解决维度灾难:特征提取与降维在机器学习中的关键
版权申诉
本章节讨论的主题是“媒体与认知”中的“模式与特征”,主要集中在第三章。这一部分深入探讨了机器学习中面临的“维度灾难”问题,即随着特征维度的增加,为了保持给定精度下的估计准确性,所需的训练样本数量会呈指数级增长。这意味着在实际应用中,当数据集的维度较高时,即使样本数量充足,也难以有效地进行模型训练和泛化到新的数据。
1. **特征提取**:
- 该部分介绍了如何从原始数据中提取关键特征,这些特征能够帮助机器学习算法理解数据的本质属性。有效的特征提取有助于减少冗余信息,提高模型的性能。
2. **特征降维**:
- 特征降维是解决维度灾难的重要策略。通过将高维特征映射到低维空间,如主成分分析(PCA)、线性判别分析(LDA)等方法,可以降低模型对样本数量的依赖。降维不仅可以减少存储空间,还能突出数据的主要变化方向,消除噪声,增强模型的泛化能力。
- 在数学表达式中,通过矩阵运算将原始特征矩阵(X)投影到较低维度(k<p)的特征空间(Z),如 \( Z = \frac{1}{n}\sum_{i=1}^{n}(x_i - \bar{x})(x_i - \bar{x})^T \),其中\( n \)是样本数,\( x_i \)是第i个样本,\( \bar{x} \)是均值向量。
3. **维数灾难的影响**:
- 过拟合是维度灾难的一个后果,随着维度增加,模型可能会在训练集上表现出极好的性能,但在新数据上的泛化能力却减弱。这是因为有限的训练样本在高维空间中变得稀疏,导致模型不能捕捉到数据的真实分布。
4. **特征降维的意义**:
- 特征降维不仅是为了克服维数灾难,还在于它能提取出对分类识别最为关键的少数特征,这有利于简化模型,提高效率,并且有助于数据可视化,使人们更容易理解和解释模型决策的过程。
本章的核心内容围绕着如何处理媒体和认知数据中的特征维度问题,通过特征提取和降维技术来优化机器学习模型的性能,特别是在处理高维数据时,以确保模型的稳定性和有效性。这对于实际的互联网应用和数据分析至关重要。
02
x
x
L
022
y
y
L
yx ;
2
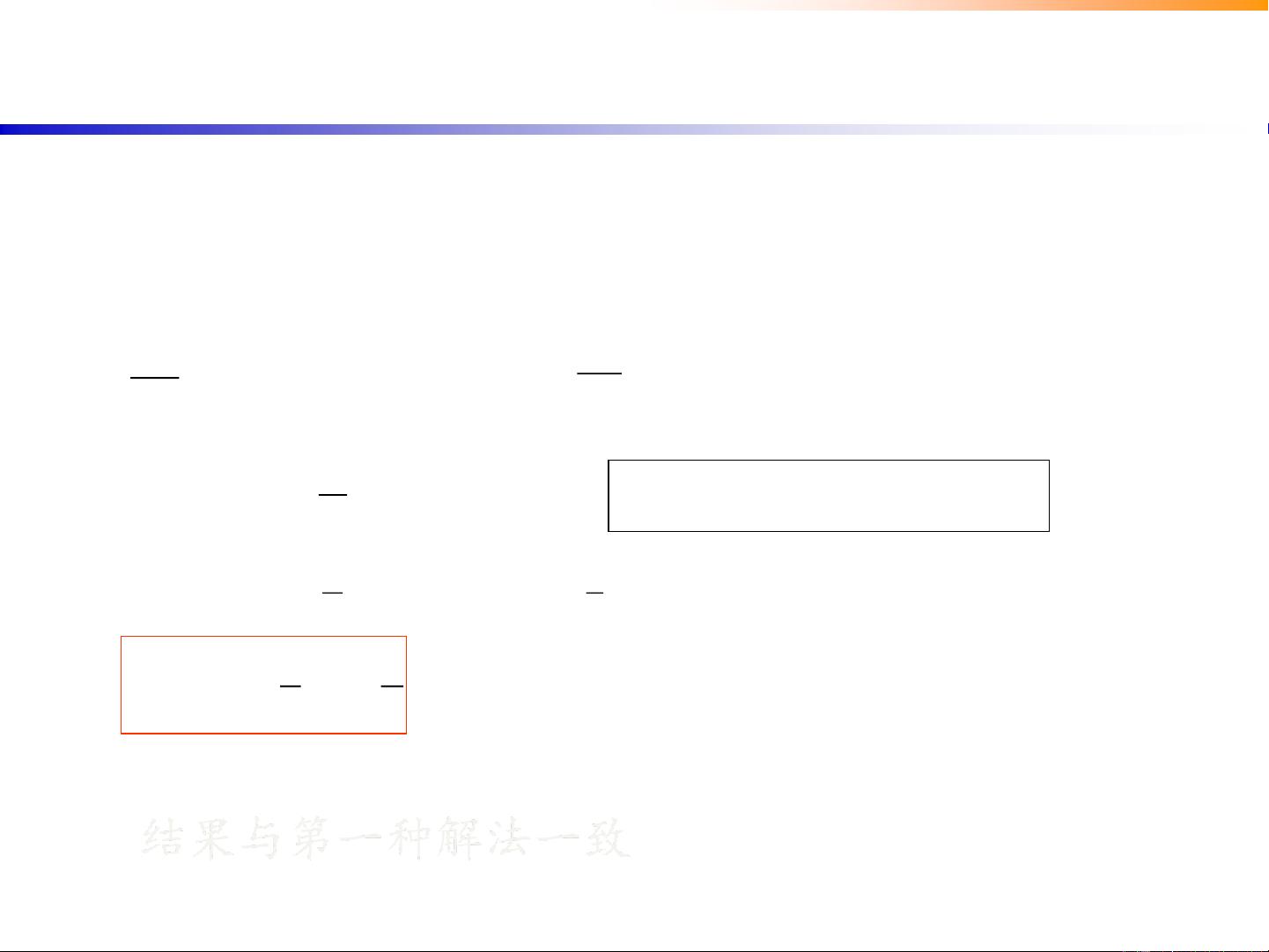
解得:
5
2
-1;2-
2
解得带入约束方程
12
x;
55
y解得:
12),(),(
22
yxyxyxGyxfL
构造拉格朗日函数
12 yx约束条件:
结果与第一种解法一致
数学基础:拉格朗日乘子法


剩余88页未读,继续阅读
2022-06-29 上传
2022-06-29 上传
2021-09-19 上传
2021-09-19 上传
2022-06-29 上传
2021-09-19 上传
2021-05-20 上传
2021-04-08 上传

智慧安全方案
- 粉丝: 3789
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
