理解和应用聚类算法:从K-means到谱聚类
该资源主要介绍了聚类算法的基础知识,包括最大熵模型、决策树、Logistic回归等概念,并重点讲解了K-means聚类、层次聚类、密度聚类(如DBSCAN和密度最大值聚类)以及谱聚类。
在机器学习中,聚类是一种无监督学习方法,用于将数据集中的样本根据其内在相似性分成不同的组或簇,目的是使得同一簇内的样本相似度较高,不同簇间的样本相似度较低。聚类不依赖于预先存在的标签,而是通过数据本身的特性进行分组。
最大熵模型在建立模型时,经常利用熵作为不确定性度量,如在决策树构建过程中,特征选择就可能涉及熵的计算。Logistic回归是一种分类算法,其对数似然函数是凹函数,通过梯度上升法求解得到的参数是全局最优解。
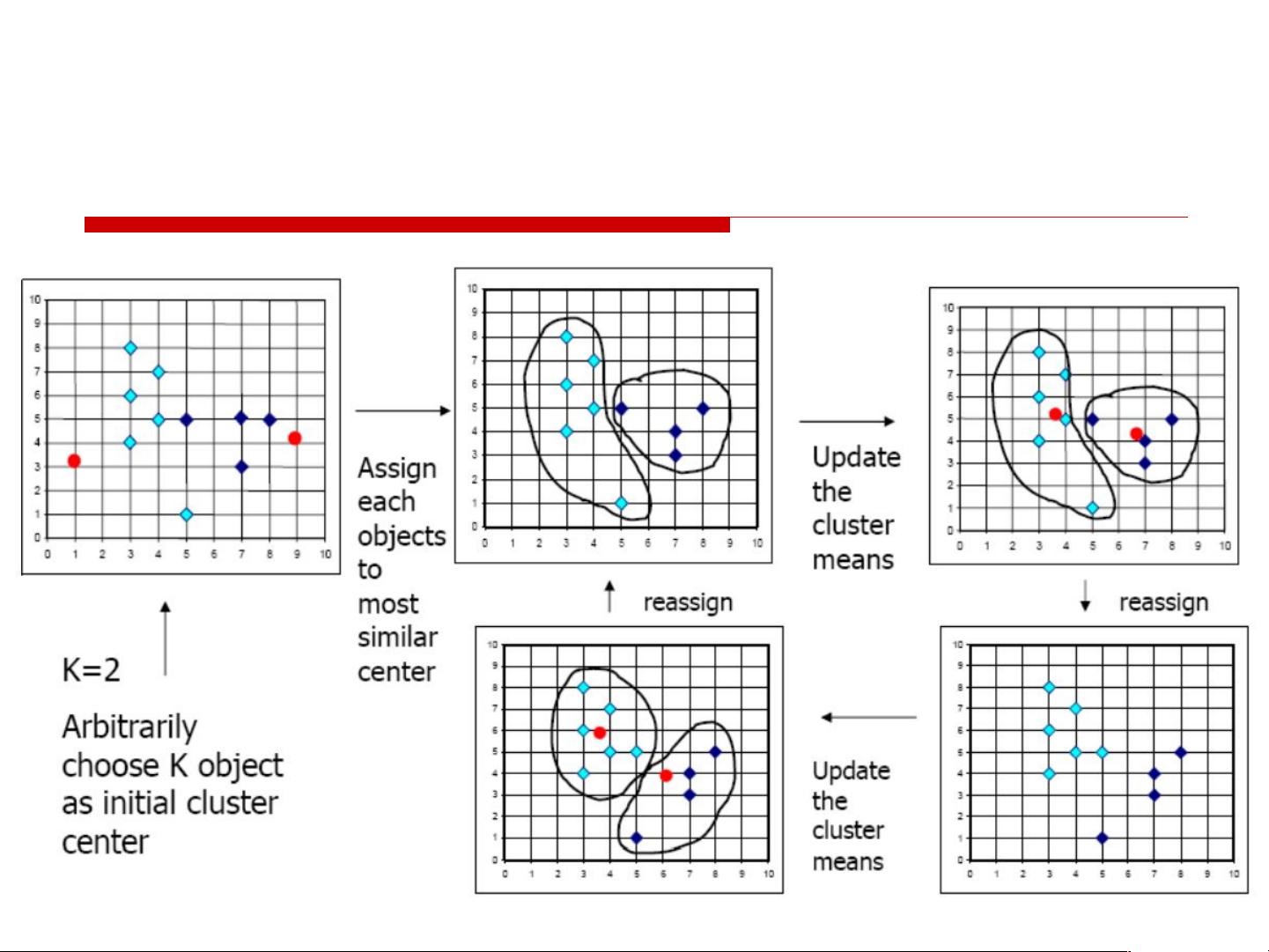
K-means算法是最常用的聚类方法之一,它需要预先设定簇的数量k。算法首先随机选取k个初始中心点,然后将每个样本分配到最近的簇,接着更新簇的中心为该簇所有样本的平均值,这个过程持续进行直至簇中心不再显著变化,即达到收敛。K-means算法对初始中心点的选择敏感,不同的初始化可能导致不同的聚类结果。
层次聚类提供了另一种聚类策略,可以是自顶向下( divisive)或自底向上(agglomerative)。自底向上方法从每个单独的样本开始,逐步合并相似的样本形成簇。
密度聚类如DBSCAN(Density-Based Spatial Clustering of Applications with Noise)算法,它不依赖于预先设定的簇数量,而是基于样本的密度来识别簇。DBSCAN可以发现任意形状的簇,并且对离群点具有较好的处理能力。密度最大值聚类是另一种基于密度的聚类方法,寻找局部密度最高的点作为簇中心。
谱聚类则是利用数据的相似性矩阵构造图谱,通过图的拉普拉斯矩阵进行特征分解,从而确定簇的数量和簇的结构。这种方法对于非凸形状的簇识别效果较好。
在计算样本之间的相似度时,有多种度量方式,如欧式距离、杰卡德相似系数和余弦相似度。其中,欧式距离是基于欧几里得空间的直线距离,杰卡德相似系数衡量两个集合的交集与并集的比例,余弦相似度则关注两个向量方向的相似性而非大小。
该资源提供了聚类算法的全面概述,涵盖了从基础理论到具体算法实现,对于理解和应用聚类技术具有很高的价值。

11/65
聚类的基本思想
给定一个有 N 个对象的数据集,划分聚类技术将构
造数据的 k 个划分,每一个划分代表一个
簇, k≤n 。也就是说,聚类将数据划分为 k 个簇,
而且这 k 个划分满足下列条件:
每一个簇至少包含一个对象
每一个对象属于且仅属于一个簇
基本思想:对于给定的 k ,算法首先给出一个初始
的划分方法,以后通过反复迭代的方法改变划分,
使得每一次改进之后的划分方案都较前一次更好。

剩余63页未读,继续阅读
2024-09-14 上传
2024-08-16 上传
2024-08-16 上传
360 浏览量
225 浏览量
2024-06-30 上传

Aron2001_
- 粉丝: 1
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- 绿色叶子图标下载
- PHPCMS 企业黄页模块 v9 UTF-8 正式版
- Mandelbrot set vectorized:使用矢量化代码生成 Mandelbrot 集。-matlab开发
- PROALG-1C-EDU:教授安德森教授课程的口语和口语
- 卡通加菲猫图标下载
- Sass-Mixins:普通的Sass mixins
- 测验
- Peachtree-Bank
- 蝴蝶贝壳花朵图标下载
- Chebyshev Series Product:计算两个 Chebyshev 展开式的乘积。-matlab开发
- smartos-memory:列出交互式远程Shell会话中SmartOS上的VM使用的内存
- 完整版读易库到超级列表框1.0.rar
- 2019-2020年快消零售小店B2B竞争力报告精品报告2020.rar
- supply-mission2
- 卡通动物图标下载
- MAC0350:软件开发入门课程(MAC0350)的讲座和作业库
