人工智能副驾驶:未来智能交通的通用技术
需积分: 5 162 浏览量
更新于2024-07-15
收藏 1.59MB PDF 举报
"这篇文章是关于‘人工智能副驾驶’作为未来智能交通系统的一种普遍启用技术的讨论。文中介绍了这种技术的设计原则,并将其置于人机交互的框架内,探讨了相关的认知架构、类人的感知运动策略以及认知的模拟理论。文章通过欧盟项目interactIVe中的‘人工智能副驾驶’实例,展示其如何遵循这些指导原则,并提供了实验结果以说明当前实现的局限性和性能。此外,文章还分析了人工智能副驾驶技术的影响,指出它在智能车辆和协作系统中的广泛应用领域,以及对未来研究的自然规划。”
本文主要讨论的核心知识点包括:
1. **人工智能副驾驶(Artificial Co-Drivers)**: 这是一种辅助驾驶技术,旨在与人类驾驶员协同工作,提升未来智能交通系统的效能。它借鉴了人类-机器人交互的设计原则,旨在模拟人类的驾驶行为和决策过程。
2. **设计原则**: 人工智能副驾驶的设计考虑了通用性、适应性和安全性,以确保在各种交通环境中都能提供有效的支持。这些原则是基于对人类驾驶行为的理解,以及对认知架构和感知运动策略的研究。
3. **认知架构(Cognitive Architectures)**: 这是模拟人类思考和决策过程的技术基础,它使人工智能副驾驶能够理解和预测驾驶场景,做出合理决策。
4. **类人感知运动策略(Human-like Sensory-Motor Strategies)**: 这是指人工智能系统模仿人类驾驶员如何通过感官输入(如视觉、听觉)来控制运动输出(如转向、加速),以实现更自然的驾驶体验。
5. **模拟理论(Emulation Theory of Cognition)**: 这种理论认为,人工智能可以通过模仿人类的行为和思维模式来实现学习和理解复杂任务,对于构建能够理解和适应人类驾驶习惯的人工智能副驾驶至关重要。
6. **欧盟项目interactIVe**: 该项目是人工智能副驾驶技术的一个实际应用案例,展示了如何将上述理论应用于实践中,同时也揭示了现有实施的限制和性能表现。
7. **实验结果与性能分析**: 文章提供了实验数据,这有助于评估人工智能副驾驶在实际驾驶环境中的效能,同时也指出了需要改进和优化的地方。
8. **技术影响与应用领域**: 人工智能副驾驶不仅适用于智能车辆,也对构建合作式的交通系统有重大意义。它可以推动自动驾驶、交通管理、安全预警等多个领域的进步。
9. **未来研究方向**: 该技术的潜力和广泛的应用前景指出了未来需要进一步探索的领域,如提高人工智能副驾驶的自主性、增强其情境理解能力以及优化人机交互界面等。
人工智能副驾驶技术是一个结合了认知科学、人工智能和工程实践的跨学科领域,它的目标是创造一种能与人类驾驶员无缝协作的智能系统,以提升未来的交通安全性、效率和舒适度。
DA LIO et al.: ARTIFICIAL CO-DRIVERS AS A UNIVERSAL ENABLING TECHNOLOGY 247
reduce speed in curves to maintain the accuracy in lateral
position).
III. C
O-DRIVER OF THE INTERACTIVE PRO JE CT
A. Theoretical Foundations and Design Guidelines
The main goal is to design an agent that is capable of
enacting the “like me” framework, which means that it must
have sensory-motor strategies similar to that of a human and
that it must be capable of using them to mirror human behavior
for inference of intentions and human–machine interaction.
Designing human motor strategies is a relatively easy step:
One may take inspiration from human optimality motor prin-
ciples. For example, we already used the minimum jerk/time
tradeoff and the acceleration willingness envelope to produce
human “reference maneuvers” for advanced driver assistance
systems ( ADAS) [63], [92], [93].
Implementing inference of intentions by mirroring, and
human-peer interactions, is the second less assured step. Two
notable examples (MOSAIC and HAMMER) have been men-
tioned for the general robotics application domain. In the
driving domain, DIPLECS demonstrated learning of the ECOM
structure from human-driving expert-annotated training sets,
and classification of human driver states. However, no co-
driver, in the sense of the definition given in Section I, has been
demonstrated as yet.
The main research question and contribution of this paper is
thus producing a co-driver example implementation to demon-
strate the effectiveness of the simulation/mirroring mechanism
and the following interactions and to focus on the important
potential application impacts that follow from these.
The co-driver has been developed by a combination of direct
synthesis (OC) at the motor primitive level, as well as manual
tuning at higher behavioral levels (the latter being carried
out after inspection of salient situations whenever the two
agents happen to disagree). The final system is thus the cu-
mulation of having compared correct human behaviors (while
discarding incorrect human behaviors) with the developing
agent within many situations encountered during months of
development.
However, in Section VI, we describe how the same archi-
tecture can be potentially employed in the future to implement
“learning by simulation,” namely, optimizing higher-level be-
haviors with simulated interactions via the forward emulators,
to let the system build knowledge automatically (instead of
manually), particularly to accommodate rare events and to
continuously improve its reliability.
Note that, while the main purpose of this system is “un-
derstanding” human goals for preventive safety (see below),
emergency handling and efficient vehicle control intervention
may be added by means of new behaviors (no longer necessarily
human-like) in future versions.
B. Example Implementation
“InteractIVe” is the current flagship project of the European
Commission in the intelligent vehicle domain [99]. It tackles
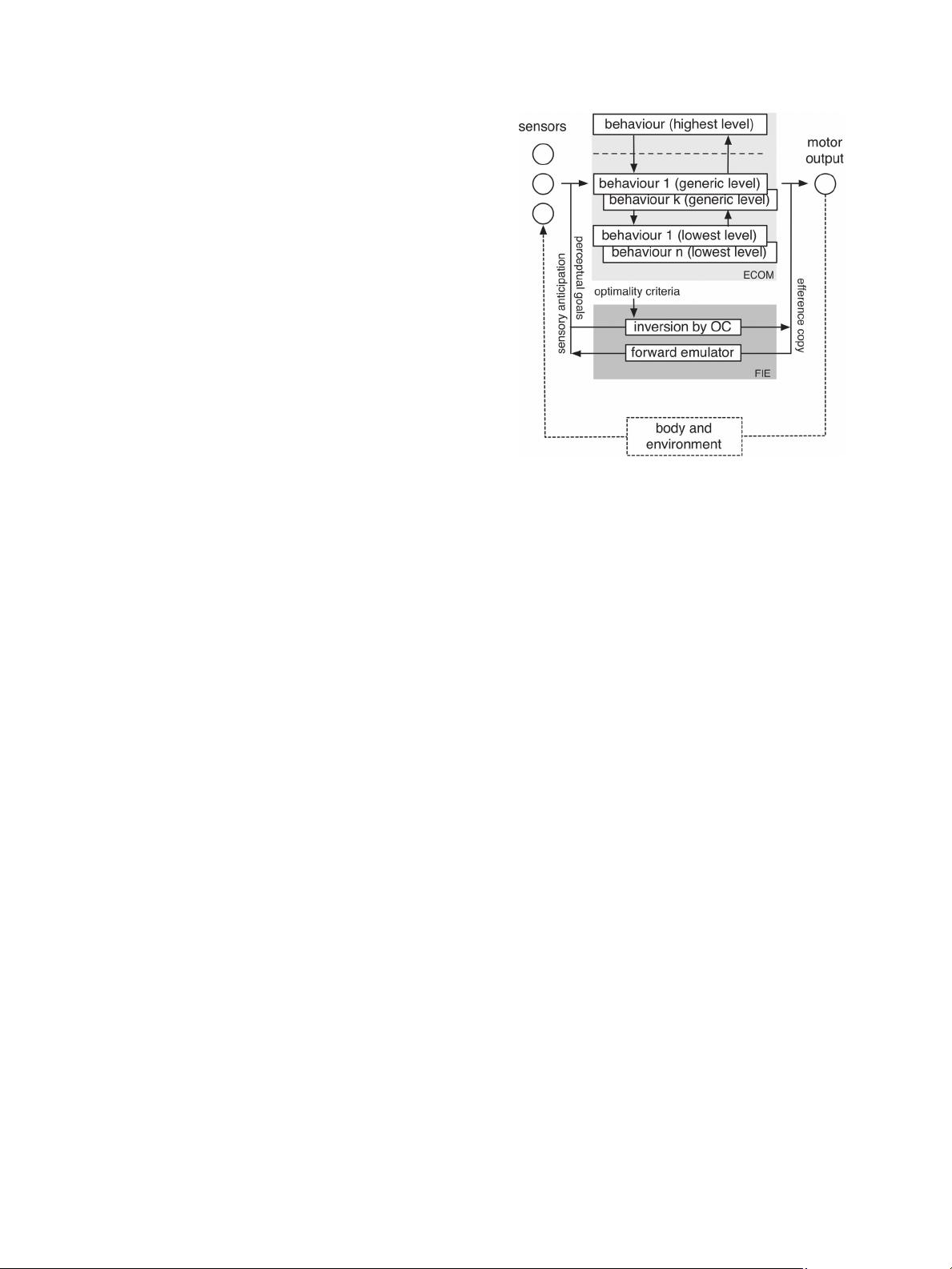
Fig. 4. Architecture of the co-driver for the CRF implementation of the
Continuous Support function.
vehicle safety in a systematic way by means of three different
subprojects focusing on different time scales: from early holis-
tic preventive safety, to automatic collision avoidance, and to
collision mitigation.
Preventive safety deals with normal driving and with pre-
venting dangerous situations. For this, a “continuous-support
function” has been conceived, which monitors driving and acts
whenever necessary. This functionality integrates, in a unique
human–machine interaction, several distinct forms of the driver
assistance system.
To implement the Continuous Support function, the co-driver
metaphor was adopted. It has been implemented within four
demonstrators of differing kinds. The following describes the
Centro Ricerche Fiat (CRF) implementation, which is closest
to the premises in Section II.
C. Co-Driver Architecture (CRF Implementation)
Fig. 4 shows the adopted architecture. The agent’s “body” is
the car, the agent’s “environment” is the road and its users, and
the “motor output” is the longitudinal and lateral control.
This architecture may be seen to resemble that in Fig. 3,
albeit extended in that the perception–action link is here ex-
plicitly expanded into a subsumptive hierarchy of PA loops.
As indicated in Section II, the input/output structure of layers
within the subsumption hierarchy is characterized by (progres-
sive generalizations of) perceptions and actions. The actual
implementation is built up from functions with input and output
characteristics described in the following section.
By comparison to Fig. 2(b), this architecture is enriched
with forward/inverse models, which make it possible to operate
offline for any purposes requiring “extended deliberation,” e.g.,
for human intention recognition.
剩余19页未读,继续阅读
2022-11-18 上传
2021-05-28 上传
2024-09-28 上传
2010-01-04 上传
2021-05-26 上传
2016-12-17 上传
2021-05-26 上传

AaronFu
- 粉丝: 1
- 资源: 11
 我的内容管理
展开
我的内容管理
展开







最新资源
- 黑板风格计算机毕业答辩PPT模板下载
- CodeSandbox实现ListView快速创建指南
- Node.js脚本实现WXR文件到Postgres数据库帖子导入
- 清新简约创意三角毕业论文答辩PPT模板
- DISCORD-JS-CRUD:提升 Discord 机器人开发体验
- Node.js v4.3.2版本Linux ARM64平台运行时环境发布
- SQLight:C++11编写的轻量级MySQL客户端
- 计算机专业毕业论文答辩PPT模板
- Wireshark网络抓包工具的使用与数据包解析
- Wild Match Map: JavaScript中实现通配符映射与事件绑定
- 毕业答辩利器:蝶恋花毕业设计PPT模板
- Node.js深度解析:高性能Web服务器与实时应用构建
- 掌握深度图技术:游戏开发中的绚丽应用案例
- Dart语言的HTTP扩展包功能详解
- MoonMaker: 投资组合加固神器,助力$GME投资者登月
- 计算机毕业设计答辩PPT模板下载
