AutoAugment:数据驱动的图像增强策略自动化
需积分: 5 164 浏览量
更新于2024-08-03
收藏 1.09MB PDF 举报
自动增强技术是一种在现代计算机视觉领域中被广泛应用的重要方法,旨在提升深度学习模型在图像分类任务中的性能。传统的数据增强通常依赖于人工设计的各种图像处理操作,如旋转、翻转、缩放等,这些操作参数需要人工调整以优化模型的泛化能力。然而,这种方法往往受限于人类专家的知识和经验。
AutoAugment是Ekin Cubuk等人在2018年提出的一种创新性方法,它旨在通过机器学习的方式自动学习并发现最佳的数据增强策略。AutoAugment的核心思想是构建一个搜索空间,其中每个数据增强政策由多个子政策组成,每个子政策包含两个基本操作,比如平移、旋转或剪切,以及执行这些操作的概率和强度参数。这些子政策在每次训练批次中随机选择并应用到输入图像上,使得模型能够在多样化的变换中进行学习。
该算法采用了一种搜索算法,目标是在给定的验证集上最大化神经网络的准确率。通过这种方式,AutoAugment能够找到适应特定任务和数据集的自适应增强策略,超越了手动设计的局限。在实验中,AutoAugment已经在CIFAR-10、CIFAR-100、SVHN和ImageNet等多个知名图像识别基准上取得了最先进的结果。特别地,在ImageNet数据集上,它甚至达到了Top-1的精度达到83.5%,这是一个显著的性能提升,证明了自动增强技术的巨大潜力。
总结来说,AutoAugment是一个重要的里程碑,它将数据增强从手工艺术提升到了自动化科学,使得深度学习模型能够从海量可能的增强策略中自动发掘最有效的组合,从而提高了模型的泛化能力和最终性能。这种方法对于解决大规模图像识别问题具有重要意义,也为其他领域的增强学习和自适应策略提供了新的研究方向。
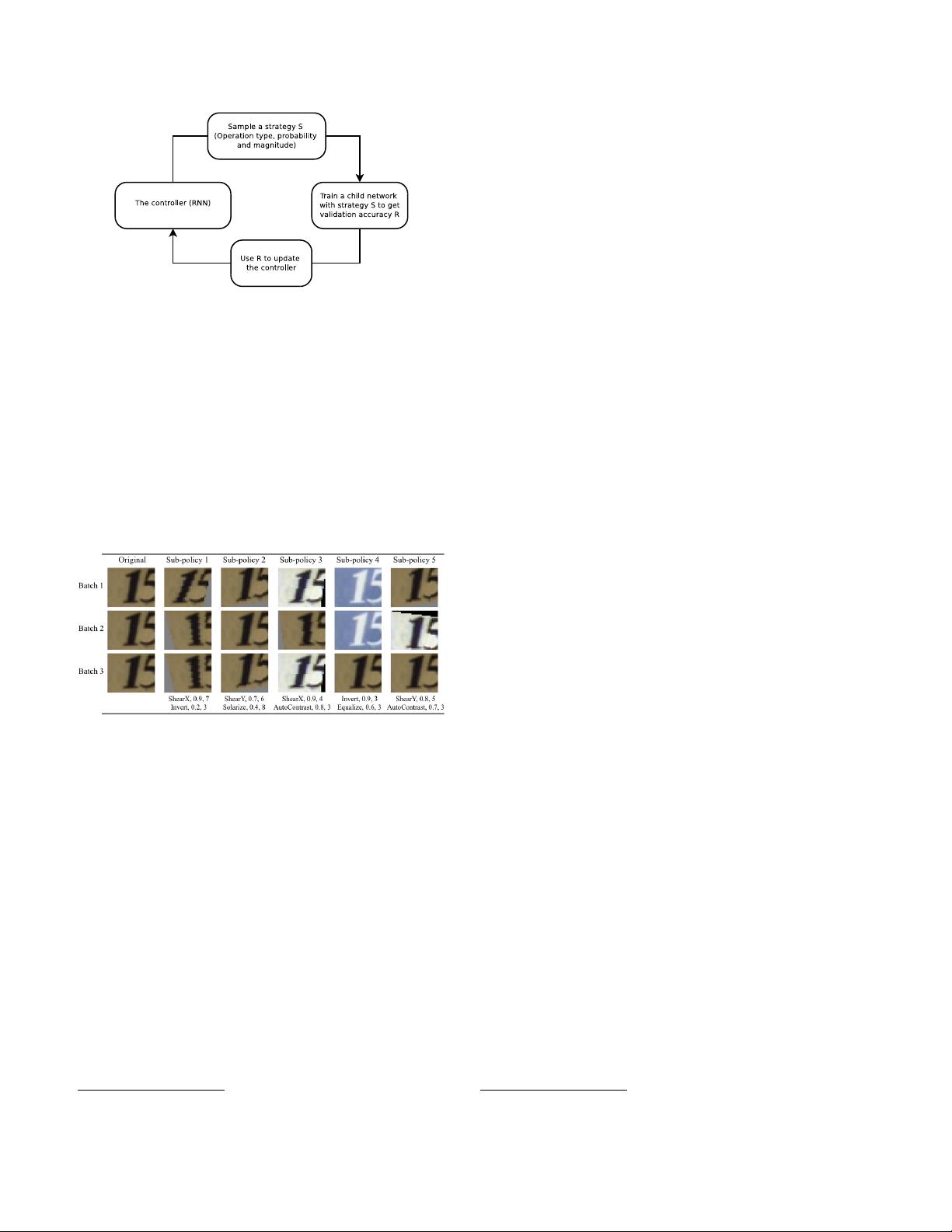
Figure 1. Overview of our framework of using a search method
(e.g., Reinforcement Learning) to search for better data augmen-
tation policies. A controller RNN predicts an augmentation policy
from the search space. A child network with a fixed architecture
is trained to convergence achieving accuracy R. The reward R will
be used with the policy gradient method to update the controller
so that it can generate better policies over time.
probability of applying ShearX is 0.9, and when applied,
has a magnitude of 7 out of 10. We then apply Invert with
probability of 0.8. The Invert operation does not use the
magnitude information. We emphasize that these operations
are applied in the specified order.
Figure 2. One of the policies found on SVHN, and how it can be
used to generate augmented data given an original image used to
train a neural network. The policy has 5 sub-policies. For every
image in a mini-batch, we choose a sub-policy uniformly at ran-
dom to generate a transformed image to train the neural network.
Each sub-policy consists of 2 operations, each operation is associ-
ated with two numerical values: the probability of calling the op-
eration, and the magnitude of the operation. There is a probability
of calling an operation, so the operation may not be applied in that
mini-batch. However, if applied, it is applied with the fixed mag-
nitude. We highlight the stochasticity in applying the sub-policies
by showing how one image can be transformed differently in dif-
ferent mini-batches, even with the same sub-policy. As explained
in the text, on SVHN, geometric transformations are picked more
often by AutoAugment. It can be seen why Invert is a commonly
selected operation on SVHN, since the numbers in the image are
invariant to that transformation.
The operations we used in our experiments are from PIL,
a popular Python image library.
1
For generality, we consid-
ered all functions in PIL that accept an image as input and
1
https://pillow.readthedocs.io/en/5.1.x/
output an image. We additionally used two other promis-
ing augmentation techniques: Cutout [12] and SamplePair-
ing [24]. The operations we searched over are ShearX/Y,
TranslateX/Y, Rotate, AutoContrast, Invert, Equalize, So-
larize, Posterize, Contrast, Color, Brightness, Sharpness,
Cutout [12], Sample Pairing [24].
2
In total, we have 16
operations in our search space. Each operation also comes
with a default range of magnitudes, which will be described
in more detail in Section 4. We discretize the range of mag-
nitudes into 10 values (uniform spacing) so that we can use
a discrete search algorithm to find them. Similarly, we also
discretize the probability of applying that operation into 11
values (uniform spacing). Finding each sub-policy becomes
a search problem in a space of (16× 10 × 11)
2
possibilities.
Our goal, however, is to find 5 such sub-policies concur-
rently in order to increase diversity. The search space with 5
sub-policies then has roughly (16× 10×11)
10
≈ 2.9×10
32
possibilities.
The 16 operations we used and their default range of val-
ues are shown in Table 1 in the Appendix. Notice that there
is no explicit “Identity” operation in our search space; this
operation is implicit, and can be achieved by calling an op-
eration with probability set to be 0.
Search algorithm details: The search algorithm that
we used in our experiment uses Reinforcement Learning,
inspired by [71, 4, 72, 5]. The search algorithm has two
components: a controller, which is a recurrent neural net-
work, and the training algorithm, which is the Proximal
Policy Optimization algorithm [53]. At each step, the con-
troller predicts a decision produced by a softmax; the pre-
diction is then fed into the next step as an embedding. In
total the controller has 30 softmax predictions in order to
predict 5 sub-policies, each with 2 operations, and each op-
eration requiring an operation type, magnitude and proba-
bility.
The training of controller RNN: The controller is
trained with a reward signal, which is how good the policy is
in improving the generalization of a “child model” (a neural
network trained as part of the search process). In our exper-
iments, we set aside a validation set to measure the gen-
eralization of a child model. A child model is trained with
augmented data generated by applying the 5 sub-policies on
the training set (that does not contain the validation set). For
each example in the mini-batch, one of the 5 sub-policies is
chosen randomly to augment the image. The child model
is then evaluated on the validation set to measure the accu-
racy, which is used as the reward signal to train the recurrent
network controller. On each dataset, the controller samples
about 15,000 policies.
Architecture of controller RNN and training hyper-
parameters: We follow the training procedure and hyper-
parameters from [72] for training the controller. More con-
2
Details about these operations are listed in Table 1 in the Appendix.
剩余13页未读,继续阅读
2019-09-18 上传
2023-07-21 上传
2020-02-21 上传
2024-01-27 上传
2023-09-08 上传
2023-06-06 上传
2023-06-09 上传
2023-06-13 上传
2023-06-09 上传

IRUIRUI__
- 粉丝: 567
- 资源: 55
 我的内容管理
展开
我的内容管理
展开







最新资源
- 前端协作项目:发布猜图游戏功能与待修复事项
- Spring框架REST服务开发实践指南
- ALU课设实现基础与高级运算功能
- 深入了解STK:C++音频信号处理综合工具套件
- 华中科技大学电信学院软件无线电实验资料汇总
- CGSN数据解析与集成验证工具集:Python和Shell脚本
- Java实现的远程视频会议系统开发教程
- Change-OEM: 用Java修改Windows OEM信息与Logo
- cmnd:文本到远程API的桥接平台开发
- 解决BIOS刷写错误28:PRR.exe的应用与效果
- 深度学习对抗攻击库:adversarial_robustness_toolbox 1.10.0
- Win7系统CP2102驱动下载与安装指南
- 深入理解Java中的函数式编程技巧
- GY-906 MLX90614ESF传感器模块温度采集应用资料
- Adversarial Robustness Toolbox 1.15.1 工具包安装教程
- GNU Radio的供应商中立SDR开发包:gr-sdr介绍
