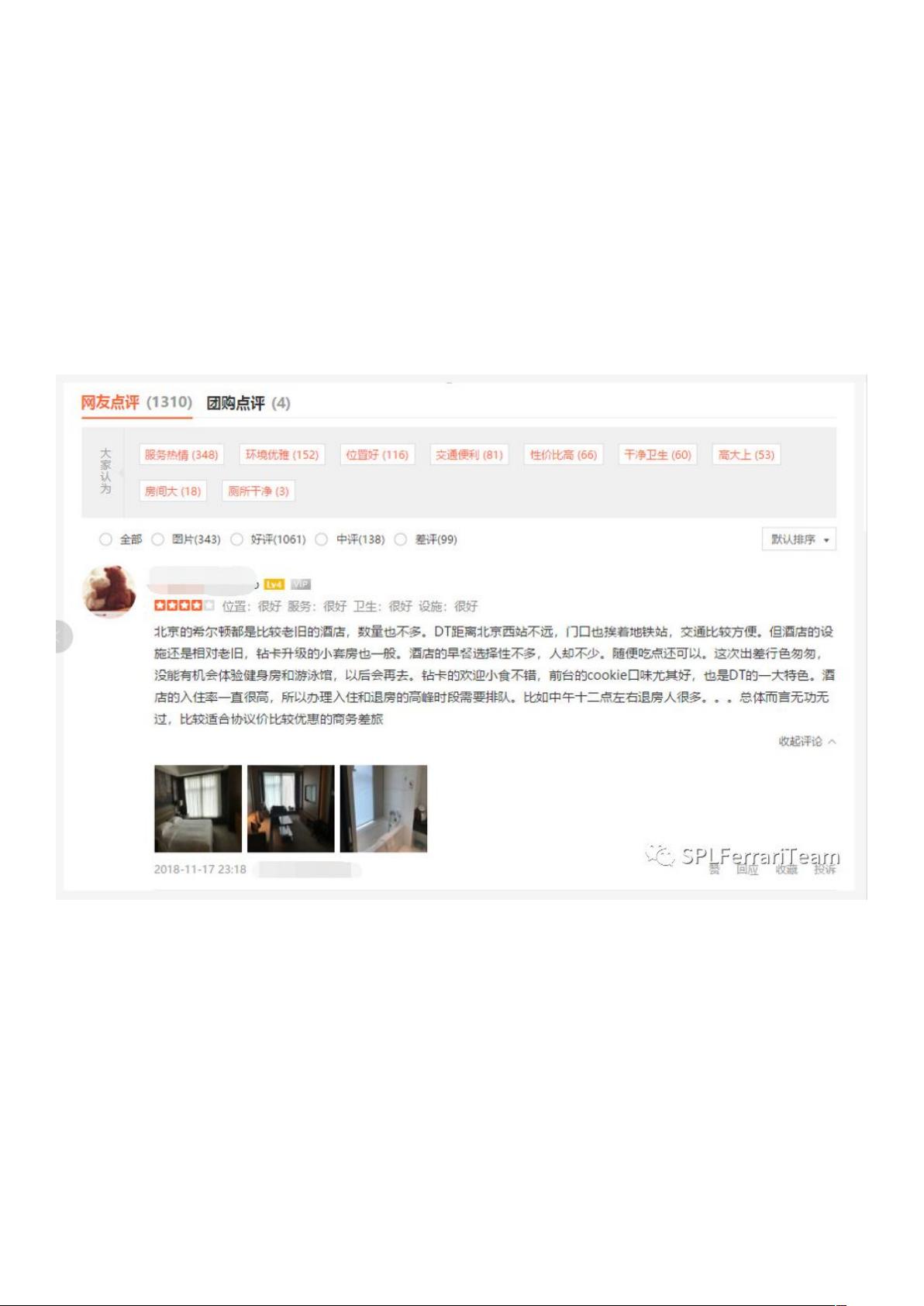
前言:爬虫是一种按照某种特定的规则,自动抓取万维网信息的程序或者脚本。反爬
虫是运用各种技术阻止爬虫抓取数据的同时还能让正常用户获取数据。随着爬虫技术进步,
程序很难能完全分辨出请求者是否为爬虫,由此反爬虫技术衍生出了一个新的分支 ---内
容反爬。
内容反爬:采取内容加密的方式来“污染”爬虫下载的数据。本文以大众点评为例,给
大家分享一下内容反爬相关的知识。
上图为一个商户的点评页面,从表面上看并看不出来什么异常。但是当你把网页存储下来
的时候会发现,中间的某些字被一些字符给替换掉了。
下载后可阅读完整内容,剩余4页未读,立即下载
2018-04-23 上传
2023-03-01 上传
2023-05-30 上传
2023-04-04 上传
2023-05-29 上传
2023-06-08 上传
2024-05-07 上传

hyy80688
- 粉丝: 10
- 资源: 202
 我的内容管理
展开
我的内容管理
展开







最新资源
- 达梦数据库DM8手册大全:安装、管理与优化指南
- Python Matplotlib库文件发布:适用于macOS的最新版本
- QPixmap小demo教程:图片处理功能实现
- YOLOv8与深度学习在玉米叶病识别中的应用笔记
- 扫码购物商城小程序源码设计与应用
- 划词小窗搜索插件:个性化搜索引擎与快速启动
- C#语言结合OpenVINO实现YOLO模型部署及同步推理
- AutoTorch最新包文件下载指南
- 小程序源码‘有调’功能实现与设计课程作品解析
- Redis 7.2.3离线安装包快速指南
- AutoTorch-0.0.2b版本安装教程与文件概述
- 蚁群算法在MATLAB上的实现与应用
- Quicker Connector: 浏览器自动化插件升级指南
- 京东白条小程序源码解析与实践
- JAVA公交搜索系统:前端到后端的完整解决方案
- C语言实现50行代码爱心电子相册教程
