深度学习解析:阿尔法狗(AlphaGo)的胜利
需积分: 19 90 浏览量
更新于2024-07-20
1
收藏 2.07MB DOCX 举报
“阿法狗论文-alphago”是关于谷歌DeepMind团队开发的围棋人工智能程序AlphaGo的详细研究报告。这篇论文以Word文档的形式提供,旨在为研究者和感兴趣的人士提供深入理解AlphaGo工作原理的资料。
AlphaGo是人工智能领域的一个里程碑,它在2015年首次击败了欧洲围棋冠军樊辉(Fan Hui,2段),并随后在2016年以5比0的战绩战胜了世界围棋冠军李世石(Lee Sedol,9段)。这些比赛引起了全球关注,展示了人工智能在复杂策略游戏中的卓越能力。
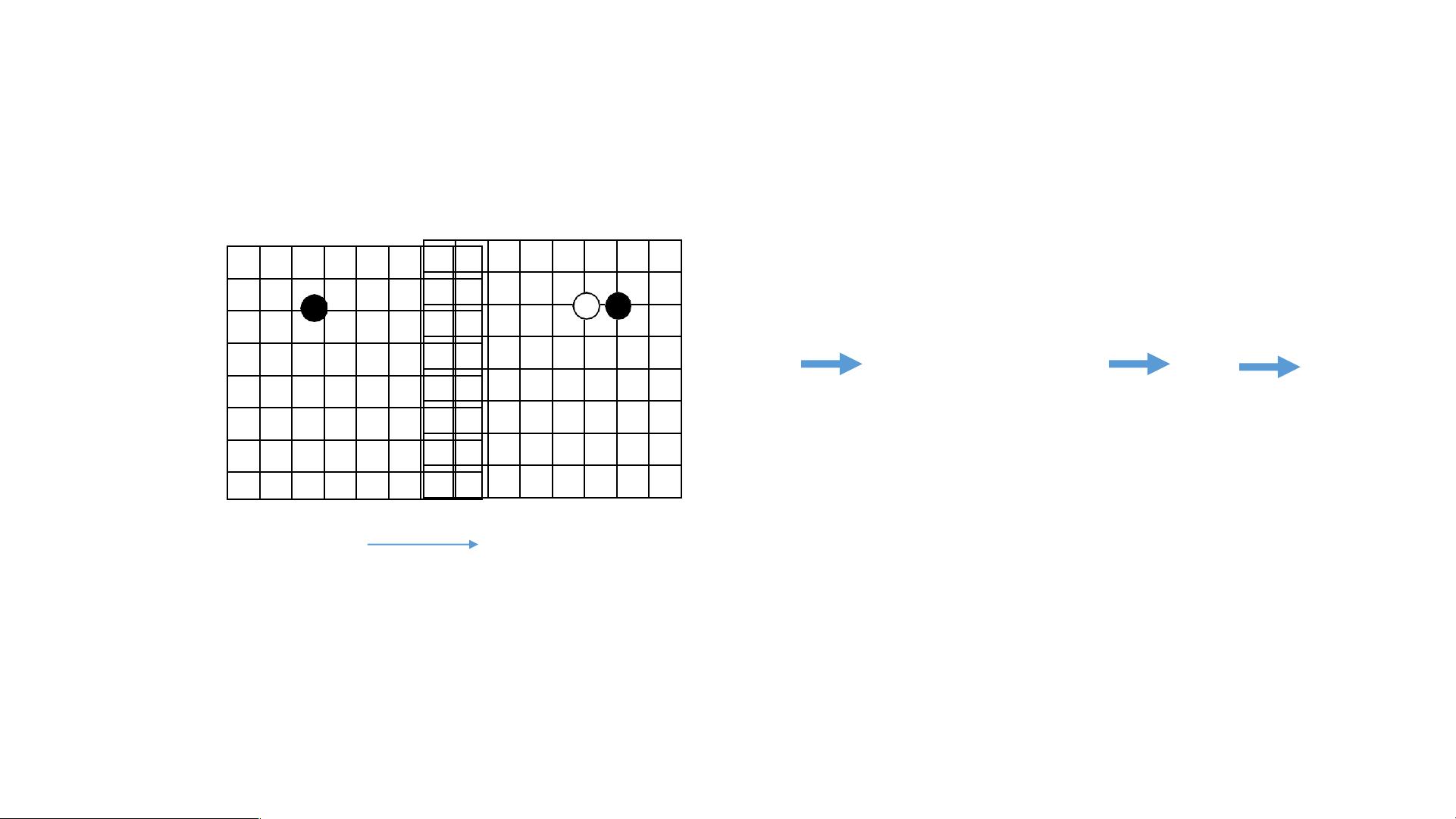
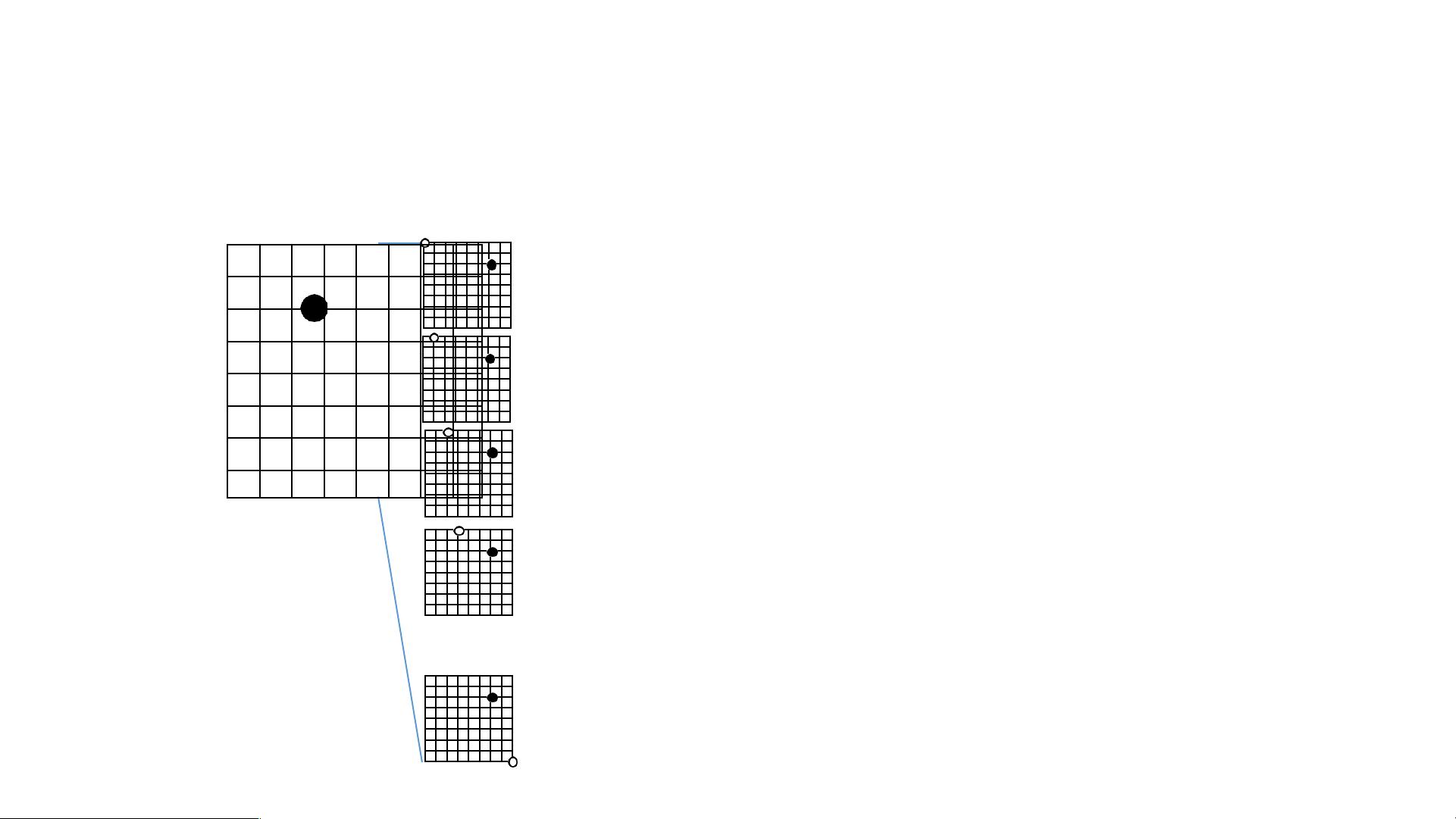
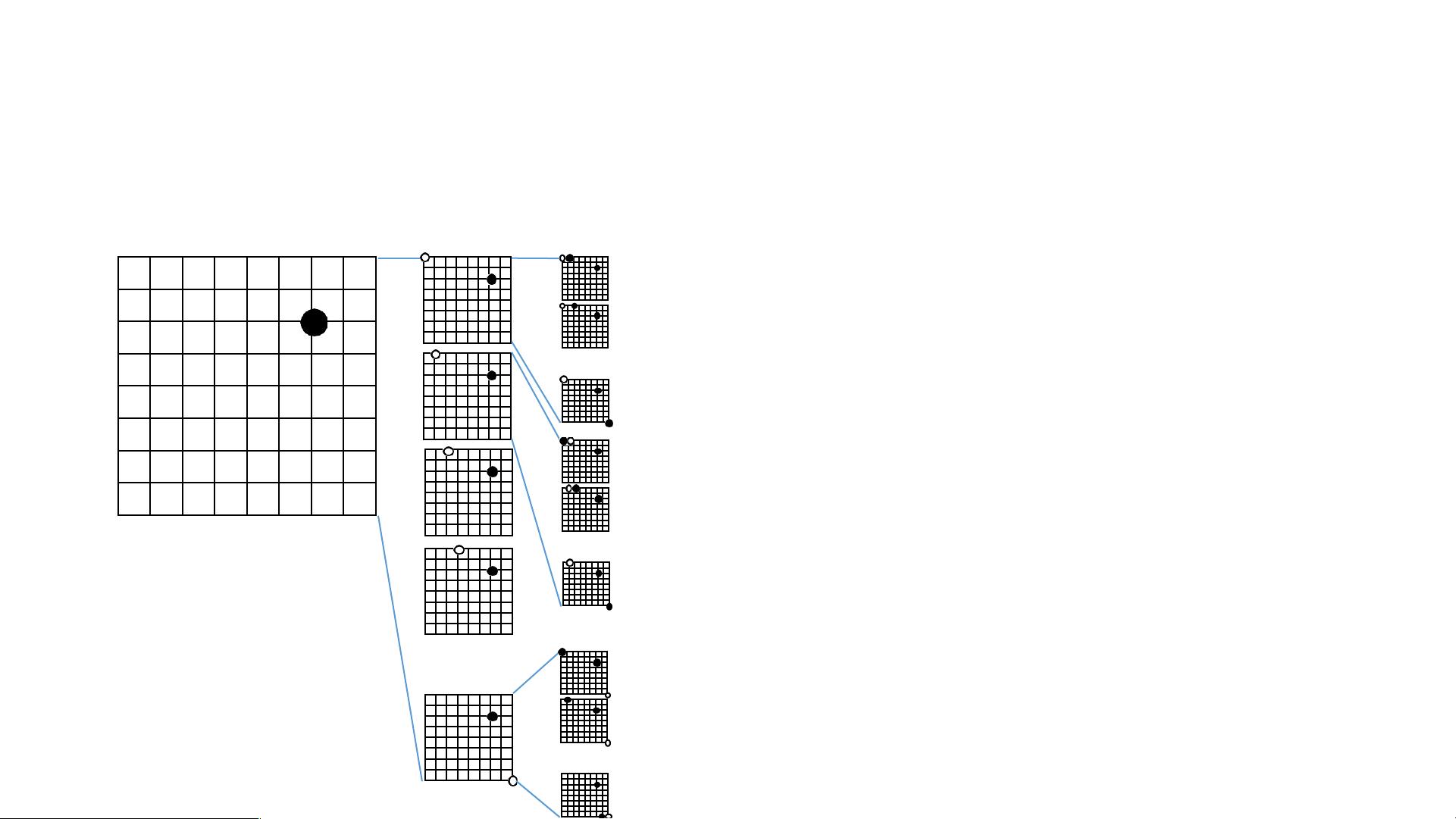
AlphaGo的工作原理主要基于深度学习和蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)的结合。在围棋这个游戏中,每个棋局的状态可以用一个二维矩阵来表示,即d=1的特征。模型不仅仅考虑棋盘位置,还利用其他特征进行决策。随着深度的增加(d=2, d=3, ... , d=maxD),AlphaGo会模拟未来可能出现的所有可能的棋局状态。
在每一步决策时,AlphaGo会基于神经网络评估当前棋局的状态值(s),并预测对手的行动(a)。这个神经网络是由两个部分组成:策略网络(Policy Network)选择下一个最有可能的下棋位置,而价值网络(Value Network)则估算整个棋局的胜负概率。通过蒙特卡洛树搜索,AlphaGo能够对未来几步的多种可能性进行快速模拟,并选取最有可能导致胜利的行动。
模拟过程涉及到遍历所有可能的棋局,直到游戏结束。每个模拟都会报告赢/输的结果,通过大量的模拟,AlphaGo可以计算出每个潜在动作的胜率。例如,如果在某个特定位置放置棋子,AlphaGo可能会预测自己赢得13次。
AlphaGo的成就在于它能够学习并理解围棋的复杂策略,超越了人类专家的直觉,这为人工智能在其他领域的应用提供了宝贵的参考。这篇论文详细阐述了这一创新技术,对于了解深度学习、强化学习和游戏AI的发展具有重要意义。
.-8
Computer Go AI –
7( 7&
s a s'
s
a
."s *9a
剩余58页未读,继续阅读
2695 浏览量
132 浏览量
132 浏览量
2022-08-03 上传
155 浏览量
2021-02-13 上传

杜鹃纸巾
- 粉丝: 37
- 资源: 30
 我的内容管理
展开
我的内容管理
展开







最新资源
- 商业房产信息网页模板
- competitive_programming
- Libro-Modelos-pedag-gicos-y-strateds-dicicas-en-la-educaci-n-contable-:工具库和模型库
- mail.com Start for Chrome-crx插件
- LoinGoText.rar
- WebViewFileUploadFix:Android WebView 文件上传修复(Agate JavaScript 插件)
- 绿色热门商务培训网页模板
- pact:一个用于加密和解密数据的实验密码应用程序,该应用程序实现了实验密码库MSG
- Barracuda Chromebook Security For BCS-crx插件
- proshop-udemy:那里有很多“电子商务”课程,但是大多数使用某种预先构建的插件或平台。 在本课程中,我们将使用MERN堆栈从头开始构建具有以下功能的完全定制的电子商务购物车应用程序:功能齐全的购物车产品评论和评分顶级产品轮播产品分页产品搜索功能带有订单的用户个人资料管理员产品管理管理员用户管理管理员订单详细信息页面将订单标记为已交付选项结帐流程(运输,付款方式等)PayPal信用卡集成自定义数据库种子脚本
- stunning-octo-enigma
- nosafe-webdosV2.0.rar
- 数码产品网络营销网页模板
- winrt-rust:最终使用Rust并使其最终成为Windows Runtime API
- jquery三环立体式图片切换效果
- My Tabs-crx插件
