大模型显存占用与训练效率分析
需积分: 5 20 浏览量
更新于2024-06-16
收藏 15.34MB PDF 举报
"06TrainingMemory.pdf - 一个关于大模型显存占用分析的课程资料,探讨了Transformer架构,大模型参数量计算,训练时间估计以及显存(HBM)占用分析。"
在当前的AI领域,大模型的训练和应用已经成为研究与发展的热点。这些模型,尤其是Transformer架构的变体,如GPT系列,由于其在自然语言处理(NLP)和计算机视觉(CV)任务中的优异表现,不断推动着参数规模和数据集大小的边界。随着模型参数量的增加,计算需求和显存占用也随之飙升,给训练带来了严峻的挑战。
首先,Transformer模型是2017年提出的一种序列建模架构,由 Vaswani 等人在论文《Attention is All You Need》中首次介绍。该架构通过自注意力机制,使得模型能够同时处理序列中的所有位置,而不仅仅是相邻的位置,这在处理长序列信息时具有优势。Transformer架构的成功催生了诸如GPT-1、GPT-2、GPT-3等大型预训练模型,它们的参数量从1.17亿增长到1750亿,甚至预训练数据集的规模也达到了TB级别。
然而,随着模型规模的扩大,训练过程中显存管理成为关键问题。大模型可能需要数百GB乃至TB级别的HBM(高性能内存)来存储中间计算结果和权重。例如,GPT-4虽然参数规模未知,但其预训练数据集预计达到45TB,暗示了其对硬件资源的巨大需求。与此同时,Switch Transformer和Megatron-LM等模型也在不断挑战计算效率和显存效率的极限,前者参数量达到了惊人的1.6万亿,后者则有5300亿参数。
训练大模型时,面临的主要挑战可以归纳为显存效率和计算效率。显存效率涉及到如何有效地利用有限的显存资源,避免频繁的数据交换导致的性能损失。计算效率则关注如何在保证模型质量的同时,减少训练时间和计算资源消耗。这通常涉及模型并行、数据并行等优化策略,如Megatron-LM项目中采用的模型分片技术。
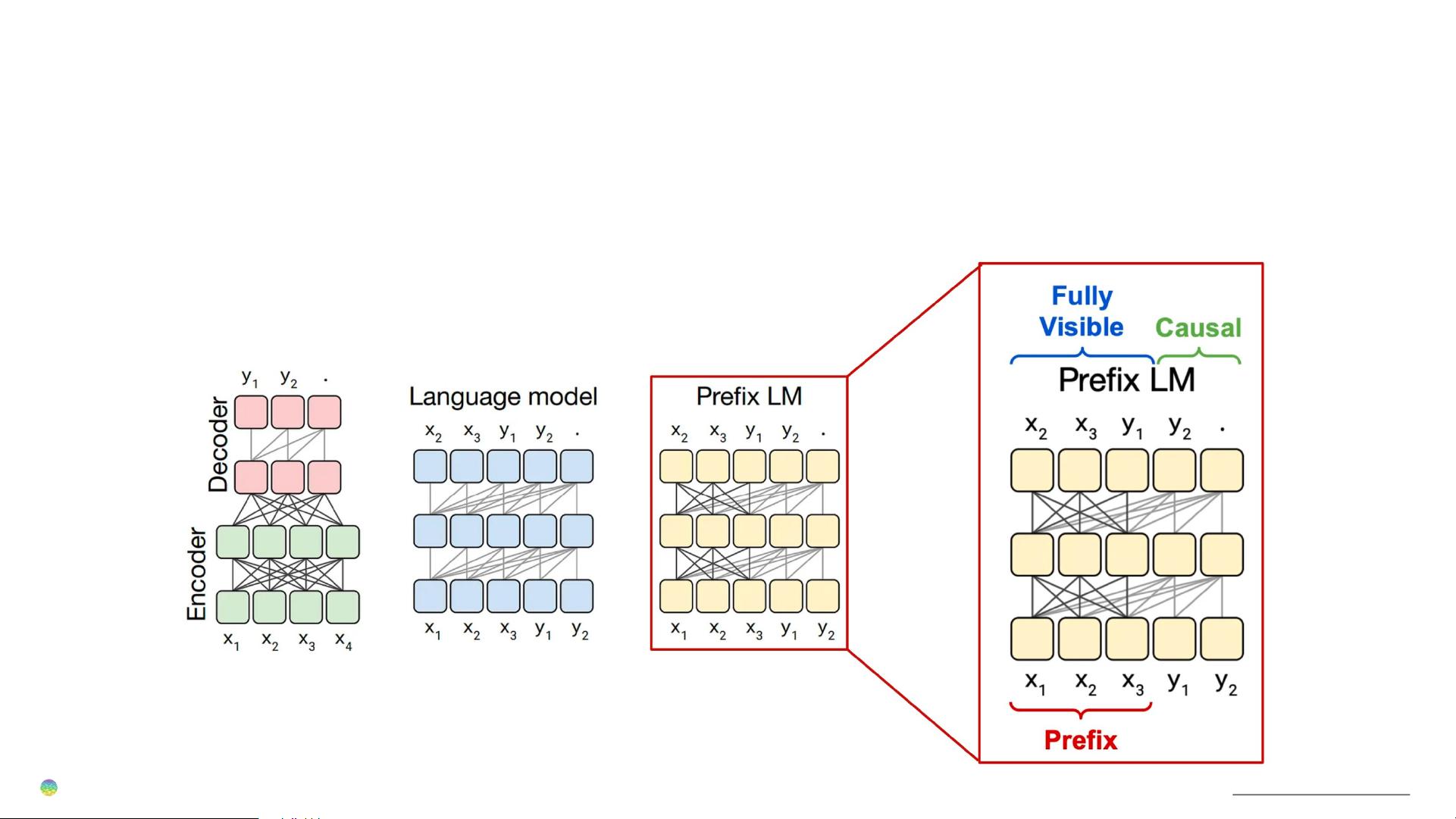
在大模型结构方面,当前的主流是基于Transformer的架构,分为encoder-decoder和decoder-only两类。encoder-decoder模型常用于机器翻译等双向信息处理任务,而decoder-only模型如GPT系列则专用于生成任务,通过前向传播预测下一个词,且在训练时仅依赖于输入序列的先前部分,这就是所谓的CausalLM。GLM(Generative Language Model with Memory)是另一种decoder-only模型,属于PrefixLM,它引入了前缀记忆,提高了模型的灵活性和效率。
大模型的显存占用分析是AI研究与工程的重要课题,需要深入理解模型架构、参数规模、数据集大小和训练策略,以便优化计算资源的使用,提升训练效率,同时保持模型的高性能。对于开发者和研究人员来说,掌握这些知识至关重要,以便在实际工作中应对不断增大的模型规模带来的挑战。

剩余38页未读,继续阅读
2024-10-14 上传
2024-10-14 上传

LittleBrightness
- 粉丝: 0
- 资源: 144
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言快速排序算法的实现与应用
- KityFormula 编辑器压缩包功能解析
- 离线搭建Kubernetes 1.17.0集群教程与资源包分享
- Java毕业设计教学平台完整教程与源码
- 综合数据集汇总:浏览记录与市场研究分析
- STM32智能家居控制系统:创新设计与无线通讯
- 深入浅出C++20标准:四大新特性解析
- Real-ESRGAN: 开源项目提升图像超分辨率技术
- 植物大战僵尸杂交版v2.0.88:新元素新挑战
- 掌握数据分析核心模型,预测未来不是梦
- Android平台蓝牙HC-06/08模块数据交互技巧
- Python源码分享:计算100至200之间的所有素数
- 免费视频修复利器:Digital Video Repair
- Chrome浏览器新版本Adblock Plus插件发布
- GifSplitter:Linux下GIF转BMP的核心工具
- Vue.js开发教程:全面学习资源指南
