vSphere Big Data Extensions:深度解析与自动化部署
需积分: 0 59 浏览量
更新于2024-07-24
收藏 1.69MB PPTX 举报
vSphere Big Data Extensions (vBDE) 是 VMware 在其虚拟化平台 vSphere 上针对大数据处理的一套深度集成解决方案,旨在简化 Hadoop 集群的部署与管理,提高效率并增强安全性。这个技术内幕的演示文档深入探讨了如何通过 Serengeti 这一核心组件实现自动化部署流程,使用户能够在短短十分钟内从零开始构建一个完整的 Hadoop 或 HBase 集群,减少了手动操作的繁琐和时间成本。
Serengeti 是作为 vSphere 的扩展来实现这一功能的,它作为一个虚拟应用,可以轻松地在 vCenter Server 上部署。它通过 SSL 连接与 vCenter Server 进行交互,从而实现对 Hadoop 集群中虚拟机(VM)的自动化管理和配置。这包括从模板快速克隆 VM,并通过 vSphere 控制其生命周期。
在 Hadoop 集群的存储和计算架构上,vBDE 引入了一种创新的方式。传统的 Hadoop 实现中,数据和计算是结合在一起的,可能导致资源利用率不高且弹性受限。而 vSphere Big Data Extensions 通过分离存储和计算资源,解决了这些问题:
1. **数据与计算分离**:将数据存储在专用的数据节点(DataNode)上,而计算节点(如 MapReduce 工作节点)则与数据独立,提高了资源利用率。
2. **弹性扩展**:数据节点的弹性不再由 Hadoop 自身决定,而是可以通过 vSphere 的动态资源调整来实现,使得计算资源可以根据需求灵活伸缩。
3. **更强的隔离性**:每个租户都有独立的计算集群,提供了更强的虚拟机级别安全性和资源隔离,确保了不同租户之间的资源互不影响。
4. **多租户支持**:Serengeti 支持在单个 vSphere 环境中为多个租户部署独立的计算资源,满足了多租户场景下的需求。
此外,vSphere Big Data Extensions 还关注了奴隶节点的弹性扩容以及多租户环境下的可扩展性。通过为每个租户部署单独的计算集群,不同租户可以共享硬件资源,同时保持各自的隔离性和性能需求。
vSphere Big Data Extensions 提供了一种全面且高效的方法,将 Hadoop 集群的复杂部署过程转变为一个自动化、易管理的过程,极大地降低了运维成本,提高了大数据处理的灵活性和安全性。这对于企业级的大数据应用来说,是一项重要的技术进步。
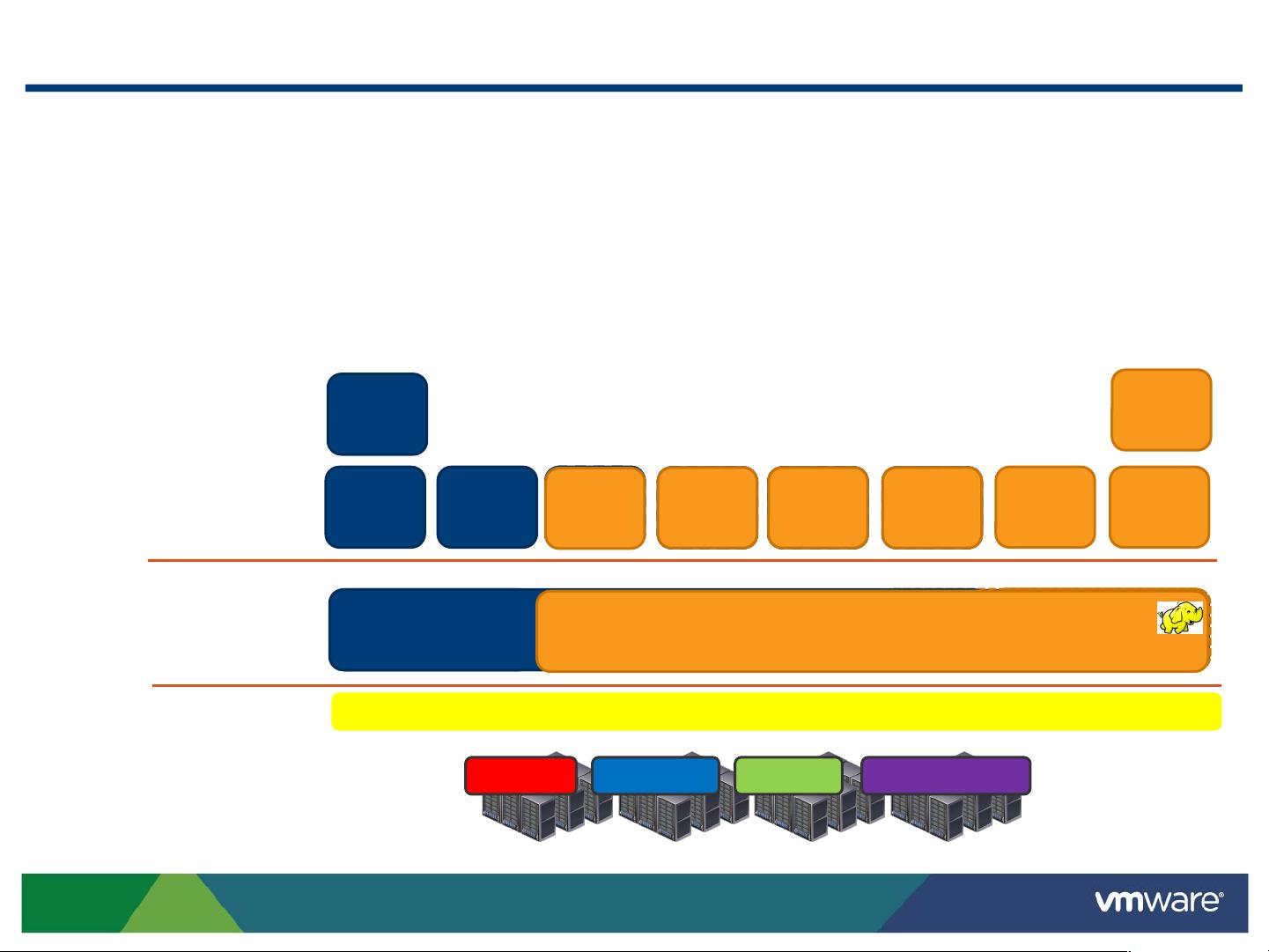
Elastic Scalability & Multi-Tenancy
Deploy separate compute clusters for different tenants sharing HDFS.
Commission/decommission compute nodes according to priority and
available resources
Experimentation
Dynamic resourcepool
Data layer
Production
recommendation engine
Compute layer
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Compute
VM
Experimentation
Production
Compute
VM
Job
Tracker
Job
Tracker
VMware vSphere + Serengeti
剩余24页未读,继续阅读
142 浏览量
310 浏览量
2024-10-11 上传
2024-10-11 上传
2021-10-18 上传
2022-02-16 上传
142 浏览量
168 浏览量

adlis
- 粉丝: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 实现类似百度的邮箱自动提示功能
- C++基础教程源码剖析与下载指南
- Matlab实现Franck-Condon因子振动重叠积分计算
- MapGIS操作手册:坐标系与地图制作指南
- SpringMVC+MyBatis实现bootstrap风格OA系统源码分享
- Web工程错误页面配置与404页面设计模板详解
- BPMN可视化示例库:展示多种功能使用方法
- 使用JXLS库轻松导出Java对象集合为Excel文件示例教程
- C8051F020单片机编程:全面控制与显示技术应用
- FSCapture 7.0:高效网页截图与编辑工具
- 获取SQL Server 2000 JDBC驱动免分数Jar包
- EZ-USB通用驱动程序源代码学习参考
- Xilinx FPGA与CPLD配置:Verilog源代码教程
- C#使用Spierxls.dll库打印Excel表格技巧
- HDDM:C++库构建与高效数据I/O解决方案
- Android Diary应用开发:使用共享首选项和ViewPager
