揭秘Spark Shuffle:性能优化关键与实现机制
189 浏览量
更新于2024-08-30
收藏 204KB PDF 举报
在Spark源码系列的第六篇文章中,作者深入剖析了Shuffle这一关键操作在Spark中的重要性及其对性能的影响。Shuffle是Spark基于RDD操作模型中的核心步骤,特别是当执行诸如`reduceByKey`、`groupByKey`等聚合操作时,会触发数据的重新分布和计算。这些操作的核心在于将数据集按照键值对进行划分,然后将相同键的值进行聚合。
首先,作者指出在`reduceByKey`函数中,用户可以指定分区的数量(`numPartitions`),这是为了控制数据的并行处理程度。如果不指定,Spark会根据默认规则或配置自动决定分区数量。具体来说:
1. 如果用户自定义了分区函数`partitioner`,则会按照该函数进行数据划分。
2. 如果没有自定义分区,Spark会根据`spark.default.parallelism`的配置来决定,这是用户设置的默认并行度。
3. 若`spark.default.parallelism`也没有设置,那么就会使用输入数据本身的分片数量,这在处理Hadoop输入数据时尤为重要,因为可能涉及到额外的逻辑处理。
Shuffle过程本身包括以下几个步骤:
- 数据划分:原始RDD的元素会被分配到不同的分区中,每个分区负责一部分键值对。
- 数据交换:分区之间的数据通过网络进行交换,确保具有相同键的值聚集在一起。
- 聚合计算:接收数据的分区对相同键的值进行`func`函数的聚合操作。
- 结果合并:各个分区的聚合结果被收集起来,形成最终的键值对结果。
整个过程对于Spark性能至关重要,因为它决定了数据的分布策略和通信开销。理解并优化Shuffle操作有助于提高Spark应用程序的运行效率和吞吐量,尤其是在大数据处理场景下。因此,掌握Shuffle的工作原理对于开发Spark应用的工程师来说是必不可少的技能。
Spark源码系列(六)源码系列(六)Shuffle的过程解析的过程解析
Spark大会上,所有的演讲嘉宾都认为shuffle是最影响性能的地方,但是又无可奈何。之前去百度面试hadoop的时候,也被问
到了这个问题,直接回答了不知道。这篇文章主要是沿着下面几个问题来开展:shuffle过程的划分?shuffle的中间结果如何存
储?shuffle的数据如何拉取过来?
Shuffle过程的划分
Spark的操作模型是基于RDD的,当调用RDD的reduceByKey、groupByKey等类似的操作的时候,就需要有shuffle了。再拿
出reduceByKey这个来讲。
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)] = {
reduceByKey(new HashPartitioner(numPartitions), func)
}
reduceByKey的时候,我们可以手动设定reduce的个数,如果不指定的话,就可能不受控制了。
def defaultPartitioner(rdd: RDD[_], others: RDD[_]*): Partitioner = {
val bySize = (Seq(rdd) ++ others).sortBy(_.partitions.size).reverse
for (r <- bySize if r.partitioner.isDefined) {
return r.partitioner.get
}
if (rdd.context.conf.contains("spark.default.parallelism")) {
new HashPartitioner(rdd.context.defaultParallelism)
} else {
new HashPartitioner(bySize.head.partitions.size)
}
}
如果不指定reduce个数的话,就按默认的走:
1、如果自定义了分区函数partitioner的话,就按你的分区函数来走。
2、如果没有定义,那么如果设置了spark.default.parallelism,就使用哈希的分区方式,reduce个数就是设置的这个值。
3、如果这个也没设置,那就按照输入数据的分片的数量来设定。如果是hadoop的输入数据的话,这个就多了。。。大家可要
小心啊。
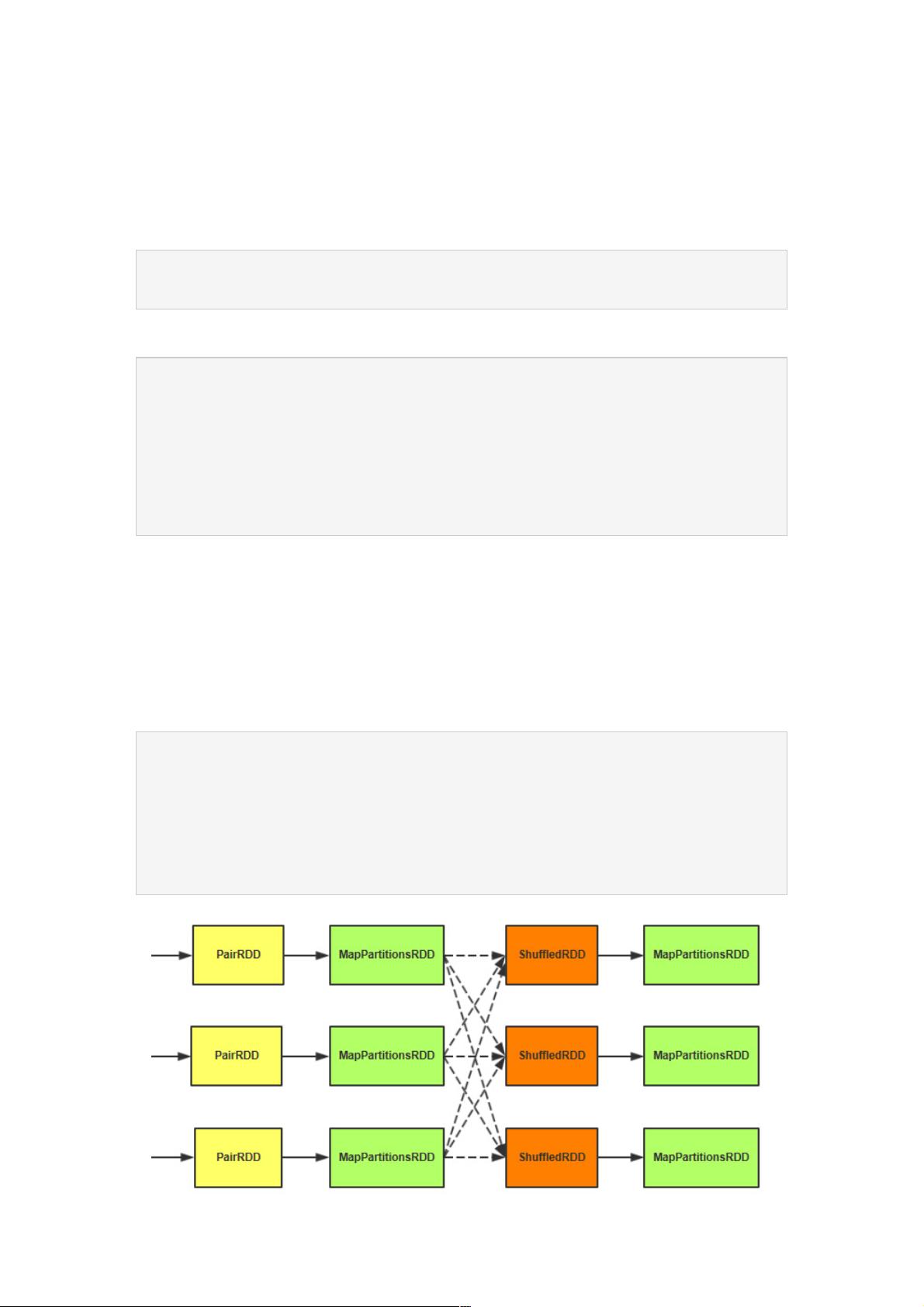
设定完之后,它会做三件事情,也就是之前讲的3次RDD转换。
//map端先按照key合并一次
val combined = self.mapPartitionsWithContext((context, iter) => {
aggregator.combineValuesByKey(iter, context)
}, preservesPartitioning = true)
//reduce抓取数据
val partitioned = new ShuffledRDD[K, C, (K, C)](combined, partitioner).setSerializer(serializer)
//合并数据,执行reduce计算
partitioned.mapPartitionsWithContext((context, iter) => {
new InterruptibleIterator(context, aggregator.combineCombinersByKey(iter, context))
}, preservesPartitioning = true)
1、在第一个MapPartitionsRDD这里先做一次map端的聚合操作。
下载后可阅读完整内容,剩余6页未读,立即下载
158 浏览量
610 浏览量
861 浏览量
113 浏览量
162 浏览量
124 浏览量
345 浏览量
110 浏览量
250 浏览量

weixin_38729269
- 粉丝: 4
- 资源: 851
 我的内容管理
展开
我的内容管理
展开







最新资源
- saturn::globe_with_meridians:新的迷你快速浏览器
- 企业前台大厅模型设计
- 基于python+django+vue开发的工作数据获取与可视化
- NodeJS-Sample-Project:使用Express的节点Js上的样本项目,具有基本结构和数据库连接
- 战利品
- myBinomTest(s,n,p,Sided):具有任意二项式概率的 1 或 2 边二项式检验-matlab开发
- 银行存款余额调节表格excel模版下载
- 演唱会舞台3D模型
- autoprop:从访问器方法推断属性
- ABAssignment04
- 物品交接明细表excel模版下载
- desafio_conceitos_node
- vewa_app2:VEWA 网络应用程序
- 中式现代风会议室模型
- gritjz.github.io:史蒂芬·张的个人网站
- 工程质量验收记录表excel模版下载
