异构特征与多视角姿态融合:行人检测的新突破
需积分: 9 127 浏览量
更新于2024-08-26
收藏 1.78MB PDF 举报
本文主要探讨了一种针对视觉行人检测问题的创新方法,发表在《IEEE Transactions on Intelligent Transportation Systems》(VOL.16, NO.2, APRIL 2015)上。作者Wei Liu、Bing Yu、Chengwei Duan、Liying Chai、Huai Yuan和Hong Zhao针对行人检测中面临的挑战,如行人外观多样性、光照变化和部分遮挡,提出了一种结合异构特征与多视角姿态部件集合的行人检测技术。
首先,异构特征的融合是核心部分。传统上,行人检测常用的是方向梯度直方图(Histogram of Oriented Gradients, HOG)和局部二值模式(Local Binary Pattern, LBP)这两种特征,它们分别对纹理和结构信息有良好的捕捉能力。然而,新方法在此基础上,设计了一种新颖的线性核函数,旨在更有效地整合这两种特性,增强行人描述符对光照条件和复杂背景的适应性。这种融合增强了特征表达的鲁棒性和区分度,有助于提高行人检测的准确性。
其次,为了应对行人姿态变化和遮挡问题,文章提出了一个多视角-姿态部件集合(Multi-View-Pose Part Ensemble, MVPPE)检测器。这个系统利用了多个视角下不同身体部位的信息,通过集成学习的方式,使得模型能够更好地理解行人从不同角度和被遮挡时的视觉表现。通过这种方法,即便是在复杂的场景中,模型也能更准确地定位和识别行人。
实验结果显示,该提出的特征组合策略显著提升了行人特征的描述能力,从而提高了行人检测的性能。在公共数据集上的测试表明,这种方法在面对各种挑战时表现出色,为视觉行人检测领域提供了一个有力的解决方案。这一研究成果对于提升智能交通系统的行人检测算法的鲁棒性和实用性具有重要意义,也为其他领域的目标检测任务提供了新的思路和借鉴。
LIU et al.: PEDESTRIAN-DETECTION BASED ON HETEROGENEOUS FEATURES AND ENSEMBLE OF MVP PARTS 815
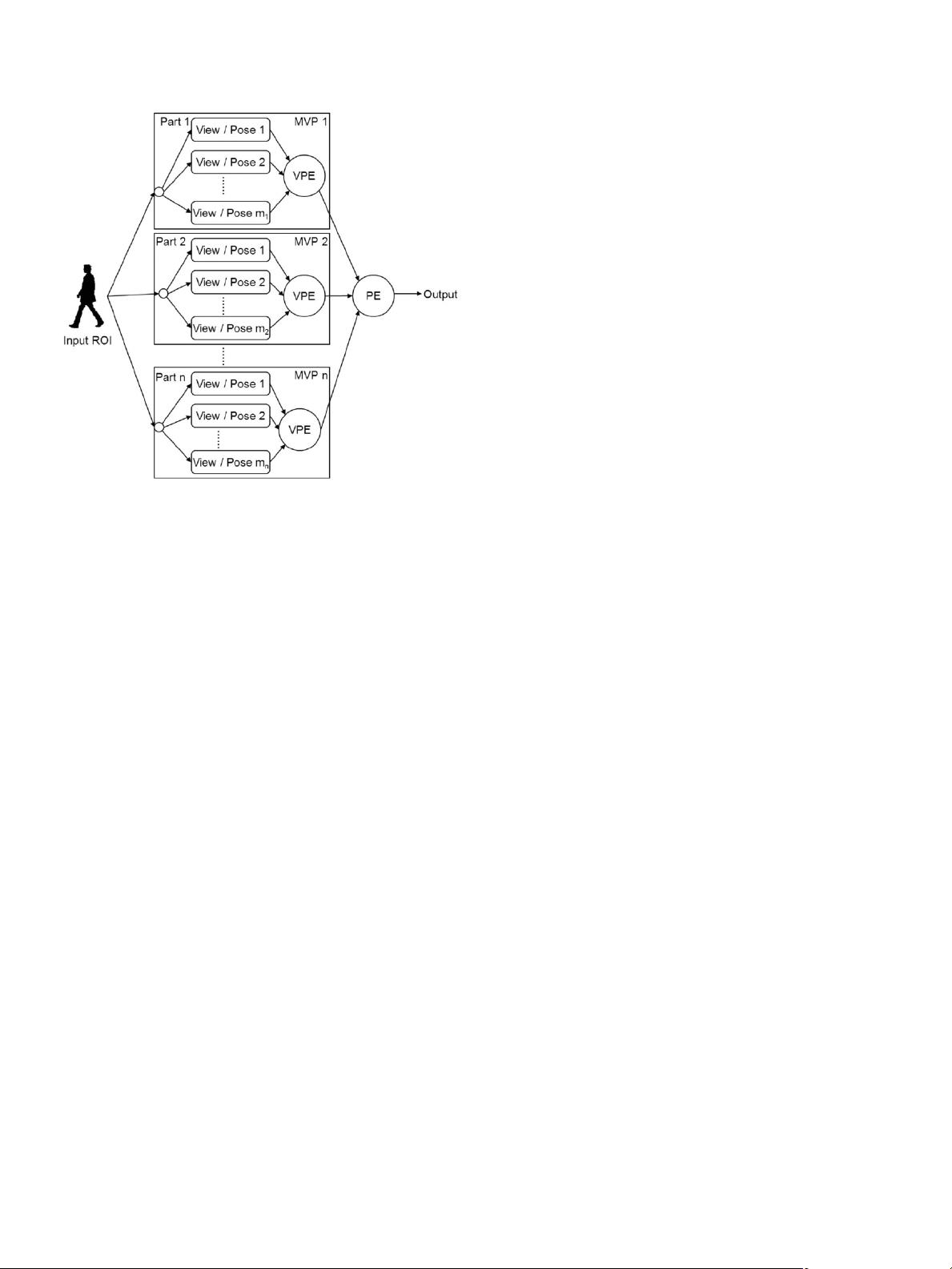
Fig. 1. General architecture of the proposed pedestrian detector.
A. Overview of the Proposed Pedestrian-Detection Method
The architecture of our proposed method is presented in
Fig. 1. Due to high variability in pedestrian appearance, the
pedestrian is divided into several body parts, and each body
part is treated from different viewing angles and poses, re-
spectively. The details of division of parts, poses, and views
are given in Section III-C and D. For each view or pose of
a certain body part, an expert classifier with heterogeneous
features (to be introduced in Section III-B) is trained. These
classifiers are assembled within a two-stage structure. The
first stage ensembles different views and poses of each body
part, with view–pose ensemble (VPE) functions, and forms
an MVP ensemble classifier for each body part. The second
stage combines all MVP body parts with a part ensemble
(PE) function. When an ROI is inputted to the detector, all
individual expert classifiers examine the ROI from their own
field of expertise, i.e., a certain viewing angle or pose of
a certain body part. After collecting the opinions from the
experts, the VPE functions combine the classification results
of body parts. Then, the PE function addresses the final
decision result.
B. Pedestrian Feature Description Based on Combination of
Heterogeneous Features
One important step in the process of pedestrian detection is
to perform a thorough and distinctive feature description of the
pedestrian. The commonly used features include HOG, color
feature, LBP, Haar wavelet, and motion feature. One single
feature could describe only a single aspect of the pedestrian,
such as contour, color, local region, or texture, and it only
has limited description power. To perform a better description
of the pedestrian, some literatures propose to use the combi-
nation of more than one feature to enhance the description
power, such as HOG–LBP [18] and HOG–CSS features [15].
HOG–LBP features extract contour and texture information,
simultaneously, and are among the best performing (and most
popular) feature sets available [35], [36]. Nevertheless, the
simple concatenation of the two feature vectors, as in [18],
does not take the contributions of both individual features into
account, and the description ability of the features is not fully
exploited. Inspired by [37], in this paper, a new linear kernel
function is proposed to combine the two heterogeneous features
with complementary information, as
K(x
i
, x
j
)=
m
k=0
(1 − β)x
H
ik
x
H
jk
+
n
k=0
βx
L
ik
x
L
jk
(1)
where K(x
i
, x
j
) represents the proposed kernel function; x
i
is the feature vector of sample i; x
i
=[x
H
i
,x
L
i
]; x
H
ik
,x
L
ik
rep-
resent the kth element of the feature vectors of HOG and
LBP, respectively; m and n are the dimensions of the feature
vectors of HOG and LBP. β is a combination coefficient, which
determines the contribution of each feature, and β ∈ [0, 1].
With (1), the contour feature and the local region feature
are combined organically, with consideration of their respective
contributions. One could notice that the simple concatenation
approach proposed in [18] is a special case of (1), where
the contributions of two features are considered to be equal,
and β = 0.5. Compared to the method in [18], our approach
significantly improves the description power of the feature
combination, without noticeable increase in computation cost.
In addition, compared to the RBF kernel function in [37],
our approach boosts less requirement of computation power.
Details are shown in Section IV-B.
In this paper, the extraction of HOG feature is the same
as [7]. LBP uses the same size of block (16 × 16) as HOG.
For each block, LBP generates a histogram with 58 uniform
patterns and 1 nonuniform pattern. The histograms of all blocks
are concatenated as the LBP feature vector of the input image.
As the size of the ROI is 48 × 96, the proposed heterogeneous
features describe the input image with a 5225-dimensional
feature vector.
C. Division of Body Parts
In order to handle possible partial occlusion, considering
both model complexity and detection accuracy, the pedestrian is
divided into three parts, i.e., UB, LB, and FB, which is the same
as the approach proposed in [9] and [25] (see Fig. 2). Every
part covers a fixed percentage of the pedestrian. UB and LB
take 50% of the body, whereas FB covers 100% of the body.
The horizontally occluded pedestrian could be detected with
such division of the body. For example, the pedestrian with
an umbrella on his shoulder [UB occluded; see Fig. 3(a)] can
be properly detected by examining the nonoccluded LB. As for
the pedestrian with vertical occlusions [see Fig. 3(c) and (d)], as
long as the occlusion is less than 30% of the body, such kind of
occlusion could be handled with adequate vertically occluded
samples in the training data set.
剩余11页未读,继续阅读
2019-07-22 上传
2021-09-23 上传
2021-07-14 上传
2023-06-14 上传
2023-04-01 上传
2024-10-31 上传
2023-06-06 上传
2023-07-05 上传
2024-10-31 上传

weixin_38641366
- 粉丝: 4
- 资源: 893
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
