Redis Cluster架构与搭建指南:无中心分布式与哨兵模式对比
66 浏览量
更新于2024-08-03
收藏 2.81MB PDF 举报
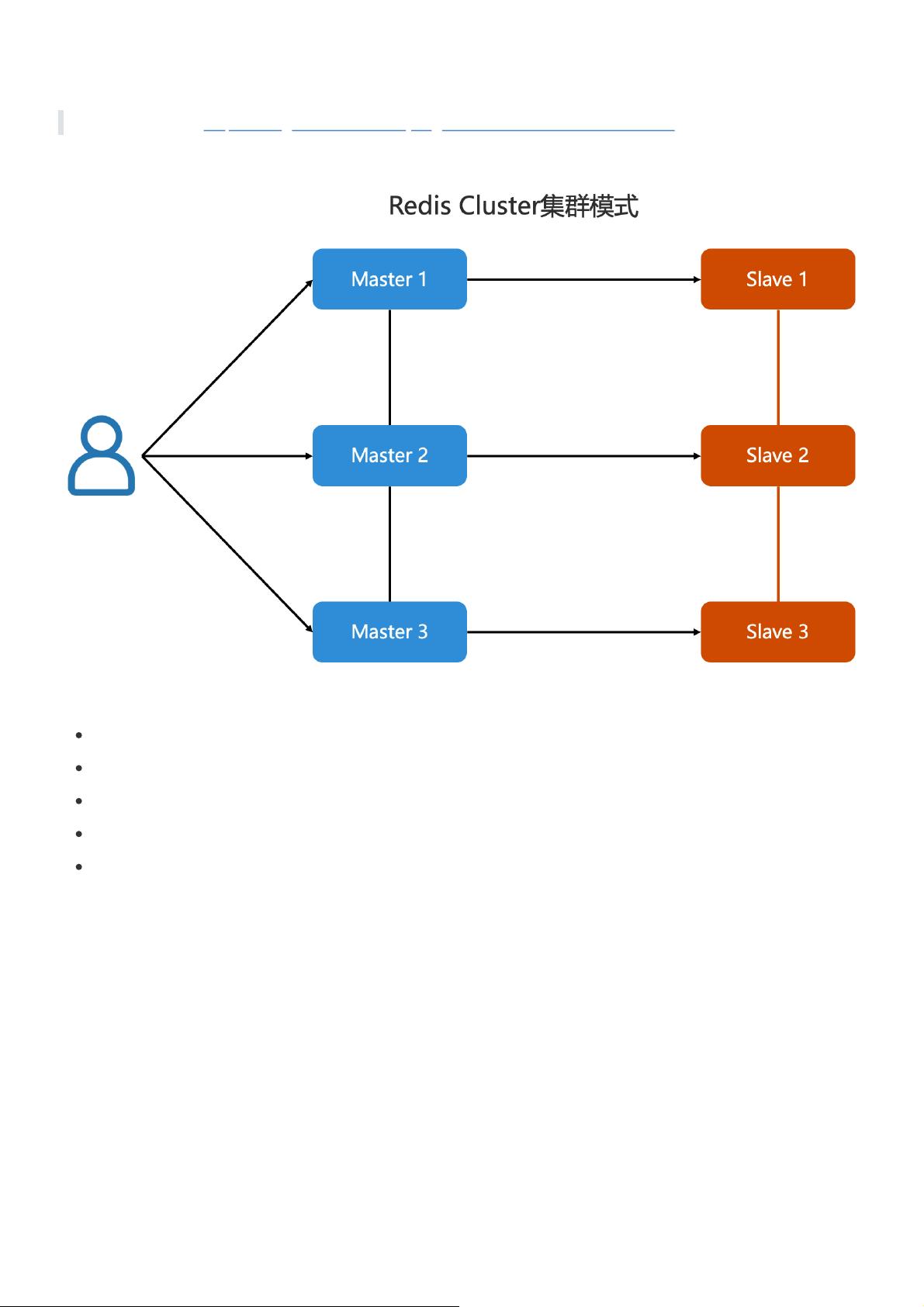
Redis Cluster集群模式是一种分布式内存数据库解决方案,旨在提高Redis的可扩展性和高可用性。它是Redis 3.0版本引入的新特性,采用了无中心架构,每个节点不仅保存数据,还维护整个集群的状态,通过全互连的方式实现节点间的通信,采用Gossip协议来同步节点元数据。
在Redis Cluster中,为了保证数据的一致性和可用性,官方推荐至少6个节点构成集群,其中3个为主节点(master),3个为从节点(slave),这种设计有助于确保即使有节点故障,仍有足够的备份。每个节点只负责部分数据,通过数据散列算法(如哈希函数)将键映射到特定的槽(slot),从而实现数据分布存储。每个槽包含一个或多个主节点的数据子集,这样可以在多台服务器上并行处理大量数据,提高性能。
数据分散存储的关键在于16384这个数字,这是因为节点之间的通信在发送心跳包时,会使用字符进行bitmap压缩,压缩后的大小为2KB,而16384正好满足这个限制,即16KB。虽然理论上的节点数量可以超过10000个,但实际操作中一般不会超过这个值,因此16384的大小足够应对大部分场景。
集群构建过程涉及配置文件`redis-cluster.conf`,其中包括开启集群功能、设置节点连接超时时间、指定节点通信端口等参数。通过执行`./src/redis-server redis-cluster.conf`启动服务器,并在任意节点上使用`redis-cli --clustercreate`命令创建集群。例如,命令中提到的三个节点的地址及端口用于初始化集群成员。
在创建集群后,节点之间的槽分配信息会持续在集群内同步,确保所有节点对槽的分布有全局认识。这样,当客户端请求数据时,它会根据键的哈希值找到相应的槽,进而找到负责该槽的节点,实现高效的数据访问。
总结来说,Redis Cluster提供了高可用性和可扩展性的解决方案,通过数据散列和节点间的协同工作,使得大型分布式环境下的数据管理和访问变得更为高效。然而,它的实施需要注意节点数量的选择、配置文件的调整以及正确的集群创建流程,以确保集群的稳定运行。与Redis Sentinel模式相比,Cluster更侧重于大规模数据处理能力,而Sentinel则关注于单点实例的高可用监控和故障切换。
下载后可阅读完整内容,剩余4页未读,立即下载
2022-06-01 上传
2020-11-13 上传
2016-03-09 上传
点击了解资源详情
2017-08-04 上传
2018-04-10 上传
2018-06-28 上传
151 浏览量
2023-08-01 上传

帅喵
- 粉丝: 102
- 资源: 25
 我的内容管理
展开
我的内容管理
展开







最新资源
- 数字单片机数字单片机
- D语言编程参考手册1.0
- JAVA程序员面试题解惑
- cognos8.12学习资料
- Intel双核与超线程的区别与联系
- 如何编写LINUX 驱动
- Apache与多个Tomcat服务器集成时的负载平衡.txt
- GCC中文手册,详细介绍GCC
- GCC中文手册,详细介绍GCC
- Cross-words Reference Template for DTW-based Speech Recognition Systems
- 一份不太简短的LaTex介绍
- Linux 常用指令大全
- 计算机毕业论文(试题库管理系统)
- 综合电子仿真与设计项目
- XX公司网络设计方案doc
- Oracle Biee Catalog合并
