认知深化模型驱动的感知进化网络:应对新感官输入
需积分: 5 96 浏览量
更新于2024-08-26
收藏 2.02MB PDF 举报
"这篇研究论文探讨了一种名为感知进化网络(Perception Evolution Network,PEN)的模型,该模型基于认知加深理论,旨在适应新感觉受体的出现。PEN是一种生物启发式的无监督学习和在线增量学习神经网络模型,能够以增量方式自动从学习数据中学习合适的原型,并且不需要预先定义的原型数量或相似性阈值。此外,PEN比现有的无监督神经网络模型更先进,允许网络的感知域中出现新的感知维度。当引入新的感知维度时,PEN能够将新的多维感官输入与已学习的原型整合,即将原型映射到一个高维空间,这个空间包含原始维度和新引入的感官输入维度。实验使用人工数据和真实世界数据验证了该模型的性能和有效性。"
这篇论文主要关注的是在神经网络模型中如何处理和适应新的感官输入,这是生物系统中一个重要的适应性特征。感知进化网络(PEN)是作者提出的一种创新模型,它模拟了生物系统如何随环境变化而进化其感知能力。PEN的核心特点是它的无监督学习能力和在线增量学习能力,这使得它能够在数据流不断变化的情况下自我调整和优化。
无监督学习是机器学习的一个分支,通常用于发现数据中的隐藏结构或模式,而不依赖于预先标记的类别信息。PEN在此基础上进一步发展,不仅能够自动学习数据集中的代表原型,而且无需预设原型数量,这意味着模型可以根据数据本身的特性自我调整。
在线增量学习是指模型能够处理新数据流,并实时更新其参数和结构的过程。在PEN中,这种特性使得模型能够应对新感觉受体的出现,即新的感官输入维度。当网络遇到新的感知维度时,它会将这些新信息集成到现有原型中,通过映射到更高维度的空间来适应变化,从而保持其对环境的适应性。
实验部分,PEN在人工数据和现实世界数据上进行了测试,以验证其在处理新感知维度和持续学习的能力。这些实验结果对于理解PEN模型的性能和实际应用潜力提供了关键证据。
这篇论文提出的PEN模型为神经网络在适应环境变化,特别是处理新感官输入方面的研究提供了一个新的视角,对于未来在机器人、人工智能和生物启发式计算等领域有潜在的应用价值。
XING et al.: PEN BASED ON COGNITION DEEPENING MODEL 609
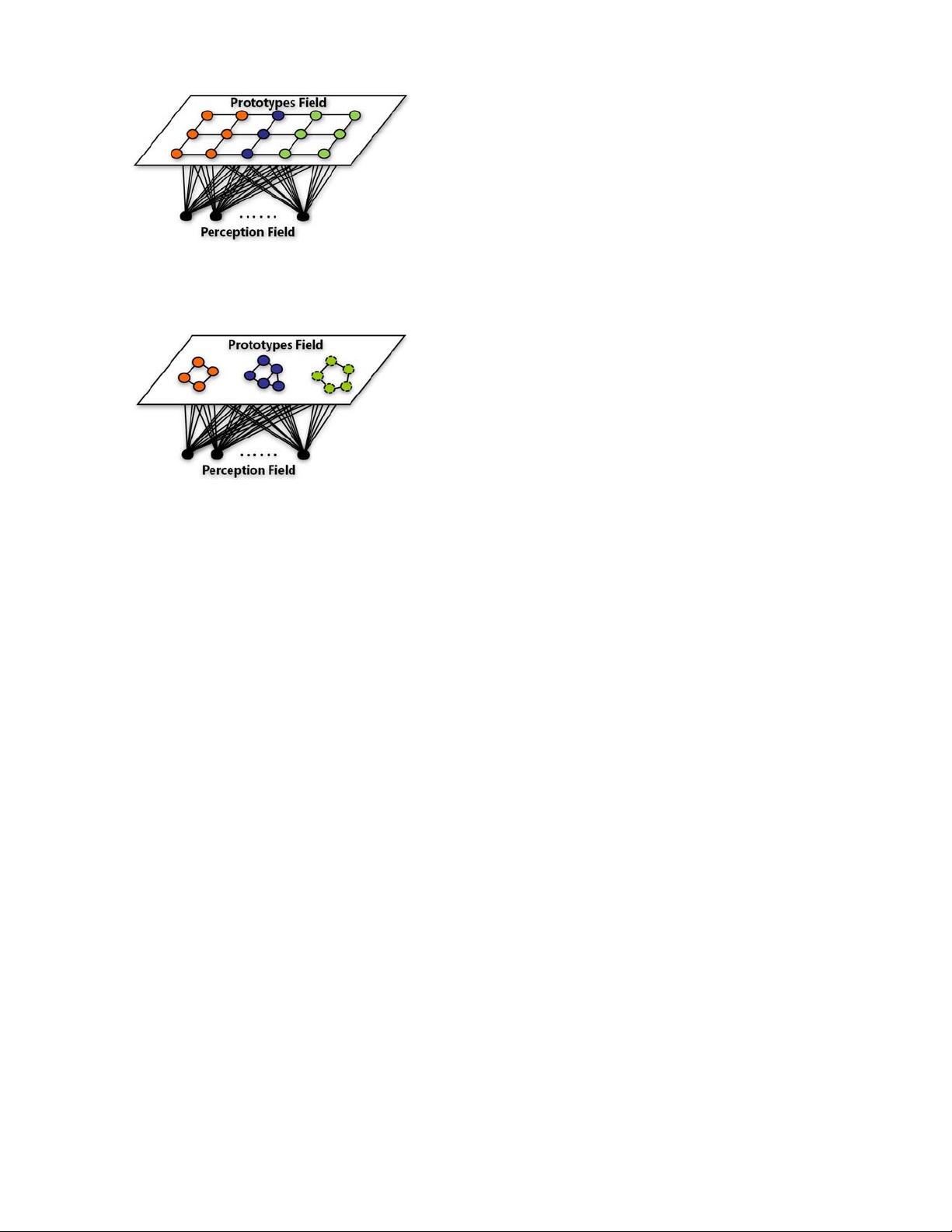
Fig. 4. Abstract structure of the perception-prototype field limited neural
networks. The number of prototypes in the prototype field is fixed. Lines in
the prototype field represent the topology relationship between prototypes.
In some algorithms, topology relationship is not predefined but learned by
the algorithm itself such as the TRN.
Fig. 5. Abstract structure of the prototype field open-ended neural networks.
The prototypes with dashed edge in the prototype field are added or pruned
during learning. Some algorithms do not define the topology relationship
between the prototypes such as the ART network.
To solve this problem, many growing neural networks
or incremental networks are designed. Growing
SOM (GSOM) [19], growing cell structure [20], and
growing NG (GNG) [21] insert new prototype(s) for every
λ samples learned, where λ is a constant parameter. Life-long
learning cell structure [22] introduces an insertion criterion to
decide whether to insert a new prototype for every λ patterns
learned; meanwhile, it also deletes prototypes to avoid
overfitting. However, in these methods, during each λ period,
the input sample is forced to merge with a prototype no
matter how big the gap between them. Considering the
physical meaning, it is unreasonable to merge two patterns
with significant difference.
There is another problem, which is well known as the
stability-plasticity dilemma [9], i.e., making the system
quickly learn about new knowledge (e.g., new objects) without
just as quickly being forced to forget previously learned, but
still useful, memories. The adaptive resonance theory (ART)
network [9], fuzzy ART [23], evolving SOMs [24], and
TopoART [25] (ART family) will create a new prototype
when no match occurs between the current input sample
and the current category set. The degree of matching is
controlled by a parameter known as the vigilance parameter.
This strategy makes the network add new prototype, when
the input sample is not similar to the existing prototypes that
the network has learned. However, the vigilance parameter
should be predefined. It is a difficult job when we have little
prior knowledge about the learning task, especially for the
unsupervised learning task. Evolving vector quantization [26]
introduces an online split-and-merge strategy to overcome the
poor setting of the vigilance parameter.
Self-organizing incremental neural network (SOINN) [27],
enhanced-SOINN [28], adjusted-SOINN [29], and
load-balancing-SOINN [30] decide whether to create a
new prototype for the input sample according to the
prototype-distribution around the local region of the input
sample. These methods overcome the disadvantages of
GSOM, GNG, and ART family algorithm. Incremental
learning vector quantization [31], [32] introduces the idea of
the adjusted-SOINN to the learning vector quantization and
achieves very good results.
We summarize these unsupervised incremental learning
methods as prototype field open-ended models, as shown
in Fig. 5. This type of network focuses on the prototype field;
it makes the prototype field open-ended for new categories
by adding new prototypes. In recent years, these methods are
applied to various domains, including reasoning system [33],
pattern recognition [34], and computer vision [35].
However, the perception-prototype field limited and
prototype field open-ended models are not able to expand
the perception field, which we think is a very important
ability for unsupervised learning as mentioned in Section I.
For example, if we install new sensors to a robot as a new
information channel, and we want the robot to use the new
sensors effectively. The perception-prototype field limited and
prototype field open-ended models cannot deal with such
a task, and the proposed PEN is designed to solve such
problems.
III. P
ERCEPTION EVOLUTION NETWORK
A. Problem Formulation
Assume that the original neural network N has n neurons
in the perception field, which receive n-dimensional external
data x = (x
1
, x
2
,...,x
n
) ∈ R
n
. After a period of learn-
ing, some prototypes are created in the prototype field of
PEN. Then, m new sensory neurons emerge in the percep-
tion field of PEN. In addition, the received data becomes
x = (x
1
, x
2
,...,x
n
, x
n+1
,...,x
n+m
) ∈ R
n+m
. The learned
prototypes will be mapped to a high-dimensional space, which
contains the dimension of these m new sensory neurons.
If the new sense brings some new distinguishable categories,
PEN will create prototypes for such new categories.
The entire workflow of the PEN is as follows. The prototype
field of PEN is empty in the beginning, and learning samples
are fed into the network sequentially, i.e., in an online way.
The PEN will create two prototypes using the first two input
samples. For the latter input sample, PEN first conducts
prototype competition, then prototype learning and prototype
self-adaptive associating are conducted according to the result
of the competition step; meanwhile, the similarity threshold of
the activated prototypes will be updated. When all the steps
are done, PEN will process the next input sample. Prototype
pruning is conducted after every λ samples learned.
When some new sensory neurons are introduced,
PEN will find some low-dimensional prototype to
map to high-dimensional space for each input sample.
Prototype self-adaptive associating and similarity threshold
updating are conducted similarly as the procedure before
剩余13页未读,继续阅读
2021-09-25 上传
2021-09-26 上传
2021-08-26 上传
2021-03-10 上传
2009-03-16 上传
2023-10-15 上传
2021-12-04 上传
2014-05-29 上传
2021-02-25 上传

weixin_38562085
- 粉丝: 6
- 资源: 964
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
