3D点云语义分割:子流形稀疏卷积网络
需积分: 27 24 浏览量
更新于2024-09-09
收藏 616KB PDF 举报
"3D Semantic Segmentation with Submanifold Sparse Convolutional Networks"
本文主要探讨了在处理3D语义分割任务中,如何利用稀疏神经网络,特别是子流形稀疏卷积网络(SSCNs)来提高效率和性能。在传统的卷积网络(CNNs)中,对于如图像、视频等密集数据,其表现优异,但在处理3D点云等稀疏数据时,效率低下。3D点云通常由LiDAR扫描或RGB-D相机获得,这类数据天然具有稀疏性。
作者引入了一种新的稀疏卷积操作,这种操作专为处理空间上稀疏的数据设计,旨在提升处理效率。通过这些新操作构建的网络称为子流形稀疏卷积网络。SSCNs的核心思想是仅对实际存在的数据点执行计算,跳过空洞区域,从而减少无效运算,提高了计算效率。
在3D语义分割任务上,SSCNs展示了强大的性能。语义分割是将3D数据分割成不同的类别,每个点都被分配一个语义标签,如路面、建筑物、行人等。通过对比实验,SSCNs在一项最近的3D语义分割竞赛测试集上超越了所有先前的最优方法,证明了其在理解和解析3D点云数据方面的优势。
此外,论文还可能涉及以下知识点:
1. **稀疏神经网络**:这种网络设计优化了处理稀疏输入的能力,只在有数据的区域进行计算,节省了计算资源,提高了处理速度。
2. **3D语义分割**:这是一种计算机视觉任务,目的是对3D场景进行像素级别的分类,对于自动驾驶、机器人导航等领域至关重要。
3. **子流形**:在数学中,子流形是指嵌入在更大空间中的几何结构,这里可能指的是3D点云中有意义的连续部分,如平面、曲线等。
4. **稀疏卷积操作**:与传统卷积不同,稀疏卷积仅在非零元素上执行,减少了大量不必要的计算,尤其适合3D点云等稀疏数据。
5. **LiDAR扫描**和**RGB-D相机**:这两种设备是获取3D点云数据的主要方式,LiDAR通过激光雷达原理生成点云,RGB-D相机则结合彩色图像和深度信息生成点云。
6. **CVPR-18**:这可能指论文在2018年计算机视觉与模式识别(CVPR)会议上发表,CVPR是计算机视觉领域的重要国际会议。
综上,这篇研究工作为3D数据的高效分析提供了新的工具,特别是在3D语义分割这一关键应用上,展示了稀疏卷积网络的巨大潜力。
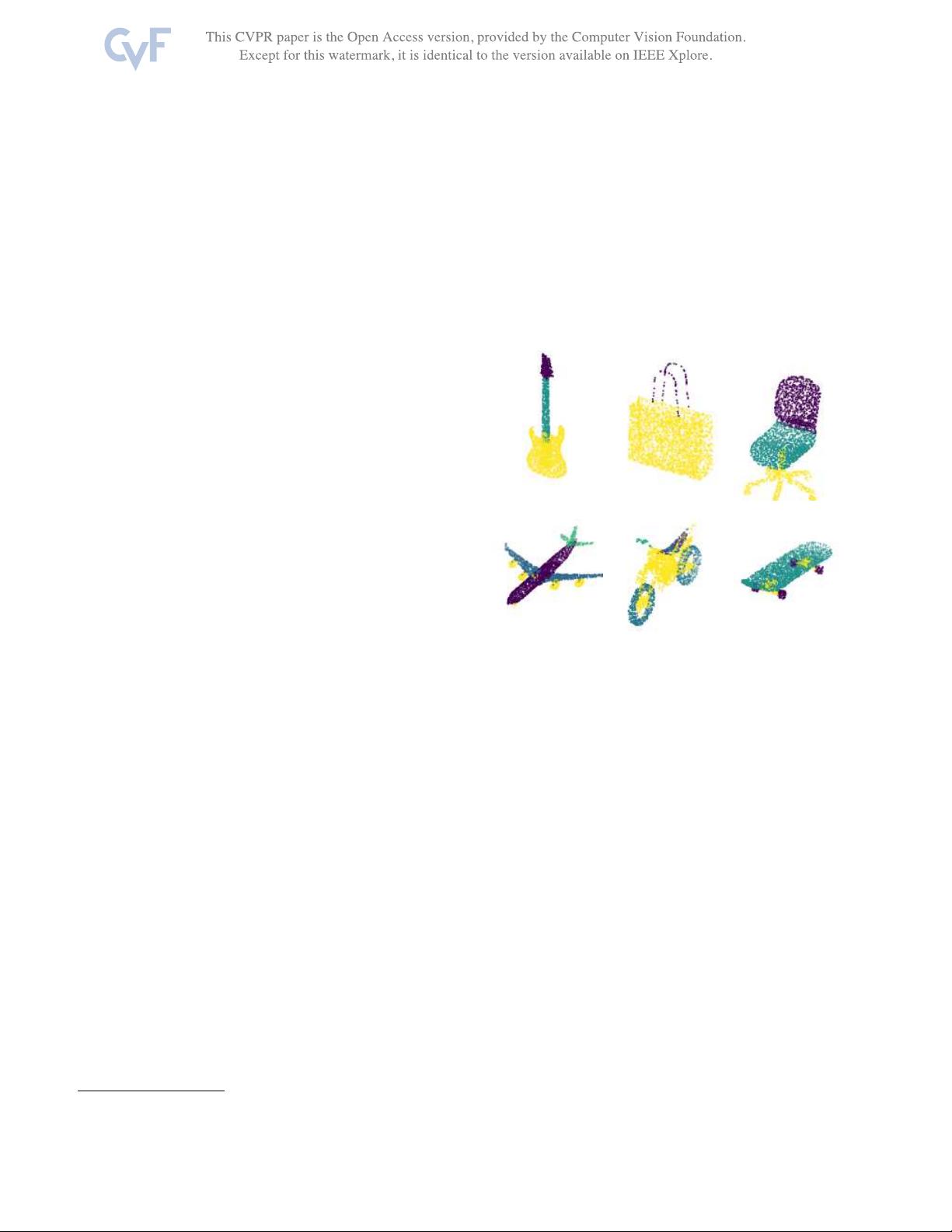
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
Benjamin Graham
Facebook AI Research
benjamingraham@fb.com
Martin Engelcke
∗
University of Oxford
martin@robots.ox.ac.uk
Laurens van der Maaten
Facebook AI Research
lvdmaaten@fb.com
Abstract
Convolutional networks are the de-facto standard for an-
alyzing spatio-temporal data such as images, videos, and
3D shapes. Whilst some of this data is naturally dense (e.g.,
photos), many other data sources are inherently sparse. Ex-
amples include 3D point clouds that were obtained using
a LiDAR scanner or RGB-D camera. Standard “dense”
implementations of convolutional networks are very ineffi-
cient when applied on such sparse data. We introduce new
sparse convolutional operations that are designed to pro-
cess spatially-sparse data more efficiently, and use them
to develop spatially-sparse convolutional networks. We
demonstrate the strong performance of the resulting mod-
els, called submanifold sparse convolutional networks (SS-
CNs), on two tasks involving semantic segmentation of 3D
point clouds. In particular, our models outperform all prior
state-of-the-art on the test set of a recent semantic segmen-
tation competition.
1. Introduction
Convolutional networks (ConvNets) constitute the state-
of-the art method for a wide range of tasks that involve
the analysis of data with spatial and/or temporal struc-
ture, such as photos, videos, or 3D surface models. While
such data frequently comprises a densely populated (2D or
3D) grid, other datasets are naturally sparse. For instance,
handwriting is made up of one-dimensional lines in two-
dimensional space, pictures made by RGB-D cameras are
three-dimensional point clouds, and polygonal mesh mod-
els form two-dimensional surfaces in 3D space.
The curse of dimensionality applies, in particular, to data
that lives on grids that have three or more dimensions: the
number of points on the grid grows exponentially with its
dimensionality. In such scenarios, it becomes increasingly
important to exploit data sparsity whenever possible in or-
der to reduce the computational resources needed for data
processing. Indeed, exploiting sparsity is paramount when
∗
Work done while interning at Facebook AI Research
Figure 1: Examples of 3D point clouds of objects from the
ShapeNet part-segmentation challenge [
23]. The colors of
the points represent the part labels.
analyzing, e.g., RGB-D videos which are sparsely popu-
lated 4D structures.
Traditional convolutional network implementations are
optimized for data that lives on densely populated grids,
and cannot process sparse data efficiently. More recently,
a number of convolutional network implementations have
been presented that are tailored to work efficiently on sparse
data [
3, 4, 18]. Mathematically, some of these imple-
mentations are identical to regular convolutional networks,
but they require fewer computational resources in terms of
FLOPs and/or memory [
3, 4]. Prior work uses a sparse ver-
sion of the im2col operation that restricts computation
and storage to “active” sites [4], or uses the voting algo-
rithm from [
22] to prune unnecessary multiplications by ze-
ros [
3]. OctNets [18] modify the convolution operator to
produce “averaged” hidden states in parts of the grid that
are outside the region of interest.
One of the downsides of prior sparse implementations of
convolutional networks is that they “dilate” the sparse data
in every layer by applying “full” convolutions. In this work,
9224
下载后可阅读完整内容,剩余8页未读,立即下载
138 浏览量
1178 浏览量
123 浏览量
180 浏览量
235 浏览量
183 浏览量
247 浏览量
130 浏览量

AlgoFei
- 粉丝: 9
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java中SQLServer与MySQL数据库驱动的使用方法
- 微信图文混排技术详解与Android实现
- 搭建Nginx PHP MySQL环境:Docker实战教程
- DW-TX382系列驱动的优化与应用
- knotes项目中消息提交与日志管理功能介绍
- CSS3美化单选多选按钮的多种特效实现
- 蓝色牛仔布服装公司DIV+CSS网站模板发布
- 实现Java对象与Excel/CSV数据的互转方法
- 三星Galaxy Tab 4 WiFi 7.0设备树开发进展
- iOS实现完美QQ分组二级展开动画效果教程
- 重力粒子动态绘图屏保:diffuseGravity 体验
- 深入解析网络超链接标记:用CoffeeScript实现互联网上的互联网
- PHP顶层类实现调试信息管理与主页判定
- Windows平台Markdown图片快速上传与外链生成工具
- 针对Windows 7的RAD Studio 2007调试器修复方案
- 短信监听实现的Android位置定位应用
