使用LEX构建C语言词法分析器
版权申诉
DOC格式 | 182KB |
更新于2024-07-03
| 106 浏览量 | 举报
"基于LEX的C语言词法分析器文档主要介绍了如何利用LEX工具来构建C语言的词法分析器,旨在让学生掌握编译原理、编译程序设计的基础知识,并熟悉C语言的各种Token。文件内容涵盖了词法分析器的构造方法、LEX输入文件的结构以及正则表达式的定义和规则设定。"
在编译原理中,词法分析是编译器的第一个阶段,它负责将源代码分解成一系列有意义的标记(Token),这些标记是语言的基本构建块。基于LEX的词法分析器设计通常涉及以下知识点:
1. **LEX工具**:LEX是一个广泛使用的工具,用于生成词法分析器。它接收一个描述词法规则的输入文件(通常以`.l`或`.lex`为扩展名),并生成相应的C代码,该代码可以读取输入字符流,识别出符合规则的Token。
2. **词法分析器的结构**:一个典型的LEX词法分析器输入文件分为三个部分:定义集、规则集和辅助程序集。定义集包含正则表达式和变量声明,规则集定义了如何匹配这些表达式,而辅助程序集则是用户自定义的C代码,可以处理特定逻辑。
3. **正则表达式**:正则表达式是描述字符模式的简写形式,用于定义词法规则。例如,`ID`表示标识符,由字母开头,后跟任意数量的字母或数字;`NUM`表示数字,由一个或多个数字组成。
4. **LEX规则定义**:在LEX文件中,规则定义了如何处理匹配到的正则表达式。例如,定义识别保留字的规则,当遇到"int"、"else"等关键字时,输出相应的保留字Token;定义识别数字的规则,遇到数字时,输出数字Token。
5. **错误处理**:LEX允许定义错误处理规则,例如在错误_id规则中,处理数字开头但不符合数字规则的情况。
6. **输入输出处理**:在词法分析器中,`yytext`是一个指向当前匹配到的字符串的指针,`yyleng`是字符串的长度,`lineno`是当前行号,它们在输出信息或处理错误时非常有用。
7. **用户自定义函数**:除了预定义的规则,用户还可以添加自己的C代码来扩展词法分析器的功能,比如处理复杂的Token逻辑或进行错误检测。
通过这个实验,学生不仅可以学习到如何使用LEX工具,还能深入理解编译器的词法分析阶段,这对于理解和构建编译器至关重要。此外,掌握词法分析器的设计也有助于提高对编程语言语法的理解和对源代码的调试能力。
for(i=0;i<l;i++){
s[i]=toupper(s[i]);
}
}//将保留字变为大写
//主函数
main(void)
{
//定义输入文件名变量
char infilename[400];
printf("输入文件名:");
scanf("%s",&infilename);
yyin = fopen(infilename,"r");//读取文件
printf("开始词法分析: \n");
return yylex();
}
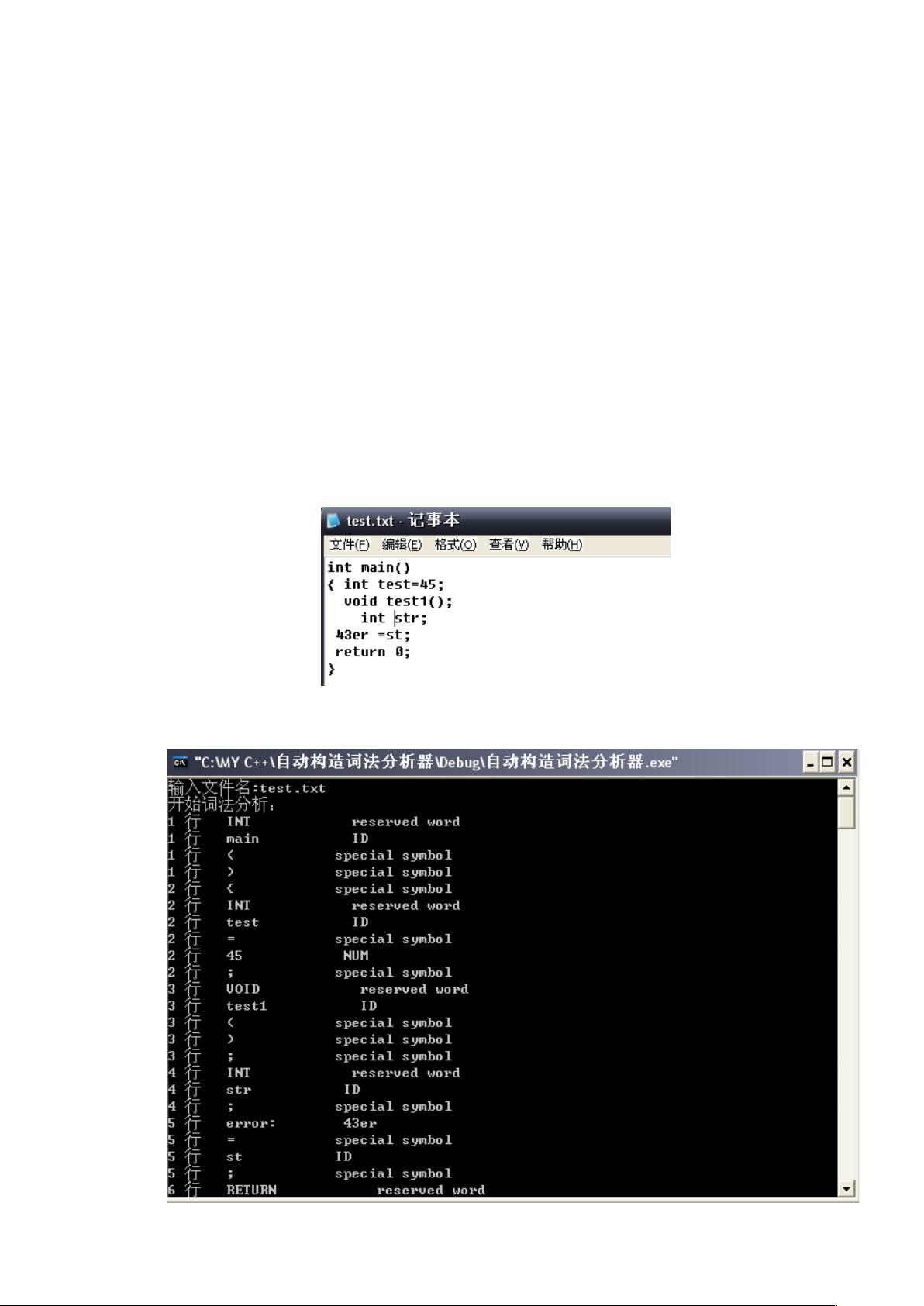
4. 测试结果
测试数据选择
测试的文件代码
测试结果分析
5. 总结
剩余19页未读,继续阅读
相关推荐

420 浏览量
13 浏览量
10 浏览量
7 浏览量

4 浏览量

智慧安全方案
- 粉丝: 3844
- 资源: 59万+
 我的内容管理
展开
我的内容管理
展开







最新资源
- django-dashing:django-dashing是Django的可定制的模块化仪表板应用程序框架,用于可视化有关项目的有趣数据。 受仪表板框架启发
- 7z,没有广告的解压工具
- filepond-plugin-file-poster:将海报图像添加到文件中
- HTML5 canvas实现生物圈里的细胞运动动画效果源码.zip
- 简码
- Bikcraft-wordpress
- RentACarV1BackEnd
- currency-parser:金融.ua汇率
- 数据恢复工具 壁虎数据恢复 v3.4
- html5 canvas实现响应鼠标拖动的流体图片动画特效源码.zip
- 盖塔皮
- split:基于机架的AB测试框架
- dimmer-button
- PR_K._语音识别_语音性别识别_
- ETL_Project
- bookbrainz-api
