回归分析:多项式拟合与误差函数探索
142 浏览量
更新于2024-08-04
收藏 425KB PDF 举报
"回归概述-多项式拟合.pdf" 是一份关于回归分析中多项式拟合的文档,主要内容涉及如何利用多项式模型进行数据拟合和预测,以及如何处理过拟合和欠拟合的问题。
回归是一种统计学方法,旨在通过已知的输入变量(自变量)预测输出变量(因变量)。在多项式拟合中,我们尝试找到一个最佳的多项式函数,该函数能够尽可能地逼近给定训练数据集中的点。这通常用于发现数据背后的结构,并用于对未来的新数据进行预测。
数据生成过程假设有一个输入变量 \( x \),输出变量 \( y \) 受到一个潜在函数 \( f(x) \) 和随机噪声的影响。训练集包含 \( N \) 对观测值 \( (x_n, t_n) \),其中 \( t_n = f(x_n) + \epsilon_n \),\( \epsilon_n \) 是服从特定分布(例如正态分布)的噪声项。
多项式拟合是回归的一种形式,它使用多项式函数 \( y(x, w) = w_0 + w_1x + w_2x^2 + \dots + w_Mx^M \) 来近似数据点。这里的 \( w_j \) 是待确定的系数,\( M \) 是多项式的阶数。为了找到最佳的系数向量 \( w \),我们可以最小化误差函数 \( E(w) \),它是预测值 \( y(x, w) \) 与实际观测值 \( t \) 差的平方和。
误差函数 \( E(w) \) 表示为:
\[ E(w) = \frac{1}{2} \sum_{n=1}^{N} (y(x_n, w) - t_n)^2 \]
当误差函数为零时,意味着多项式完美地拟合了所有训练数据点。然而,选择合适的 \( M \) 是关键,因为过低的阶数可能导致欠拟合,过高则可能导致过拟合。欠拟合是指模型过于简单,无法捕捉数据的复杂性,而过拟合则是模型过于复杂,对训练数据过度适应,导致在新数据上表现不佳。
在实践中,我们可以用均方根误差(RMS)来评估不同阶数 \( M \) 的拟合效果。RMS 是误差平方和的平均值的平方根,它提供了对模型预测精度的直观度量。例如,如果 \( M=0 \)(常数项)或 \( M=1 \)(一次多项式)时,RMS 可能较高,表明模型未能有效捕捉数据趋势。相反,当 \( M \) 过大时,RMS 在训练数据上可能很低,但在未见过的数据上会显著增加,表明过拟合现象。
因此,选择合适的 \( M \) 是一个平衡过程,通常需要在模型复杂性和泛化能力之间找到最佳折衷。这可以通过交叉验证、正则化技术或模型选择准则(如 Akaike 信息准则或 Bayesian 信息准则)来实现。在实际应用中,我们不仅追求拟合训练数据,更要确保模型在未知数据上的表现。
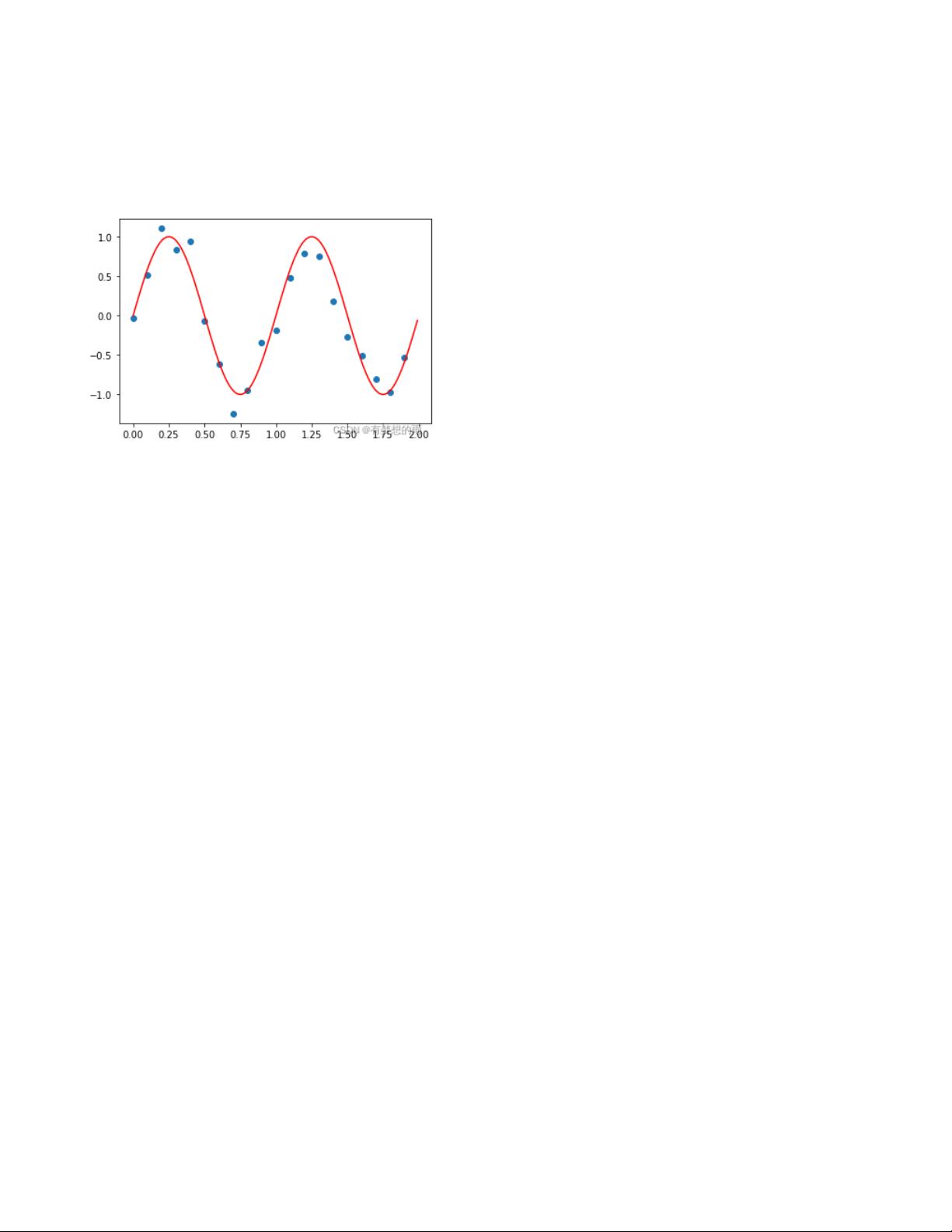
数据生成数据生成
假设当观察到一个实值的输入变量 ,而想利用这些观测数据来预测实值变量 。数据由以一个带有噪声的由函数
生成。现假定给出一个训练集(包括 个 的观测值,记为 ,相应的观测值为
。)观测值 由 加上一个由其他分布产生的一个噪声得到,若噪声由正态分布得到,则其分
布如下所示:
以这种方式生成数据,可以捕捉到许多真实数据集的一些特性,他们具有某种基底规律性,我们所希望做的就是去学习
这些规律,不过单个数据又经常被噪声所扰动,这种噪声可能来自于本质上的随机过程,比如放射性,但更典型的是由
于存在着变异源,而这些变异源本身是不可观测的。
多项式拟合多项式拟合
而回归的任务是利用这些训练集中的数据对新输入变量 预测输出 。首先考虑使用一种简单的曲线拟合方式——多项
式拟合:
误差函数误差函数
多项式的系数以向量形式表达 : ,需要确定该拟合多项式的系数,可以通过最小化拟合函最小化拟合函
数数 和训练集中数据点之间的误差和训练集中数据点之间的误差 得到,则定义误差函数误差函数:
x t
sin(2πx) N x xx = (x , ⋯ , x )
1 N
T
tt =
(t , ⋯ , t )
1 N
T
t
n
sin(2πx)
x^ t
^
y(x, ww) = w +
0
w ⋅
1
x + w ⋅
2
x +
2
⋯ + w ⋅
M
x =
M
w ⋅
j=0
∑
M
j
x
j
ww = (w , w , ⋯ , w )
0 1 M
T
y(x, ww)
E(ww) = [y(x , ww) −
2
1
n=1
∑
N
n
t ]
n
2
下载后可阅读完整内容,剩余5页未读,立即下载
2019-08-21 上传
2018-03-01 上传
2024-03-18 上传
2024-03-18 上传
2010-12-16 上传
2024-03-19 上传
2021-08-28 上传
2022-11-26 上传
2019-07-04 上传

快乐无限出发
- 粉丝: 1186
- 资源: 7365
 我的内容管理
展开
我的内容管理
展开







最新资源
- Material Design 示例:展示Android材料设计的应用
- 农产品供销服务系统设计与实现
- Java实现两个数字相加的基本代码示例
- Delphi代码生成器:模板引擎与数据库实体类
- 三菱PLC控制四台电机启动程序解析
- SSM+Vue智能停车场管理系统的实现与源码分析
- Java帮助系统代码实现与解析
- 开发台:自由职业者专用的MEAN堆栈客户端管理工具
- SSM+Vue房屋租赁系统开发实战(含源码与教程)
- Java实现最大公约数与最小公倍数算法
- 构建模块化AngularJS应用的四边形工具
- SSM+Vue抗疫医疗销售平台源码教程
- 掌握Spring Expression Language及其应用
- 20页可爱卡通手绘儿童旅游相册PPT模板
- JavaWebWidget框架:简化Web应用开发
- 深入探讨Spring Boot框架与其他组件的集成应用
