品友互动:Hadoop Flume日志收集与优化详解
Hadoop Flume优化是一个关于在品友互动的业务环境中利用Apache Flume进行大规模日志收集、处理和传输的深入探讨。Flume作为Hadoop生态系统中的一个重要组件,专用于ETL(Extract, Transform, Load)任务,主要负责实时监控、捕获和传输海量的日志数据,确保数据的完整性、可靠性以及高效处理。
首先,背景部分介绍了Flume在互联网行为定向广告技术中的挑战和优化需求。品友互动利用Flume来处理来自不同源,如Web服务器的日志,这些日志需要经过收集、清洗和存储以便后续分析和挖掘价值信息。
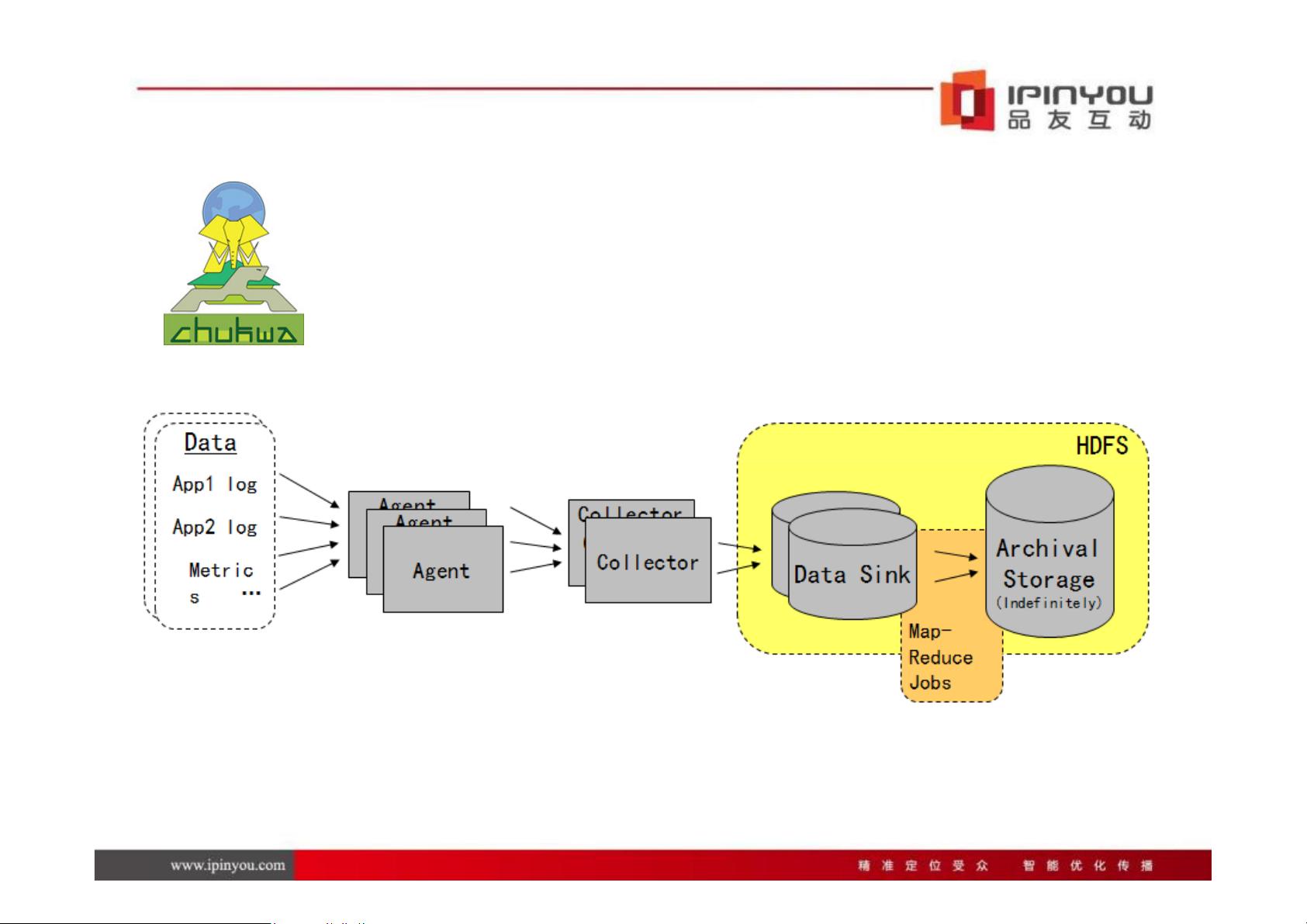
日志收集系统是关键环节,文章介绍了几种常见的解决方案,包括Scribe、Chukwa和Flume。Flume因其独特的设计脱颖而出,它将数据路径划分为多个节点(Nodes),每个节点包含一个或多个Source(数据源)和Sink(数据目的地)。这种结构允许灵活地定义数据流,比如通过心跳检测机制保持节点间的通信,并能方便地配置和管理Sources和Sinks。
Flume的核心优势在于其可扩展性。简单易用的Source和Sink API使得开发者能够轻松创建和组合定制化的数据处理逻辑,同时基于事件流的设计使得复杂操作变得可行。这种灵活性使得Flume适应不断变化的业务需求,能够随着数据量的增长而进行无缝扩展。
优化方面,可能涉及到性能调优、故障恢复策略、数据一致性保障、以及如何有效地利用Hadoop集群资源。例如,可能通过调整Source和Sink的配置、优化数据传输的网络带宽使用、或者引入中间缓存来提高吞吐量。此外,对数据格式的标准化和压缩处理也可能在性能优化中起到重要作用。
总结来说,这篇文章深入讲解了品友互动在实际项目中如何运用Flume进行日志收集的系统架构设计,以及如何通过Flume的特性和设计优化,提升日志处理的效率和稳定性,以支持其新一代互联网广告定向技术的发展。通过学习和实践这些优化策略,读者可以更好地理解和应用Flume在大数据处理场景下的价值。
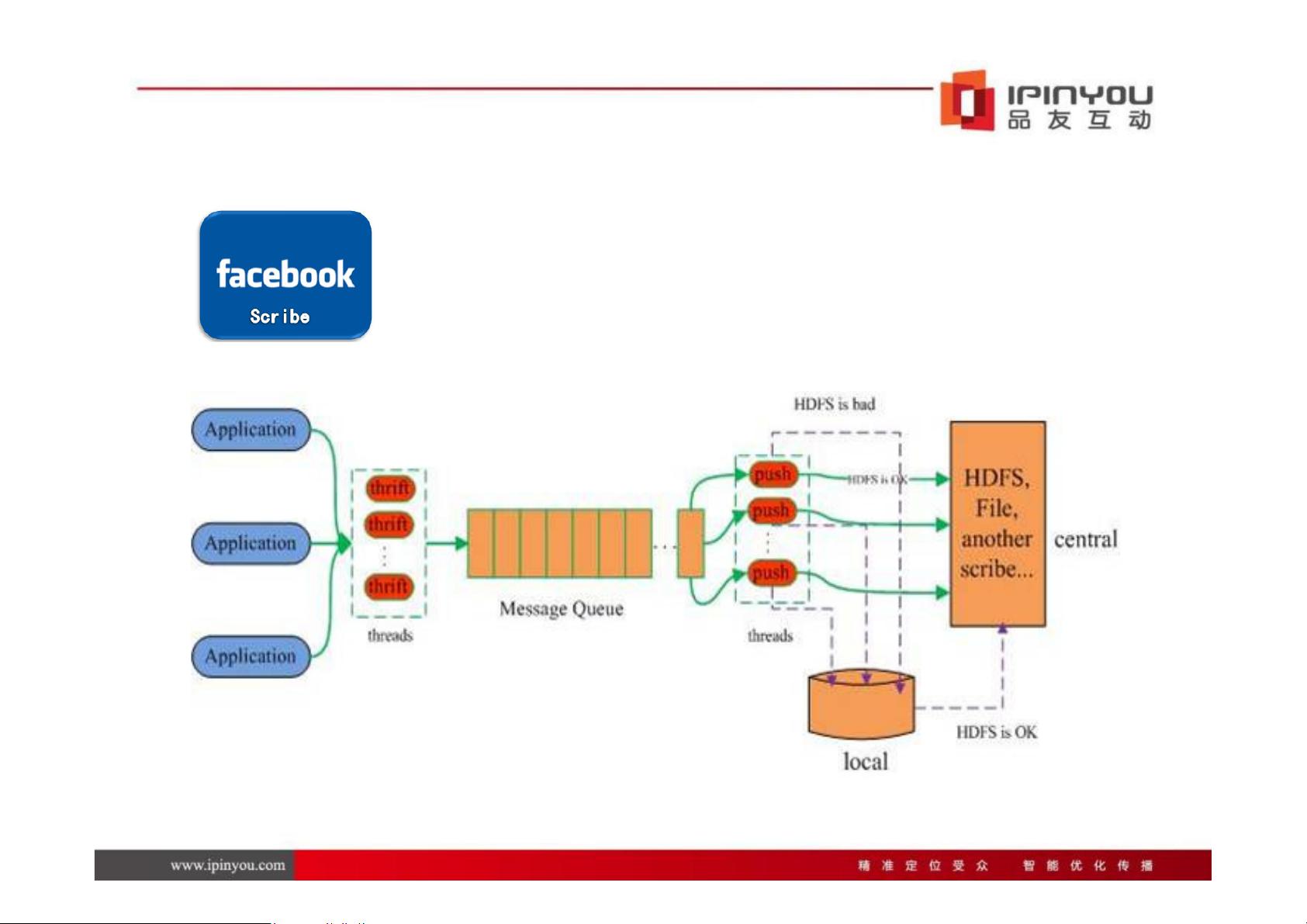
日志收集系统介绍——Scribe
Copyright@2012 iPinyou All Rights Reserved.
剩余37页未读,继续阅读
2024-03-13 上传
2024-03-13 上传
537 浏览量
103 浏览量
点击了解资源详情
点击了解资源详情
111 浏览量
点击了解资源详情
103 浏览量

cfy_yinwenhao
- 粉丝: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android PRDownloader库:支持文件下载暂停与恢复功能
- Xilinx FPGA开发实战教程(第2版)精解指南
- Aprilstore常用工具库的Java实现概述
- STM32定时开关模块DXP及完整项目资源下载指南
- 掌握IHS与PCA加权图像融合技术的Matlab实现
- JSP+MySQL+Tomcat打造简易BBS论坛及配置教程
- Volley网络通信库在Android上的实践应用
- 轻松清除或修改Windows系统登陆密码工具介绍
- Samba 4 2级免费教程:Ubuntu与Windows整合
- LeakCanary库使用演示:Android内存泄漏检测
- .Net设计要点解析与日常积累分享
- STM32 LED循环左移项目源代码与使用指南
- 中文版Windows Server服务卸载工具使用攻略
- Android应用网络状态监听与质量评估技术
- 多功能单片机电子定时器设计与实现
- Ubuntu Docker镜像整合XRDP和MATE桌面环境
