基于SVM的应用驱动数据流分类框架应对挑战
174 浏览量
更新于2024-08-27
收藏 882KB PDF 举报
在现代信息技术领域,随着数据流在诸如网络监控、物联网分析、网页点击流挖掘、能源消耗测量和金融市场动态追踪等广泛应用中的重要性日益增长,数据流分类已经成为数据挖掘研究的关键课题。近年来,数据流分类面临的主要挑战包括概念漂移(concept drift)、大数据量以及部分标注(partial labeling)。
首先,概念漂移是指数据流中的数据分布随时间变化,导致原有的分类模型不再适用。这要求分类算法具有适应性,能够自动检测和适应新的数据分布模式。传统的静态模型在这种情况下往往表现不佳,因此研究者们寻求通过转移学习(transfer learning)来解决这个问题。转移学习允许算法在新概念出现时,利用先前学习到的知识来加速新概念的学习过程。
其次,大规模数据流的处理带来了计算效率和存储空间的压力。为了应对这一挑战,研究人员提出结合经典支持向量机(SVM)、半监督学习方法(如半监督SVM)和关系K-means等技术。半监督学习利用少量标记数据和大量未标记数据进行训练,有助于在有限标注情况下提高模型的泛化能力。而关系K-means则利用数据内在的结构信息,通过聚类算法将相似的数据分组,从而更有效地处理复杂数据。
本文提出了一种基于SVM的数据流分类框架,它巧妙地融合了这些策略。该框架首先对数据流中的数据进行动态划分,识别出四种类型:同概念的已标记数据、不同概念的已标记数据、同概念的未标记数据以及未标记数据。这种分类有助于区分当前概念与历史概念,并利用它们之间的关联进行学习。通过这种方法,即使在面对不断变化的概念和大量未标注数据时,也能保持模型的稳定性和准确性。
在实际应用中,作者通过在真实数据流上的实验验证了这个框架的有效性。结果显示,该模型不仅能够有效处理概念漂移,而且在面对大规模数据和部分标注的情况下,相较于传统方法,显示出更好的性能和鲁棒性。这一研究成果对于推动数据流分类技术在实际场景中的应用具有重要意义,为未来的研究提供了新的方向和方法论支持。
Theorem 1. Let L
1
, L
2
, L
3
and L
4
be the number of examples of Type I,
Type II, Type III and Type IV respectively in the up-to-date chunk.
Then
L
1
p
g
c
1
l n
L
2
pð1
g
c
1
Þl n
L
3
p
g
c
1
ð1lÞn
L
4
pð1
g
c
1
Þð1lÞn ð1Þ
where
g
4 0 is a constant coefficient.
Proof. Recall that stream S flows at a speed of n examples
per second, the concept drifting probability is c, and the labeling
rate is l. The number of target domain examples is inversely
proportional to the concept drifting rate c with a coefficient of
g
,
so it can be easily estimated that
g
c
1
n examples in the up-to-
date chunk have the same distribution as the testing data.
The remaining ð1
g
c
1
Þn examples have a similar distribution
to the testing examples. From the estimates the theorem follows
immediately. &
Learning priority: Not all the four types of training examples
have to be used in model construction. For example, consider a
data stream where the concept drifting is low and the labeling
rate is high, the training chunk will have a large portion of Type I
examples. In this case, we are able to build a satisfactory model by
training only on the Type I examples. We observe that the four
types of training examples have the following learning priorities.
Observation 1. The learning priority of the four types of training
examples is
Type I 4 Type III4 Type II 4 Type IV ð2Þ
What is the intuition behind Observation 1? Generally, exam-
ples from the target domain (Types I and III) are capable of
capturing the genuine concept of the testing data, and thus have a
high priority than examples from similar domains (Types II
and IV). Besides, since Type I examples are labeled, they have a
higher priority than Type III examples. Similarly, Type II examples
have a higher priority than Type IV examples.
Based on Observation 1, when a particular type dominates the
training examples, examples with lower priorities will not be
used for training. For example, if Type III dominates the training
examples, only Type I and Type III examples will be used for
training. This is because Type I examples have a higher priority
than Type III examples, and the remaining two types have lower
priorities. By doing so, we gain in efficiency by building a simple
model, comparing to a very complex model if we have to learn
from all four types of training examples. On the other hand, the
most informative examples are utilized in model construction and
the learning accuracy is not sacrificed.
Learning cases: Aiming at both accuracy and efficiency in
learning prediction models, we categorize learning from data
streams into the following four cases:
Case 1: Type I dominates. When labeling rate is high and the
concept drifting probability is low, Type I dominates the
training examples. In this case, we can train a satisfactory
model by using only Type I examples.
Case 2: Type III dominates. When both labeling rate and
concept drifting probability are low, Type III dominates the
training examples. According to the learning priority, it is
necessary to combine both Type I and Type III examples for
training.
Case 3: Type II dominates. When both labeling rate and
concept drifting probability are high, Type II dominates the
training examples, and we will use Type I, Type II and Type III
examples for training.
Case 4: Type IV dominates. When labeling rate is low and the
concept drifting probability is high, Type IV dominates the
training examples. This is the most difficult case because most
examples are unlabeled and not from the target domain.
According to the learning priority, we need to use all the four
types of training examples for training.
These learning cases are further illustrated in Fig. 3.
3. Learning models
We have introduced the four learning cases. In this section, we
present their corresponding learning models.
Throughout the section, T
1
¼ðx
1
, y
1
Þ, ..., ðx
L
1
, y
L
1
Þ denotes the
set of Type I examples. T
2
¼fðx
L
1
þ 1
, y
L
1
þ 1
Þ, ..., ðx
L
, y
L
Þg denotes the
set of Type II examples, where L ¼ L
1
þL
2
. T
3
¼fx
L þ 1
, ..., x
L þ U
g
denotes the set of Type III examples, where U is the set of
unlabeled examples. T
4
¼fx
L þ U þ 1
, ..., x
L þ U þ N
g denotes the set of
Type IV examples, where N is the set of unlabeled examples.
3.1. Case 1: Type I dominates
In this case, Type I examples T
1
dominate the training chunk
and has the highest learning priority. Thus, only T
1
will be used
for training. Formally, to learn from T
1
¼fðx
1
, y
1
Þ, ..., ðx
L
1
, y
L
1
Þg,
a generic SVM model can be trained by maximizing the margin
II
IV
III
IV III
III
IV III
I
II
IV
III
I
III
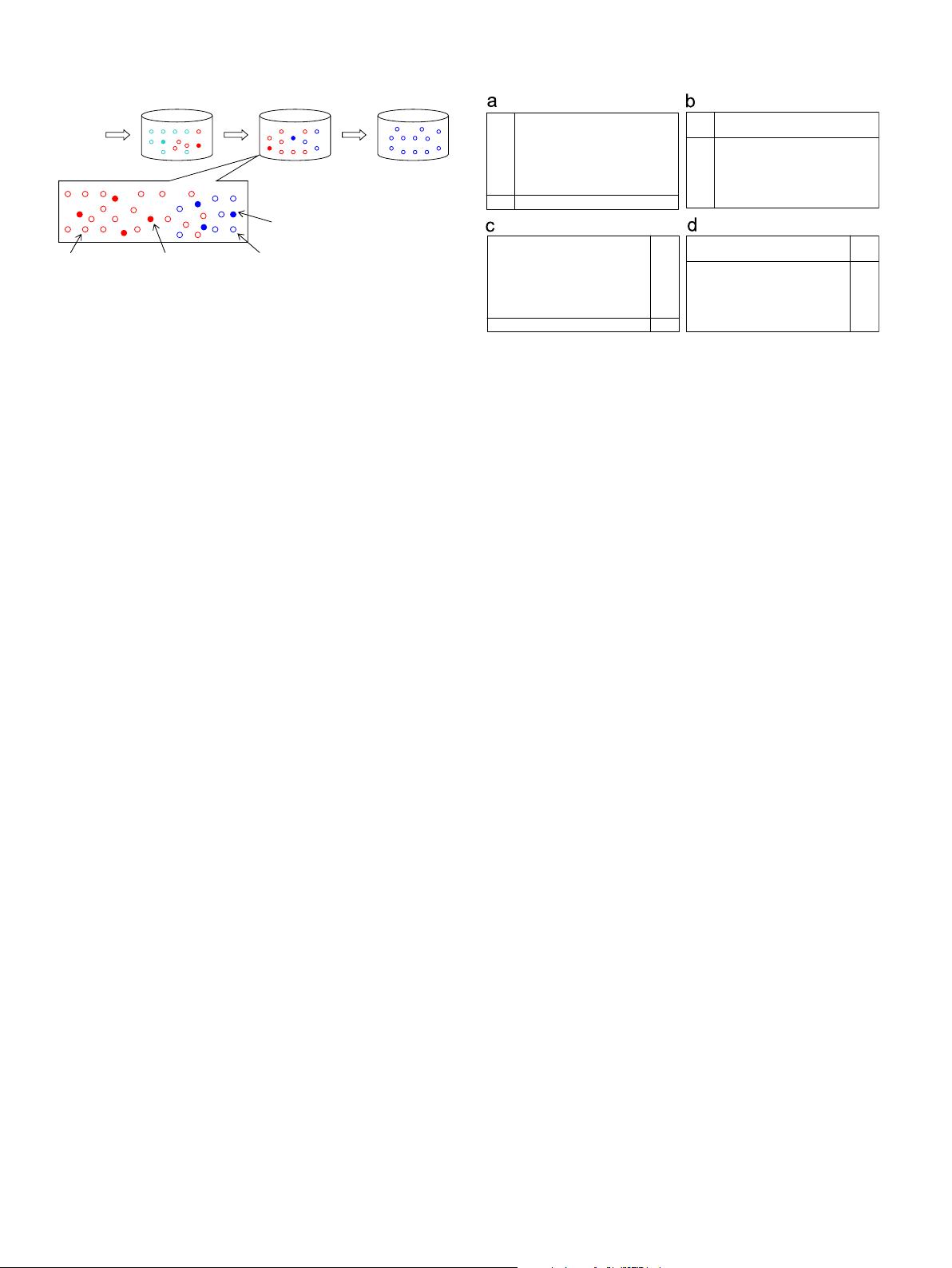
Fig. 3. The proportion of the four types of training examples with respect to
different labeling rate l and concept drifting probability c. (a) l is high and c is low.
Case 1, (b) both l and c are low. Case 2, (c) Both l and l are high. Case 3 and (d) l is
low and c is high. Case 4.
……
Type I
Type III
Type IV
T
y
pe II
Test chunk Training chunk
Up-to-date chunk Yet-to-come chunk Historical stream data
Fig. 2. An illustration of the four types of training examples in an up-to-date
training chunk. (For interpretation of the references to color in this figure legend,
the reader is referred to the web version of this article.)
P. Zhang et al. / Neurocomputing 92 (2012) 170–182172
剩余12页未读,继续阅读
2009-06-06 上传
2008-07-11 上传
2023-04-22 上传
2023-06-10 上传
2023-06-10 上传
2023-07-17 上传
2023-06-01 上传
2023-09-28 上传
2023-06-05 上传

weixin_38625599
- 粉丝: 8
- 资源: 867
 我的内容管理
展开
我的内容管理
展开







最新资源
- Flex垃圾回收与内存管理:防止内存泄露
- Python编程规范与最佳实践
- EJB3入门:实战教程与核心概念详解
- Python指南v2.6简体中文版——入门教程
- ANSYS单元类型详解:从Link1到Link11
- 深度解析C语言特性与实践应用
- Gentoo Linux安装与使用全面指南
- 牛津词典txt版:信息技术领域的便捷电子书
- VC++基础教程:从入门到精通
- CTO与程序员职业规划:能力提升与路径指南
- Google开放手机联盟与Android开发教程
- 探索Android触屏界面开发:从入门到设计原则
- Ajax实战:从理论到实践
- 探索Android应用开发:从入门到精通
- LM317T稳压管详解:1.5A可调输出,过载保护
- C语言实现SOCKET文件传输简单教程
