CUDA编程入门:掌握Nvidia GPU并行计算
本资源是一份关于NVIDIA CUDA平台的入门教程,针对初学者设计,详细介绍了CUDA的计算统一设备架构(CUDA-CU)编程模型。CUDA是NVIDIA公司专为加速GPU(图形处理单元)计算而设计的一种并行编程技术,它使得开发者能够利用GPU的强大并行处理能力来提升应用程序性能。
1. **CUDA概述**:
CUDA提供了一个可伸缩的并行编程模型,允许开发者将部分代码段运行在GPU上,其余在CPU上执行,实现了CPU与GPU的协同工作。GPU的特点是拥有高度并行化、多线程和多核处理器,这使得它可以同时处理大量数据。
2. **编程模型**:
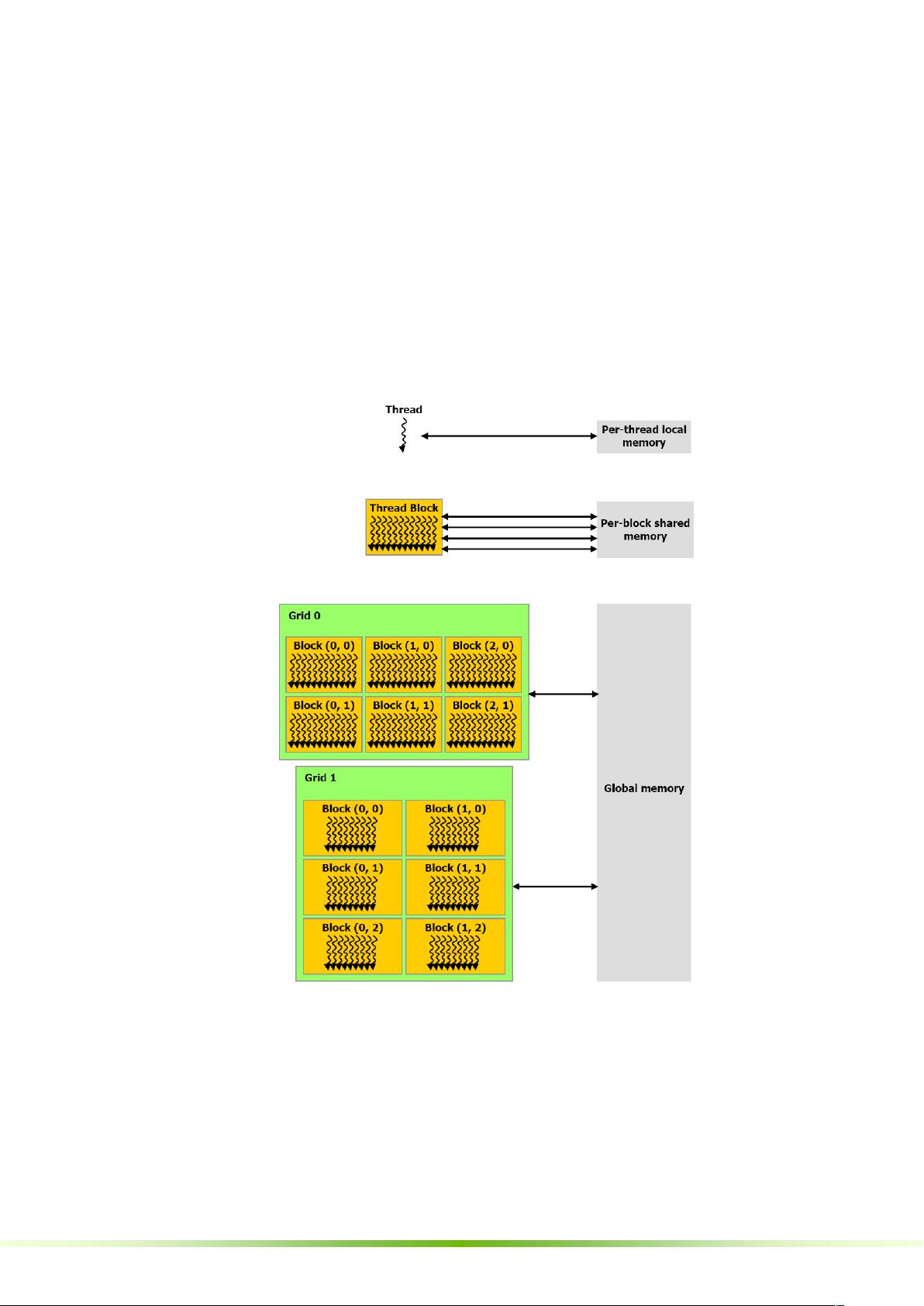
- **线程层次结构**:CUDA采用分层的线程组织方式,包括线程块(block)和线程(thread),以及全局范围内的线程集合。
- **存储器层次结构**:包括全局内存(主存)、共享内存(在SM之间共享)、局部存储(每个线程块内)等,有效管理数据访问。
- **主机与设备**:区分了CPU(主机)和GPU(设备)编程环境,数据和指令在两者间传输。
3. **GPU硬件特性**:
- **SIMT多处理器**:每块GPU包含一组共享存储器的SIMT(Single Instruction Multiple Threads)处理器,允许多个线程同时执行相同的指令。
- **多设备支持**:教程提及了多个设备的处理,可能涉及集群或多个GPU的协同工作。
- **模式切换**:可能是指程序在主机和设备之间的执行模式切换。
4. **API细节**:
- **C语言扩展**:教程深入讲解了CUDA如何扩展C语言,如添加特定的函数类型限定符(如_device_, _global_, _host_)来指定代码运行的位置。
- **变量类型限定符**:区分了常量、共享和局部变量,以及它们的使用规则和限制。
- **执行配置**:介绍了内置的gridDim, blockIdx, blockDim等变量,用于描述线程网格和块的配置。
- **编译选项**:讲解了如何使用NVCC编译器的选项,如_noinline_和#pragmaunroll优化指令。
5. **通用运行时组件**:
- **内置向量类型**:提供了一套丰富的向量数据类型,包括基本整数和浮点数。
- **数学函数**:涵盖一系列数学运算,如算术、逻辑和比较操作。
- **计时函数**:用于测量计算时间,评估性能。
- **纹理类型**:涉及纹理对象的声明、属性管理和从线性内存到CUDA数组的数据映射。
这份教程是CUDA编程的入门指南,覆盖了CUDA平台的基础概念、编程模型、硬件特性以及核心API的使用,非常适合想要涉足GPU加速计算的新手学习者。通过理解这些内容,读者可以开始编写自己的CUDA程序,充分利用GPU的并行计算能力。

第 2 章 编程模型
CUDA 允许程序员定义称为内核(kernel)的 C 语言函数,从而扩展了 C 语言,在调用此类函数时,它将
由 N 个不同的 CUDA 线程并行执行 N 次,这与普通的 C 语言函数只执行一次的方式不同。
在定义内核时,需要使用 _global_ 声明说明符,使用一种全新的 <<<…>>> 语法指定每次调用的 CUDA
线程数:
// Kernel definition
__global__ void vecAdd(float* A, float* B, float* C)
{
}
int main()
{
// Kernel invocation
vecAdd<<<1, N>>>(A, B, C);
}
执行内核的每个线程都会被分配一个独特的线程 ID,可通过内置的 threadIdx 变量在内核中访问此 ID。
以下示例代码将大小为 N 的向量 A 和向量 B 相加,并将结果存储在向量 C 中:
__global__ void vecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// Kernel invocation
vecAdd<<<1, N>>>(A, B, C);
}
执行 vecAdd( ) 的每个线程都会执行一次成对的加法运算。
2.1 线程层次结构
为方便起见,我们将 threadIdx 设置为一个包含 3 个组件的向量,因而可使用一维、二维或三维缩影标识
线程,构成一维、二维或三维线程块。这提供了一种自然的方法,可为一个域中的各元素调用计算,如
向量、矩阵或字段。下面的示例代码将大小为 NxN 的矩阵 A 和矩阵 B 相加,并将结果存储在矩阵 C 中:
__global__ void matAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
// Kernel invocation
dim3 dimBlock(N, N);
matAdd<<<1, dimBlock>>>(A, B, C);
}
线程的索引及其线程 ID 有着直接的关系:对于一维块来说,两者是相同的;对于大小为 (D
x
,
D
y
) 的二维
块来说,索引为 (x,y) 的线程的 ID 是 (x + yD
x
);对于大小为 (D
x
,
D
y
,
D
z
) 的三维块来说,索引为
(x, y, z) 的线程的 ID 是 (x + yD
x + Z
D
x
D
y
)。
4 CUDA 编程指南,版本 2.0

剩余63页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2018-06-09 上传
2012-11-20 上传
2022-09-14 上传
2018-02-26 上传
点击了解资源详情

zhudongfangshiwo
- 粉丝: 1
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
