

(withrespecttotheevaluationmeasureE).Ontheotherhand,ifEissensitive
totheskew(e.g.,precisionor -measure),thenweneedtoensurethatthe
skewofthevalidationsetusedforselecting issimilartothatofthetestset,
sothattheclassifierformedusing showsoptimaltestperformancewith
respecttoE.Alternatively,givenanestimateoftheskewofthetestdata, ,
wecanuseitalongwiththeTPRandTNRonthevalidationsettoestimateall
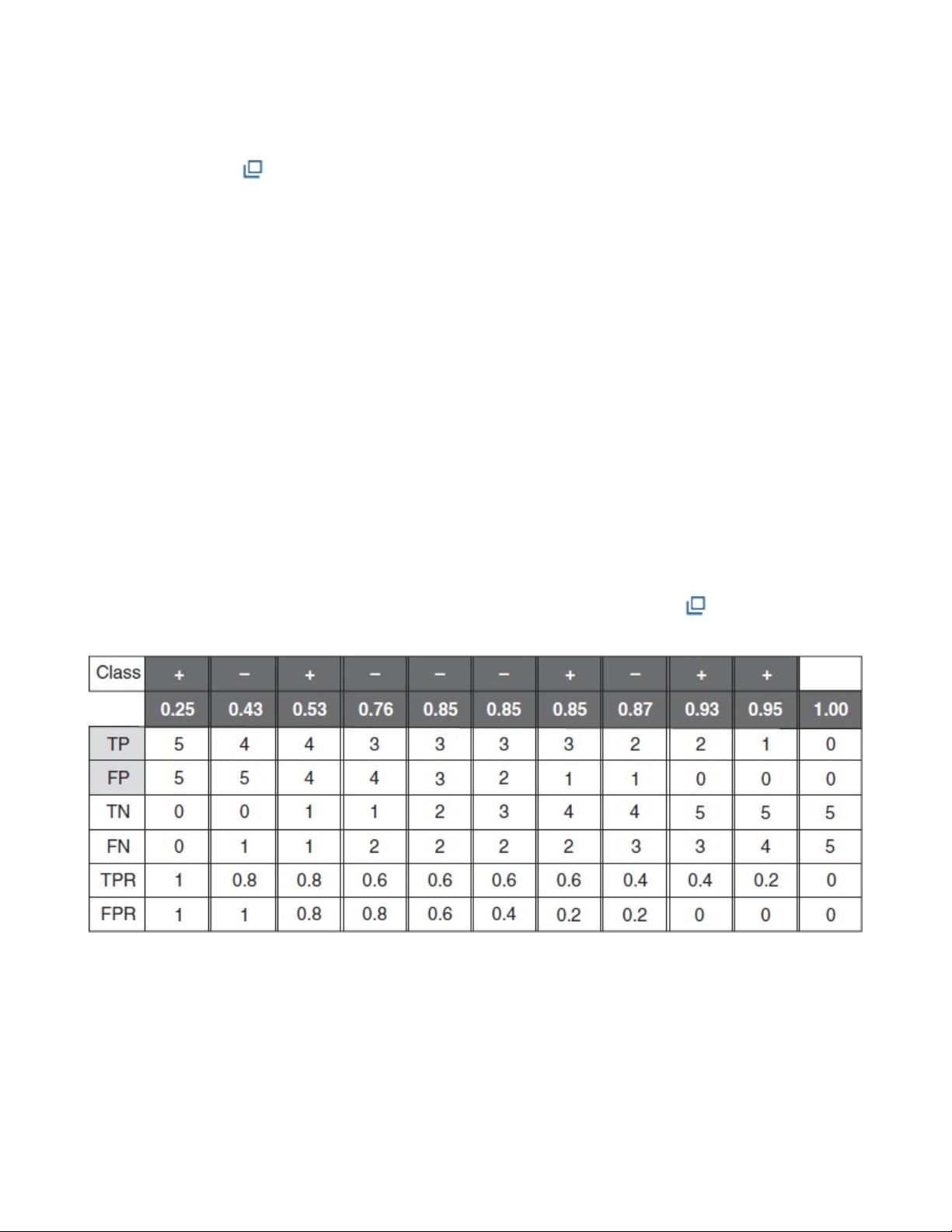
entriesoftheconfusionmatrix(seeTable4.7 ),andthustheestimateof
anyevaluationmeasureEonthetestset.Thescorethreshold selected
usingthisestimateofEcanthenbeexpectedtoproduceoptimaltest
performancewithrespecttoE.Furthermore,themethodologyofselecting
onthevalidationsetcanhelpincomparingthetestperformanceofdifferent
classificationalgorithms,byusingtheoptimalvaluesof foreachalgorithm.
4.11.4AggregateEvaluationof
Performance
Althoughtheaboveapproachhelpsinfindingascorethreshold that
providesoptimalperformancewithrespecttoadesiredevaluationmeasure
andacertainamountofskew, ,sometimesweareinterestedinevaluating
theperformanceofaclassifieronanumberofpossiblescorethresholds,
eachcorrespondingtoadifferentchoiceofevaluationmeasureandskew
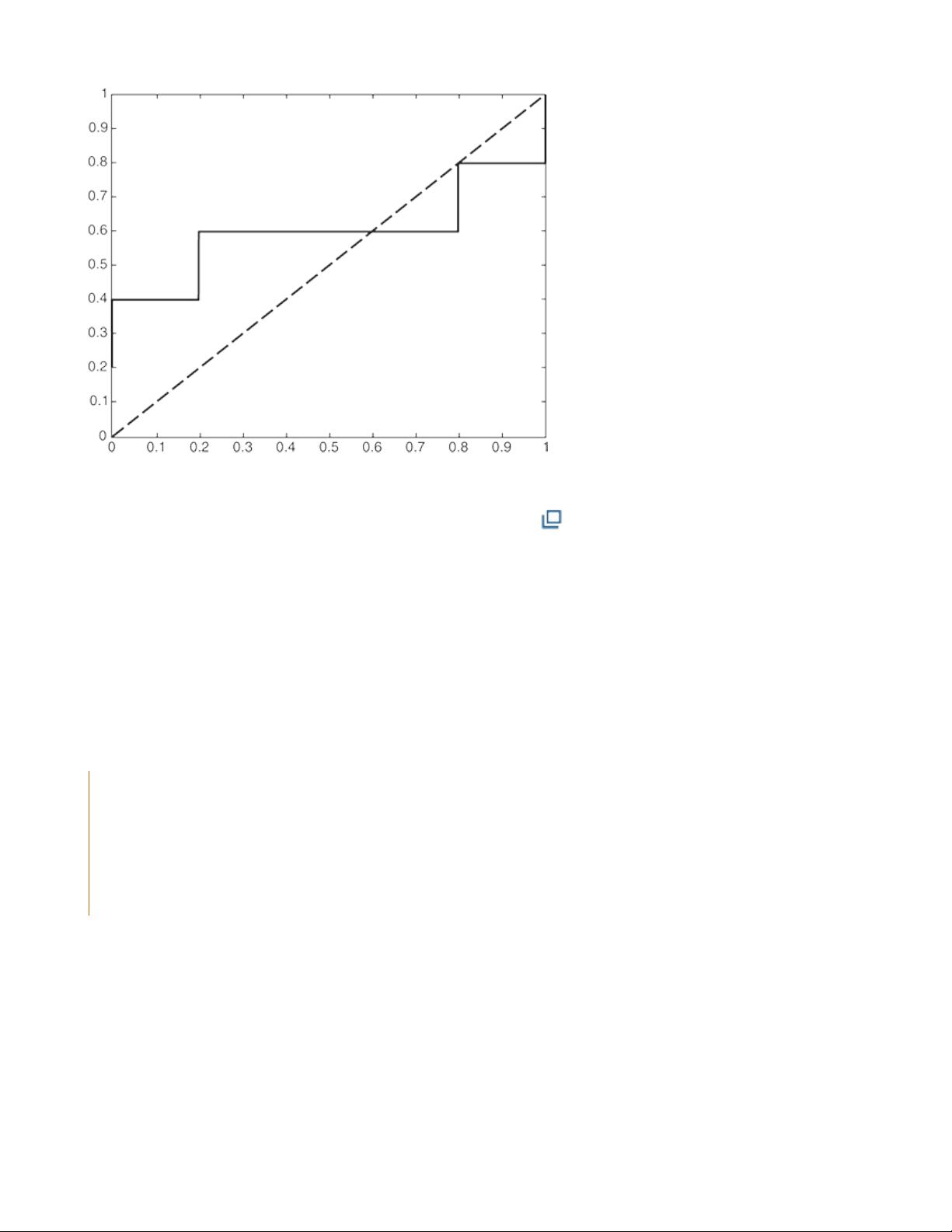
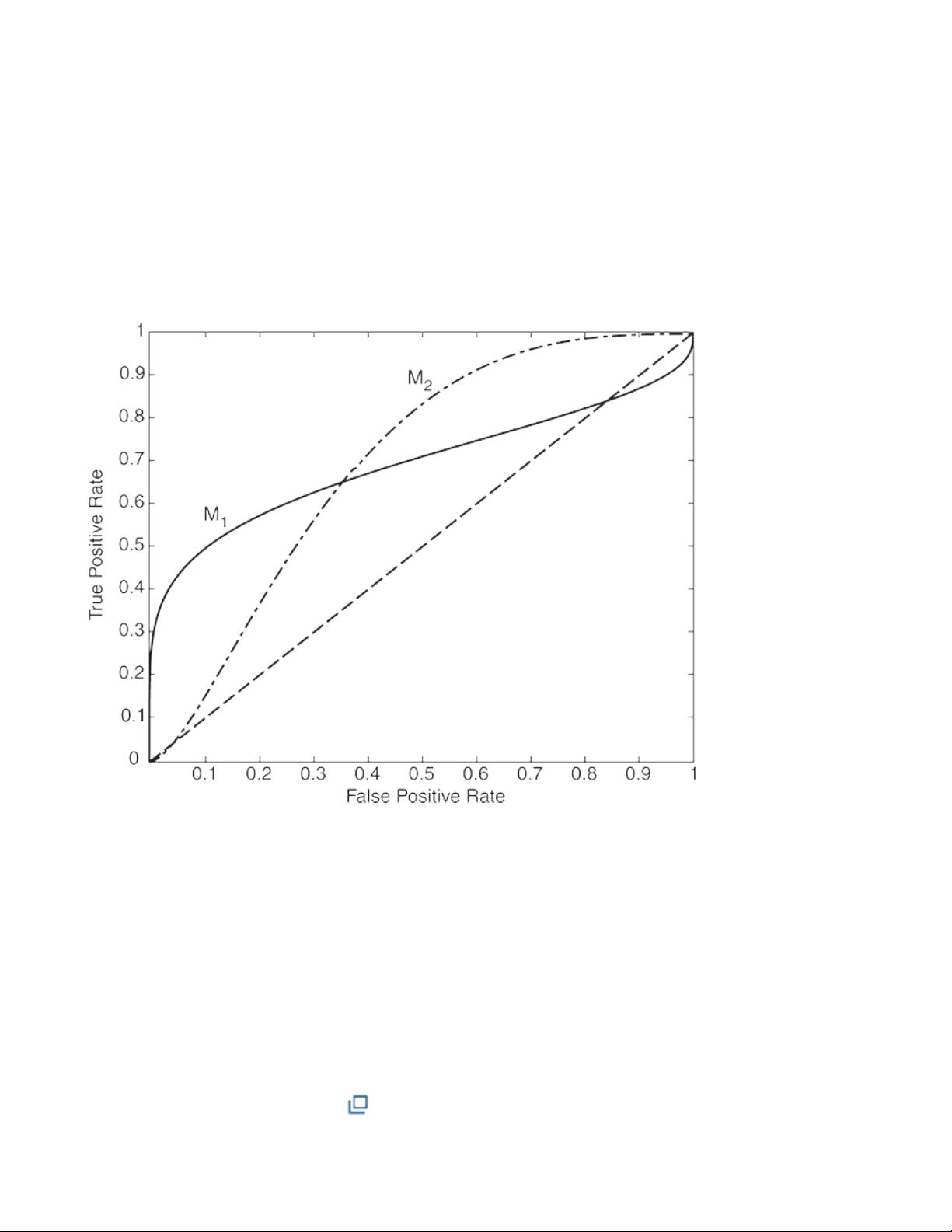
value.Assessingtheperformanceofaclassifieroverarangeofscore
thresholdsiscalledaggregateevaluationofperformance.Inthisstyleof
analysis,theemphasisisnotonevaluatingtheperformanceofasingle
classifiercorrespondingtotheoptimalscorethreshold,buttoassessthe
generalqualityofrankingproducedbytheclassificationscoresonthetestset.
Ingeneral,thishelpsinobtainingrobustestimatesofclassification
performancethatarenotsensitivetospecificchoicesofscorethresholds.
F1
s*
s*
α
s*
s*
s*
s*
α

剩余499页未读,继续阅读

woodballhead
- 粉丝: 22
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- 中国微型数字传声器:技术革新与市场前景
- 智能安防:基于Hi3515的嵌入式云台控制系统设计
- 手机电量低时辐射真增千倍?解析手机使用谣言
- 56F803型DSP驱动的高精度大功率超声波电源控制策略研究
- ARM与GPRS结合的远程监测系统设计
- GPS与RFID技术结合的智能巡检系统设计
- CPLD驱动的低功耗爆炸场温度测试系统设计
- 基于FPGA的智能驱动控制系统:可扩展设计与工业网络协议
- 基于ATmega128和CH374的嵌入式USB接口设计
- 基于AT89C52的温度补偿超声波测距仪:高精度设计与应用
- MSP430F448单片机在交流数字电压表中的应用
- 提升变频器应用效率的12项实用技巧
- STM32F103在数字电镀电源并联均流系统中的应用
- PSpice仿真下的升压开关电源设计:拓扑分析与CCM稳定性提升
- 轻巧高效:MSP430主导的低成本无线传感器网络节点设计
- FPGA在EDA/PLD中实现LVDS接口的应用解析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


