suCAQR:利用TBLAS框架的高效通信避免QR分解求解器
本文主要探讨的是"A Simplified Communication-Avoiding QR Factorization Solver Using the TBLAS Framework"这一主题,它关注于设计并实现一个能够在现代超级计算机上针对不同形状(包括高维和稀疏)矩阵提供最快速度的可扩展QR分解求解器。作者们,Weijian Zheng、Fengguang Song、Lan Lin和Zizhong Chen来自不同的大学计算机科学部门,他们共同开发了名为suCAQR(可扩展的通用通信避免QR分解)的新算法。
传统QR分解是一种线性代数中的基础工具,用于将矩阵分解为一个正交矩阵和一个上三角矩阵,这对于数据处理、特征值分析以及机器学习等领域至关重要。然而,随着大数据和高性能计算的发展,通信开销成为性能瓶颈,特别是对于大规模稀疏矩阵。为了解决这个问题,作者们提出了suCAQR,旨在通过TBLAS(Thread Building Blocks Library)框架简化算法设计,减少通信量,并优化物理和逻辑数据布局。
TBLAS是一个库,它提供了并行计算的底层抽象,使得开发者能够更容易地在多核处理器和GPU上实现高效的计算。suCAQR的设计策略包括动态根二进制树减少方法,这是一种简化了的策略,可以降低因树状数据结构导致的通信复杂性。此外,动态数据流实施也是其关键特性,它根据任务需求调整数据流动,进一步提高效率。
相比于现有的通信避免QR分解实现,suCAQR的优势在于其对各种矩阵形状的适应性,无需复杂的调优过程,就能在处理高维和稀疏矩阵时提供一致的高性能。通过混合使用物理和逻辑数据布局,算法能够充分利用内存层次结构,减少不必要的数据移动,从而显著提升计算性能。作者们的目标是让读者不仅理解传统的理论概念,还能看到抽象代数与数论、几何学之间的实际应用,并能通过实践掌握计算和证明技巧,享受学习抽象代数的过程。
这篇论文不仅关注理论教学,还展示了如何将抽象代数理论应用于实际问题解决,特别是在高性能计算环境中的矩阵分解,这在IT教育和科研中具有重要意义。
suCAQR: A Simplified Communication-Avoiding
QR Factorization Solver Using the TBLAS
Framework
Weijian Zheng and Fengguang Song
Department of Computer Science
Indiana University Purdue University Indianapolis
Email: {wz26, fgsong}@iupui.edu
Lan Lin
Department of Computer Science
Ball State University
Email: llin4@bsu.edu
Zizhong Chen
Department of Computer Science
University of California at Riverside
Email: chen@cs.ucr.edu
Abstract—The scope of this paper is to design and implement
a scalable QR factorization solver that can deliver the fastest
performance for tall and skinny matrices and square matrices on
modern supercomputers. The new solver, named scalable univer-
sal communication-avoiding QR factorization (suCAQR), introduces
a simplified and tuning-less way to realize the communication-
avoiding QR factorization algorithm to support matrices of any
shapes. The software design includes a mixed usage of physical
and logical data layouts, a simplified method of dynamic-root
binary-tree reduction, and a dynamic dataflow implementation.
Compared with the existing communication avoiding QR fac-
torization implementations, suCAQR has the benefits of being
simpler, more general, and more efficient. By balancing the
degree of parallelism and the proportion of faster computational
kernels, it is able to achieve scalable performance on clusters of
multicore nodes. The software essentially combines the strengths
of both synchronization-reducing approach and communication-
avoiding approach to achieve high performance. Based on the
experimental results using 1,024 CPU cores, suCAQR is faster
than DPLASMA by up to 30%, and faster than ScaLAPACK by
up to 30 times.
Index Terms—high performance computing; computational
science application; performance analysis and optimization;
dataflow runtime system.
I. INTRODUCTION
QR factorization is a fundamental computational kernel for
many important scientific, engineering, and big data analytics
applications. It has been applied to solving linear systems,
least-squares problems, linear regression problems, and the
production function modeling, as well as assessing the con-
ditioning of these problems [1]–[3]. The QR factorization of
a matrix A of dimension m × n (m ≥ n) takes the form of
A = QR, where Q is an m × m orthogonal matrix, and R
(=Q
T
A) is an upper triangular matrix with zeros below its
diagonal. The design and implementation of more scalable
QR factorizations will accelerate a wide range of domain
applications.
The most widely used parallel algorithm to solve QR
factorizations is the block QR factorization algorithm used
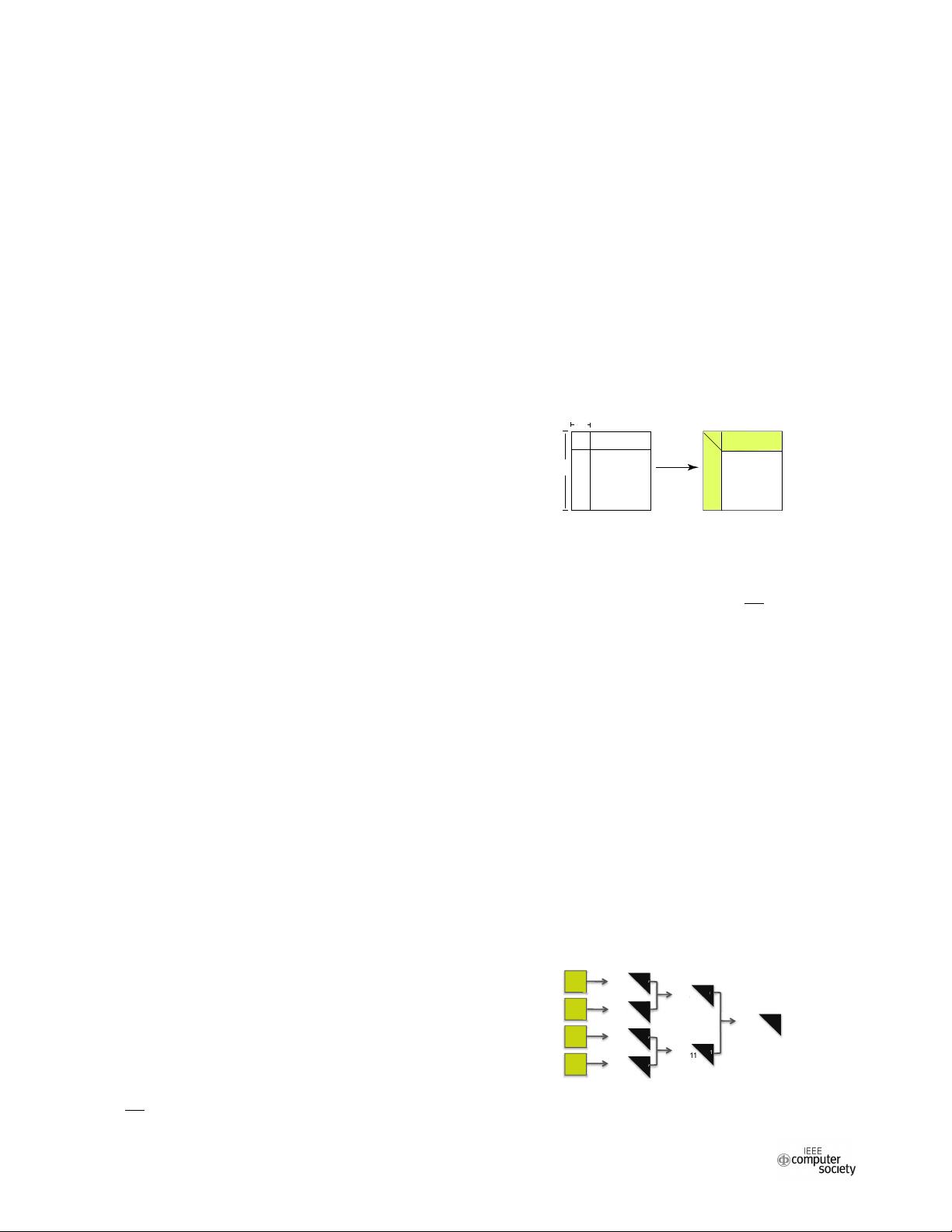
by the de facto standard ScaLAPACK library [4], [5]. As
displayed in Figure 1, matrix A is divided into a thin panel
(i.e.,
A
11
A
21
) of dimension M × NB, a block of rows A
12
, and
R11
V21
R12
A22
A11
A21
A12
A22
M
NB
Fig. 1. The classic block QR factorization algorithm used by ScaLAPACK.
a trailing submatrix A
22
. The block algorithm first applies
level 1 PBLAS subroutines to the panel (
A
11
A
21
), next it forms
the triangular factor from the panel, finally it uses level 3
PBLAS to factor A
12
and update A
22
. However, since the
panel is computed one column after another—resulting in a
large communication overhead and surface-to-volume ratio —
the block algorithm does not scale well for tall and skinny
matrices (i.e., matrices with much more rows than columns).
To reduce the large communication overhead with tall and
skinny matrices, Demmel et al. then designed an algorithm
called Communication-Avoiding QR factorization (CAQR) [6]–
[8]. As explained in Figure 2, instead of computing a sequence
of column-by-column operations, CAQR can perform a set of
level 3 BLAS operations in the panel. Then it merges the
output of the level 3 BLAS operations to get the final factor
R. Not only does the algorithm convert level 1 BLAS to
level 3 BLAS, but also it significantly reduces the number of
communication messages. The original work of Demmel et al.
[6] offered an estimated performance speedup of CAQR. Later,
Song et al. [9] developed the first parallel implementation of
CAQR, which is referred to as distributed tiled CAQR [9].
A
0
A
1
A
2
A
3
Q
00
Q
00
R
00
Q
10
Q
1
0
R
10
Q
20
Q
20
R
20
Q
30
Q
30
R
30
0
0
0
0
0
0
0
0
0
0
0
Q
01
Q
01
R
01
Q
11
Q
1
1
R
11
01
1
1
1
Q
02
Q
02
R
02
Fig. 2. Communication-Avoiding QR (CAQR) performs level 3 BLAS on the
panel (i.e., A
0
, A
1
, A
2
, A
3
) followed by a parallel reduction.
2016 IEEE 22nd International Conference on Parallel and Distributed Systems
1521-9097/16 $31.00 © 2016 IEEE
DOI 10.1109/ICPADS.2016.142
1092
下载后可阅读完整内容,剩余7页未读,立即下载
2021-05-24 上传
2019-08-16 上传
2019-05-16 上传
2021-05-22 上传
2020-02-09 上传
2021-05-03 上传

zwj3652014
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索AVL树算法:以Faculdade Senac Porto Alegre实践为例
- 小学语文教学新工具:创新黑板设计解析
- Minecraft服务器管理新插件ServerForms发布
- MATLAB基因网络模型代码实现及开源分享
- 全方位技术项目源码合集:***报名系统
- Phalcon框架实战案例分析
- MATLAB与Python结合实现短期电力负荷预测的DAT300项目解析
- 市场营销教学专用查询装置设计方案
- 随身WiFi高通210 MS8909设备的Root引导文件破解攻略
- 实现服务器端级联:modella与leveldb适配器的应用
- Oracle Linux安装必备依赖包清单与步骤
- Shyer项目:寻找喜欢的聊天伙伴
- MEAN堆栈入门项目: postings-app
- 在线WPS办公功能全接触及应用示例
- 新型带储订盒订书机设计文档
- VB多媒体教学演示系统源代码及技术项目资源大全
