深入理解Hadoop集群:原理、拓扑与实现
"看懂Hadoop集群原理与实现方式"
Hadoop是一个开源的分布式计算框架,设计用于处理和存储海量数据。它的核心组件包括Hadoop Distributed File System (HDFS) 和 MapReduce,两者共同构建了一个可靠的、可扩展的分布式计算环境。
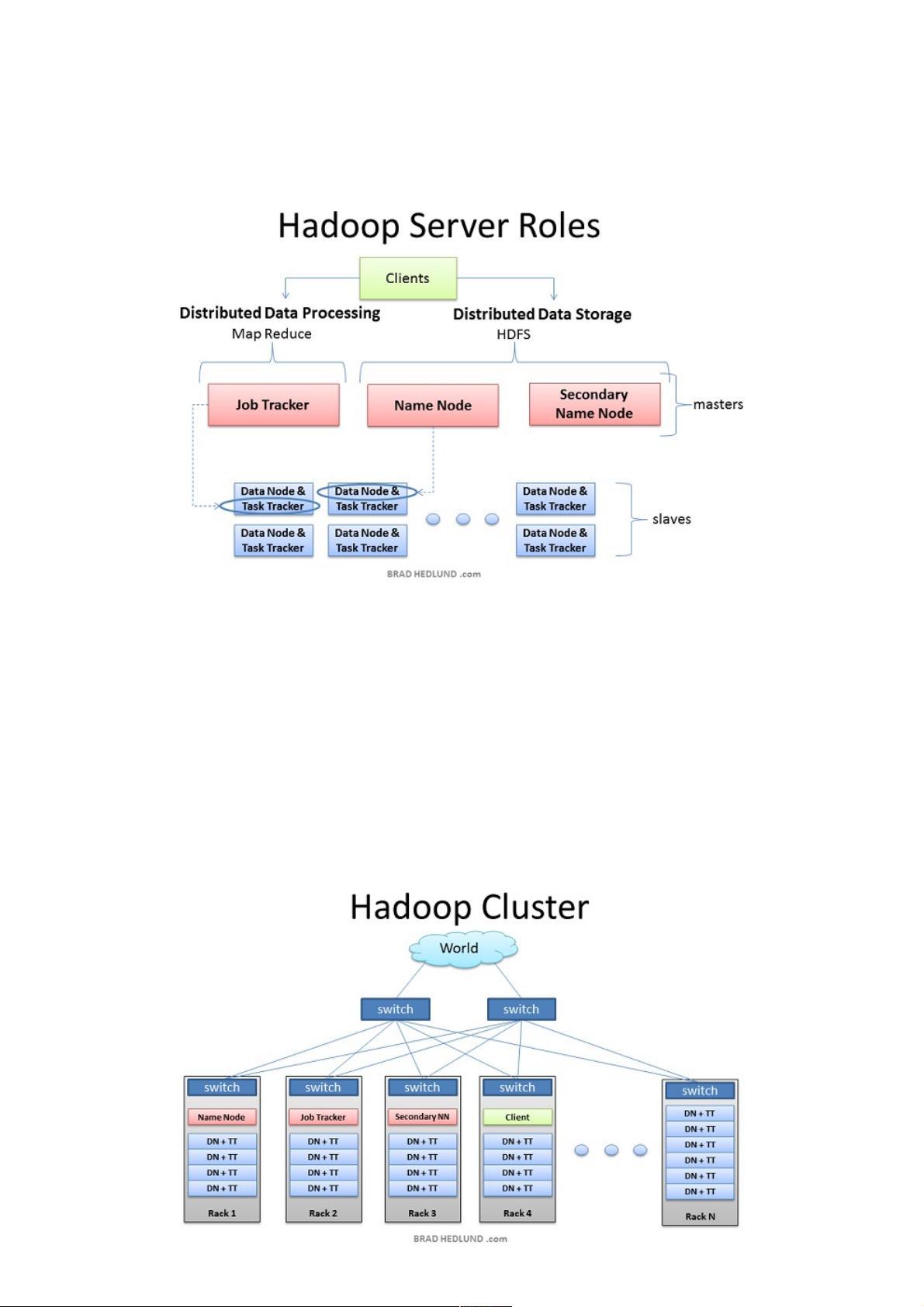
在Hadoop集群中,有三个主要的服务器角色:
1. **客户端**:客户端是用户交互的接口,它负责提交作业(jobs)到集群,并接收完成后的结果。客户端并不实际参与到数据处理过程中,而是作为数据输入输出的起点和终点。
2. **Masters节点**:主节点包括NameNode和JobTracker。NameNode是HDFS的核心,它维护文件系统的命名空间和文件块信息,负责数据存储的管理。JobTracker则是MapReduce的调度器,它接收并管理客户端提交的作业,分配任务给Slave节点。
3. **Slave节点**:Slave节点由DataNodes和TaskTrackers组成。DataNodes是HDFS的数据存储节点,它们存储数据块并执行NameNode指示的数据操作。TaskTrackers执行JobTracker分配的Map和Reduce任务,同时报告任务进度和状态。
在集群部署时,根据规模不同,服务器可能承担多重角色。在小型集群中,NameNode和JobTracker可能部署在同一台服务器上,但在大型集群中,为了高可用性和性能优化,通常会将这些角色分布在不同的物理机器上。值得注意的是,SecondaryNameNode并不直接与NameNode运行在同一台机器上,因为它主要负责周期性地合并NameNode的编辑日志,以减轻NameNode的压力。
在硬件基础设施层面,Hadoop集群通常在Linux环境下运行。服务器间通过网络连接,每个机架顶部有一个交换机作为网络接入点。对于大规模集群,确保足够的网络带宽至关重要,尤其是当服务器之间需要高速交换数据时。在理想情况下,使用高速网络如万兆以太网可以避免网络成为性能瓶颈。
集群中的机架设计有利于减少数据传输延迟,因为同一机架内的节点间通信通常比跨机架通信更快。因此,Hadoop会尽可能地在同一个机架内的节点间复制数据块,以优化数据读取速度。这样的设计有助于提高整体的I/O效率和计算性能。
理解Hadoop集群的架构和工作原理对于开发、管理和优化Hadoop系统至关重要,能够帮助我们更好地设计和调整集群配置,从而充分发挥Hadoop在大数据处理中的优势。
看懂看懂Hadoop集群原理与实现方式集群原理与实现方式
文章让大家通过拓扑图的形式直观的了解 Hadoop 集群是如何搭建、运行以及各个节点之间如何相互调用、每个节点是如何工
作以及各个节点的作用是什么。明白这一点将会对学习 Hadoop 有很大的帮助。首先,我们开始了解 Hadoop 的基础知识,以
及 Hadoop 集群的工作原理。
在Hadoop部署中,有三种服务器角色,他们分别是客户端、Masters节点以及Slave 节点。Master 节点,Masters 节点又称主
节点,主节点负责监控两个核心功能:大数据存储(HDFS)以及数据并行计算(Map Reduce)。其中,Name Node 负责监
控以及协调数据存储(HDFS)的工作,Job Tracker 则负责监督以及协调 Map Reduce 的并行计算。 而Slave 节点则负责具
体的工作以及数据存储。每个 Slave 运行一个 Data Node 和一个 Task Tracker 守护进程。这两个守护进程负责与 Master 节
点通信。Task Tracker 守护进程与 Job Tracker 相互作用,而 Data Node 守护进程则与 Name Node 相互作用。
所有的集群配置都会存在于客户端服务器,但是客户端服务器不属于 Master 以及 Salve,客户端服务器仅仅负责提交计算任
务给 Hadoop 集群,并当 Hadoop 集群完成任务后,客户端服务器来拿走计算结果。在一个较小的集群中(40个节点左
右),可能一台服务器会扮演多个角色,例如通常我们会将 Name Node 与 Job Tracker安置在同一台服务器上。(由于
Name Node对内存开销非常大,因此不赞成将 Name Node 与 Secondary Name Node 安置在同一台机器上)。而在一个大
型的集群中,请无论如何要保证这三者分属于不同的机器。
在真实的集群环境中,Hadoop 最好运行在 Linux 服务器上。当然,Hadoop 也可以运行在虚拟机中,但是,这仅仅是用来学
习的一种方法,而不能将其用在生产环境中。
下载后可阅读完整内容,剩余9页未读,立即下载
2018-01-09 上传
2020-07-11 上传
2013-11-11 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38686267
- 粉丝: 6
- 资源: 945
 我的内容管理
展开
我的内容管理
展开







最新资源
- CtfGit:Pagina Del Curso de Programacion
- 340-project-3
- 资产服务器2
- Accuinsight-1.0.34-py2.py3-none-any.whl.zip
- Motion-Detector-with-OpenCV:Python OpenCV项目
- ProcessX:使用C#8.0中的异步流来简化对外部进程的调用
- BELabCodes:这些是我在 BE 期间作为实验室实验编写的代码集合
- screwdriver:Dart包,旨在提供有用的扩展和辅助功能,以简化和加速开发
- cliffordlab.github.io:实验室网站
- 每日报告
- Meter:与MetricKit进行交互的库
- nova-api:新资料库
- marketplace_stat:虚幻市场统计可视化工具
- Blanchard__课程
- 2P_cellAttached_pipeline:2P单元贴记录管道
- kalkulator
