PyTorch进阶:理解Tensor数据类型、设备与内存布局
165 浏览量
更新于2024-08-28
收藏 123KB PDF 举报
PyTorch 是一个广泛应用于深度学习的开源库,本文主要聚焦在 PyTorch 中的 Tensor(张量)及其基础操作。张量是 PyTorch 中的核心概念,它类似于 NumPy 的数组,但具有更强大的功能,特别是在 GPU 加速计算方面。
首先,让我们了解一下 PyTorch 中的 Tensor Attributes。这里有三个重要的属性类别:
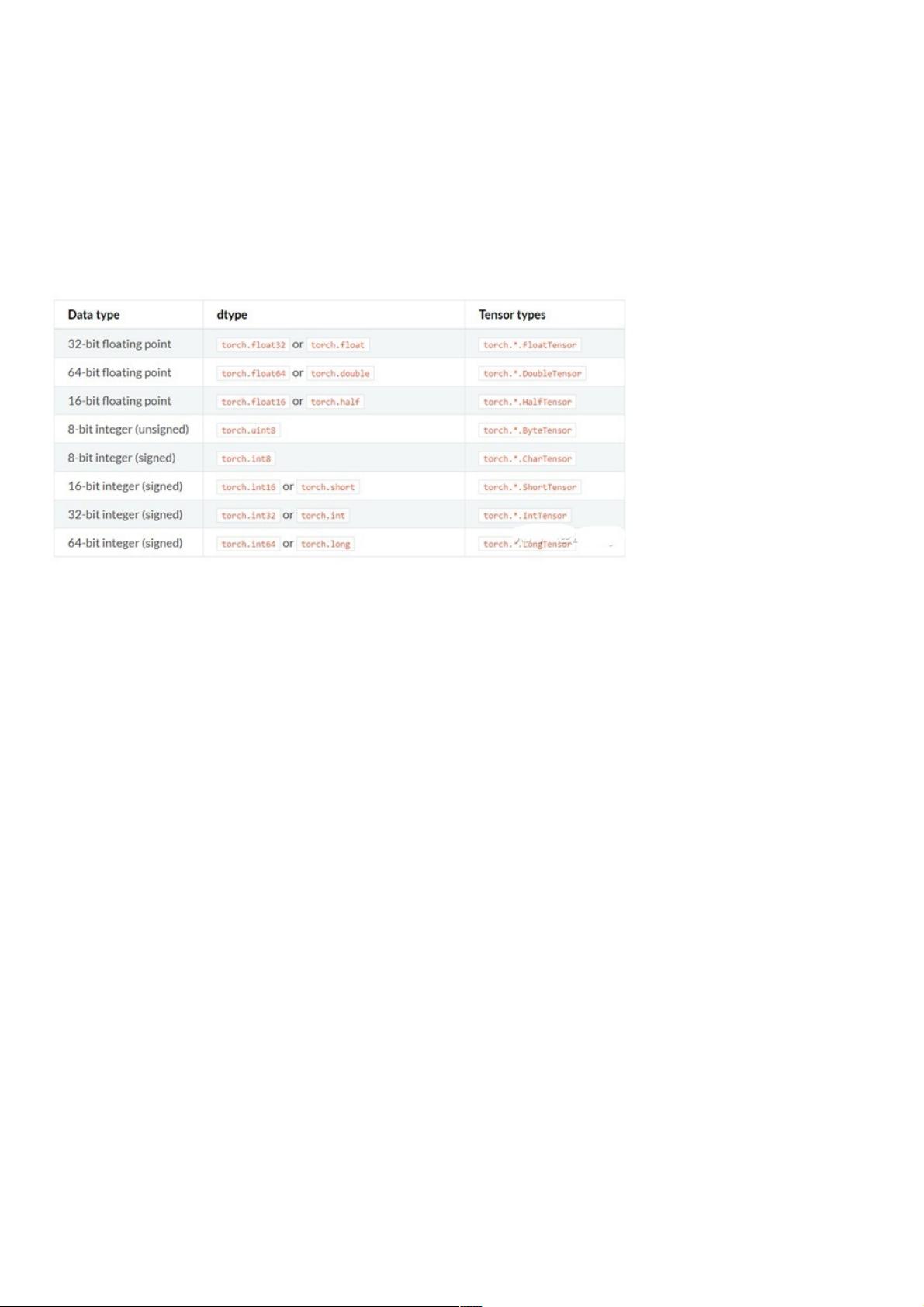
1. torch.dtype:这是用来表示 torch.Tensor 数据类型的类,PyTorch 支持八种内置数据类型,包括 float、double、int、long、half、byte、char、short 等。这些数据类型对于选择合适的张量内存格式和计算精度至关重要。例如,对于浮点数运算,float32(单精度浮点数)可能比 half(半精度浮点数)更适合,而 int64 对于存储大整数更为适用。
2. torch.device:这个类用于表示张量被分配到的设备类型,主要有 CPU 和 CUDA(图形处理单元)两种。CPU 是默认设备,而 CUDA 则允许利用GPU进行并行计算,显著提升计算速度。`torch.device`对象可以通过字符串 'cuda' 或 'cpu',以及指定的序号(如 'cuda:0' 或 'cpu:0')来创建,如果没有显式指定序号,则默认使用当前设备。
3. torch.layout:虽然目前仅支持 `torch.strided` 类型,但它代表了张量在内存中的布局方式。`strided` 表示张量可以被高效地遍历,这对于许多常见的深度学习操作来说是必要的。然而,由于篇幅限制,这里未深入讨论其他可能的布局类型。
创建张量的方法有多种,可以直接使用 `torch.tensor` 函数传入数据和数据类型,或者利用 `torch.randn`、`torch.zeros`、`torch.ones` 等函数生成随机或特定初始值的张量。在操作张量时,可以使用 `.to(device)` 方法将其从一个设备移动到另一个设备,如从 CPU 转移到 GPU 或反之。
理解并熟练运用 PyTorch 的 Tensor 类型、设备管理和布局,对于开发高效的深度学习模型至关重要。通过合理使用 `torch.dtype`、`torch.device`,开发者可以有效地优化计算性能,提高训练速度,这对于大规模的数据处理和模型训练尤其关键。在实际操作中,记得根据任务需求选择合适的数据类型,合理配置设备,并确保内存布局符合张量操作的性能要求。
PyTorch | ((3))Tensor及其基本操作及其基本操作
PyTorch | (1)初识PyTorch
PyTorch | (2)PyTorch 入门-张量
PyTorch | (3)Tensor及其基本操作
Tensor attributes:
在tensor attributes中有三个类,分别为torch.dtype, torch.device, 和 torch.layout
其中, torch.dtype 是展示 torch.Tensor 数据类型的类,pytorch 有八个不同的数据类型,下表是完整的 dtype 列表.
Torch.device 是表现 torch.Tensor被分配的设备类型的类,其中分为’cpu’ 和 ‘cuda’两种,如果设备序号没有显示则表示此
tensor 被分配到当前设备, 比如: ‘cuda’ 等同于 ‘cuda’: X , X 为torch.cuda.current _device() 返回值
我们可以通过 tensor.device 来获取其属性,同时可以利用字符或字符+序号的方式来分配设备
通过字符串通过字符串
torch.device('cuda:0')
运行结果:
device(type='cuda', index=0)
torch.device('cpu')
运行结果:
device(type='cpu')
torch.device('cuda') # 当前设备
运行结果:
device(type='cuda')
通过字符串和设备序号通过字符串和设备序号
torch.device('cuda', 0)
运行结果:
device(type='cuda', index=0)
torch.device('cpu', 0)
运行结果:
device(type='cpu', index=0)
下载后可阅读完整内容,剩余5页未读,立即下载
632 浏览量
2025-02-05 上传
2024-12-07 上传
291 浏览量
点击了解资源详情
102 浏览量
2347 浏览量
187 浏览量
105 浏览量

weixin_38522029
- 粉丝: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Installshield 12 教程:配置服务与数据库支持
- Installshield 12 教程:Installscript项目入门(一)
- Installshield 12 教程:配置目标系统与快捷方式
- VC++ 2005 快捷键大全与调试命令参考
- Qt对象模型:灵活性与高效结合的GUI解决方案
- Qt设计器入门与高级应用
- LoadRunner通过ODBC连接Oracle数据库详细教程
- HP-Unix上Oracle9i详细安装步骤
- OPC UA Part 4 - 服务规范1.01.05草案
- C++编程高质量指南:编程规范与最佳实践
- Liferay Portal 4.3.x 开发手册:Portlet入门与实践
- Liferay Portal二次开发详解:架构解析与实战指南
- Rational Rose vs PowerDesigner:建模工具深度对比
- SAP BC415详解:远程功能调用(RFC)与ABAP编程
- OPC UA Part 3详解:地址空间模型
- OPC UA Part 1:统一架构概念1.00规范简介
