编译原理作业解析:正则表达式与DFA
需积分: 32 75 浏览量
更新于2024-09-13
收藏 1023KB PDF 举报
"该资源包含了编译原理课程的两次作业答案,主要涉及正则表达式、有限自动机(NFA和DFA)以及语言的补运算。内容包括对正则表达式的自然语言描述,以及如何构造DFA来识别特定语言。作业中还提到了子串与子序列的区别,并探讨了在DFA中‘死状态’的概念及其处理方法。"
在编译原理的学习中,正则表达式是一种用于描述字符串集合的强大工具。作业中提到的第一个问题涉及将正则表达式转化为自然语言描述,例如,`b*(ab*ab*)*` 描述的是所有含有偶数个'a'的'a'和'b'的组合,而`c*a(a|c)*b(a|b|c)*|c*b(b|c)*a(a|b|c)*`则表示所有至少包含一个'a'和一个'b'的'a', 'b', 'c'字符串。
作业中提到了子串与子序列的概念,子串是字符串的一个连续部分,而子序列可以不连续,只要原字符串中的字符顺序保持不变即可。例如,对于字符串"abcde","ace"是其子序列但不是子串。
在第二个作业中,重点在于通过正则表达式描述不包含特定子串或子序列的语言。如`b*a*`定义了所有不包含连续的"ab"的字符串,`b*(ab?)*`则排除了包含"abb"的字符串,而`b*a*b?a*`则确保不存在子序列"abb"。
NFA(非确定性有限状态自动机)和DFA(确定性有限状态自动机)是理解正则表达式语言的关键。NFA可以接受一个字符串,即使存在多个路径导致接受状态,而DFA只能有一条路径到接受状态。作业中给出了如何将NFA转换为DFA的方法,同时讨论了在构建DFA时如何处理死状态,即那些无论输入什么符号都无法到达接受状态的状态。
此外,作业还涉及了正则语言的补运算,即找出不被正则表达式描述的所有字符串集合。通过改变接受状态和非接受状态,可以从识别语言L的DFA构造出识别其补集L'的DFA。
这些知识点是编译原理基础的核心,理解和掌握它们对于深入学习编译器设计、形式语言理论以及相关领域至关重要。通过解决此类作业,学生可以提升对正则表达式、有限自动机及其转换的理解,以及如何用它们来描述和识别不同的字符串模式。
计算机科学系 2010 春季学期
3
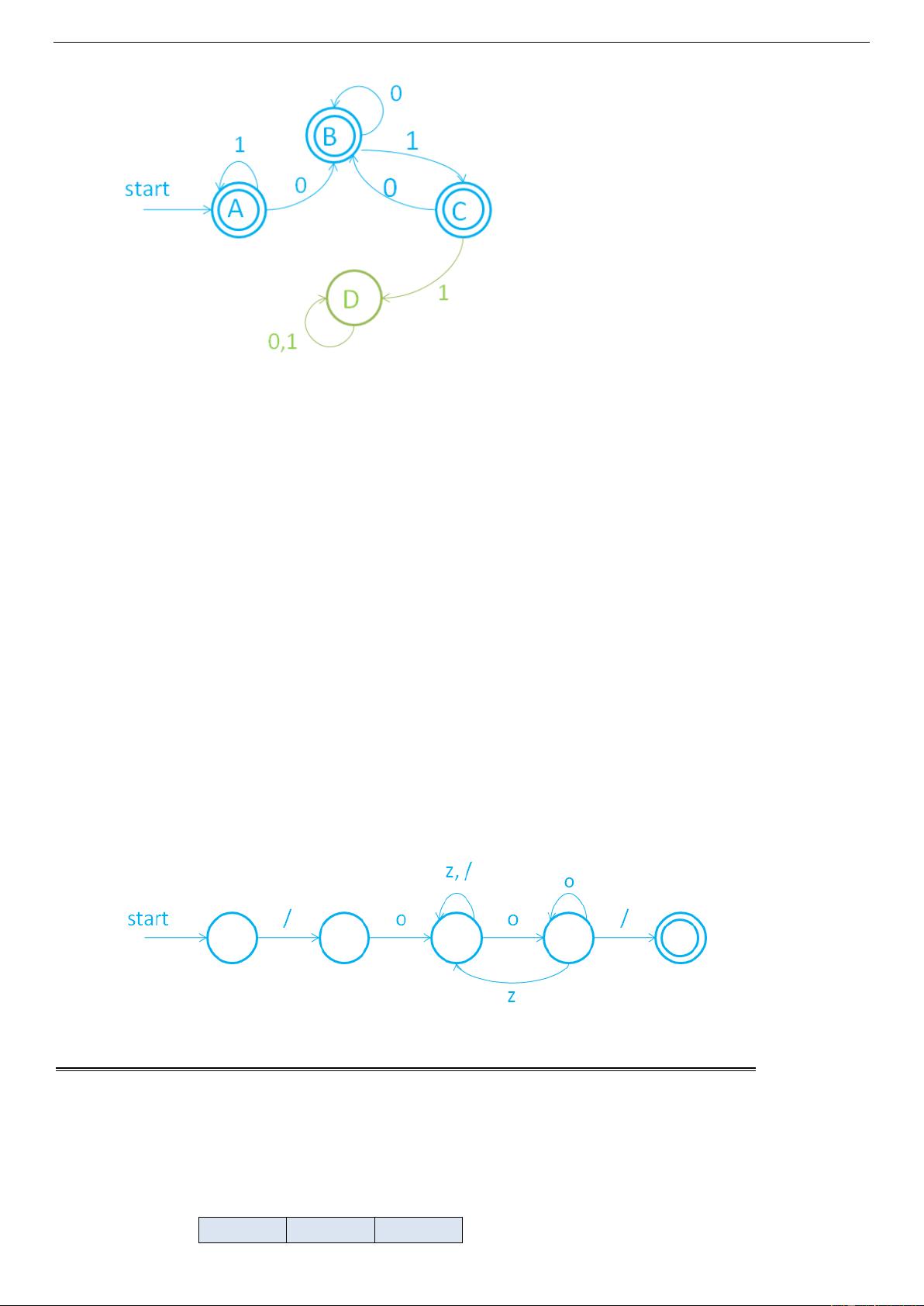
规律:构造语言 L 的补语言 L’的 DFA,可以先构造出接受 L 的 DFA,再把这一 DFA 的接受状态改为非接受
状态,非接受状态改为接受状态,就可以得到识别 L’的 DFA.
说明:在上述两题中的 D 状态,无论输入什么符号,都不可能再到达接受状态,这样的状态称为“死状态”.
在画 DFA 时,有时为了简明起见,“死状态”及其相应的弧(上图中的绿色部分)也可不画出.
2. 再证明:对任一正则表达式 R,一定存在另一正则表达式 R',使得 L(R')是 L(R)的补集.
证明:根据正则表达式与 DFA 的等价性,一定存在识别语言 L(R)的 DFA. 设这一 DFA 为 M,则将 M 的所有
接受状态改为非接受状态,所有非接受状态改为接受状态,得到新的 DFA M’.易知 M’识别语言 L(R)的补
集. 再由正则表达式与 DFA 的等价性知必存在正则表达式 R’,使得 L(R’)是 L(R)的补集.
三、 设有一门小小语言仅含 z 、o 、/ (斜杠)3 个符号,该语言中的一个注释由/o 开始、以 o/结束,并且注释
禁止嵌套.
1. 请给出单个正则表达式,它仅与一个完整的注释匹配,除此之外不匹配任何其他串. 书写正则表达式时,
要求仅使用最基本的正则表达式算子(,|,*,+,?).
参考答案一:/o(o*z|/)*o+/
思路:基本思路是除了最后一个 o/,在注释中不能出现 o 后面紧跟着/的情况;还有需要考虑的是最后一
个 o/之前也可以出现若干个 o.
参考答案二(梁晓聪、梁劲、梁伟斌等人提供):/o/*(z/*|o)*o/
2. 给出识别上述正则表达式所定义语言的确定有限自动机(DFA). 你可根据问题直接构造 DFA,不必运用机
械的算法从上一小题的正则表达式转换得到 DFA.
~\(≧▽≦)/~~\(≧▽≦)/~~\(≧▽≦)/~~\(≧▽≦)/~~\(≧▽≦)/~~\(≧▽≦)/~~\(≧▽≦)/~~\(≧▽≦)/~
《 编译原理》 第 三 次 作 业 参 考 答 案
一、 考虑以下 DFA 的状态迁移表,其中 0,1 为输入符号,A~H 代表状态:
0
1
剩余10页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2011-02-14 上传
2022-08-08 上传
2014-12-22 上传
2016-01-11 上传
2020-12-11 上传
2021-10-12 上传

Sherljohn
- 粉丝: 0
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- AJAX开发简略.pdf
- PowerBuilder8.0中文参考手册.pdf
- struts2.0+hibernate3.1+spring2.0的使用.doc
- VB中与串口通讯需要用到的控件介绍
- cpu卡基础知识与入门方法
- c++ TR1 文档
- 虚拟键盘的驱动程序 制作虚拟键盘的过程和
- MRPII-最经典的教材
- GRAILS中文开发PDF文档
- c++ 小游戏 程序
- 深入浅出Struts2.pdf
- 网络工程师英词典 网工英语词汇表.pdf
- Ubuntu实用学习教程
- Linux.C++.Programming.HOWTO
- QTP初级使用手册QTP8_Tutorial_oldsidney_cn
- 注册表概述精华及普遍误区
