阿里云Lindorm解决新能源汽车海量监控数据存储难题
需积分: 0 84 浏览量
更新于2024-06-30
收藏 17.42MB PDF 举报
“许力-破解BEV新能源汽车海量监控数据采集存储难题101910031”
本文主要探讨了在智能互联时代,尤其是新能源汽车(BEV)领域,如何有效解决海量监控数据的采集与存储问题。阿里云数据库高级产品专家许力博士提出了解决方案,即采用云原生多模超融合数据库Lindorm。
在智能互联时代,随着工业物联网(IoT)、车联网等领域的快速发展,数据量呈现爆炸式增长。预计到2025年,工业物联网市场规模将达到3.7万亿美元。车联网数据业务具有显著价值,但同时也带来了数据存储的新挑战:
1. 数据量巨大:由于车辆的实时监控,产生了大量数据。
2. 价值密度较低:大部分数据可能是背景信息,真正有价值的数据占比较小。
3. 数据多样化:包括位置信息、车辆状态、驾驶行为等多种类型。
4. 实时性较高:需要快速响应和处理数据,提供实时服务。
5. 大多来自采样:数据采集频繁,需要高效处理。
6. 数据源分散:数据可能来自多个设备或系统,需要整合。
针对这些挑战,许力博士推荐使用阿里云Lindorm,这是一个云原生多模超融合数据库,具备以下特点:
- 运维敏捷:简化数据库管理和维护,提高效率。
- 成本低廉:根据需求弹性付费,降低存储成本。
- 部署简单:易于安装和配置,适应快速变化的需求。
- 极速性能:优化了数据处理速度,满足实时性需求。
- 兼容多种开源标准接口:如HBase、Solr、SQL、OpenTSDB等,便于集成现有系统。
Lindorm适用于物联网、车联网、APM运维、NPM运维等多个行业,尤其在监控数据应用场景中表现出色,例如城市大脑、智能楼宇、安全安防和工控生产等领域。其产品特性包括:
- 时间、空间、事件融合:支持对时间序列、空间和事件数据的综合处理。
- 高通量采集:能够高效地接收和处理大量指标数据。
- 数据清洗和关联:对原始数据进行预处理,提升数据质量。
- 事件管理:支持事件触发和响应机制。
- 增量数据订阅/发布:实现数据的实时同步。
- 分析和异常检测:内置分析功能,可进行异常检测。
- 生态接口对接:与TSDB、HBse等开源系统无缝对接,同时兼容KAFKA、Flink等流处理工具。
- Serverless架构:提供高可用性和SLA保障。
- 存储计算一体化:结合云存储和计算能力,灵活选择存储介质如本地SSD或云盘。
Lindorm作为云原生数据库解决方案,旨在应对大数据时代的挑战,通过技术创新和生态融合,为BEV新能源汽车的海量监控数据提供高效、经济、灵活的存储和处理方式。
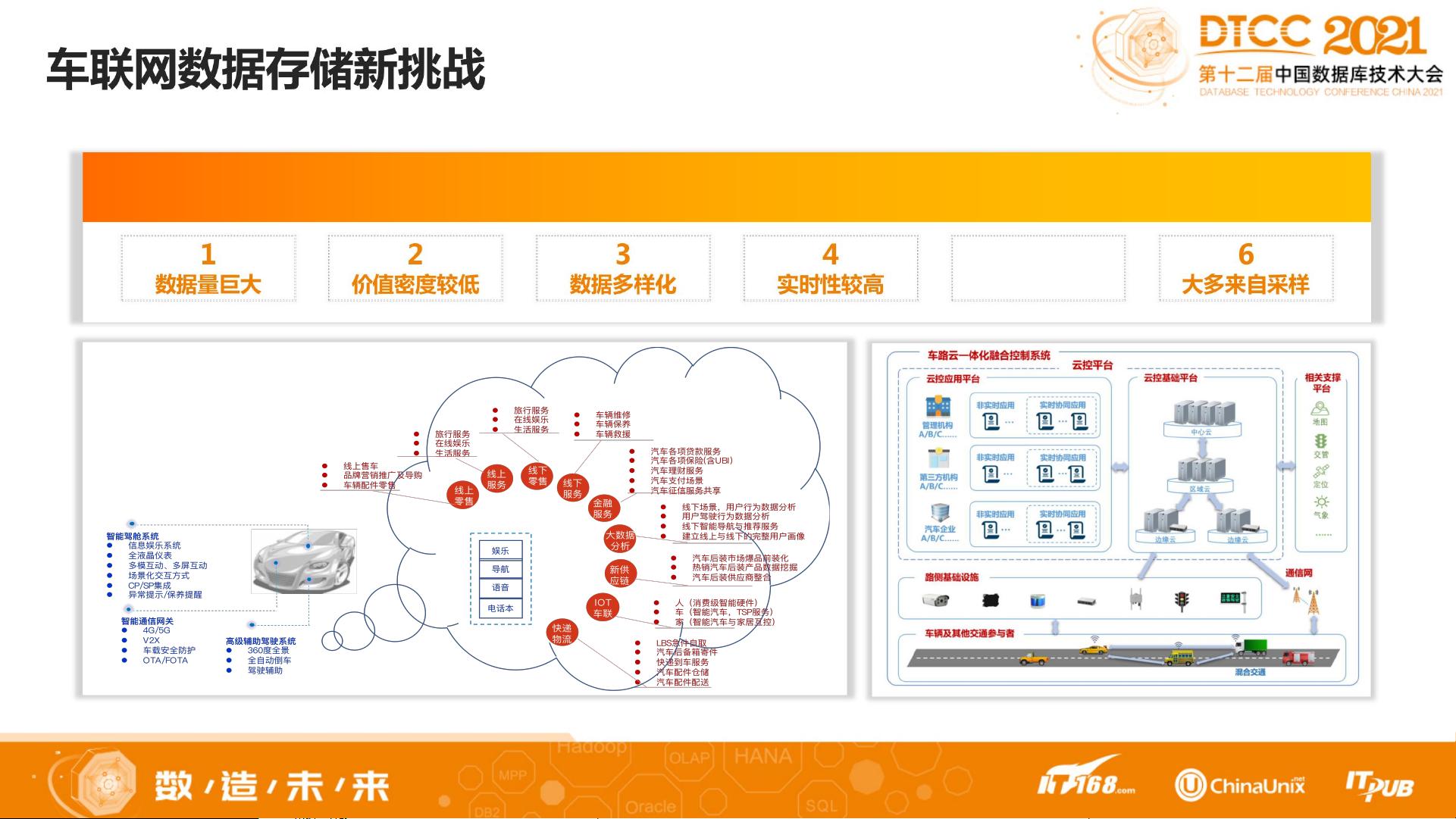
车联网数据存储新挑战
1
数据量巨大
2
价值密度较低
3
数据多样化
4
实时性较高
6
大多来自采样
5
数据源很分散
数据存储特点
剩余22页未读,继续阅读
2012-03-31 上传
2012-03-31 上传
2019-10-24 上传
2019-10-10 上传
2010-02-10 上传
2022-11-23 上传
2024-11-04 上传

阿玫小酱当当囧
- 粉丝: 18
- 资源: 324
 我的内容管理
展开
我的内容管理
展开







最新资源
- Aspose资源包:转PDF无水印学习工具
- Go语言控制台输入输出操作教程
- 红外遥控报警器原理及应用详解下载
- 控制卷筒纸侧面位置的先进装置技术解析
- 易语言加解密例程源码详解与实践
- SpringMVC客户管理系统:Hibernate与Bootstrap集成实践
- 深入理解JavaScript Set与WeakSet的使用
- 深入解析接收存储及发送装置的广播技术方法
- zyString模块1.0源码公开-易语言编程利器
- Android记分板UI设计:SimpleScoreboard的简洁与高效
- 量子网格列设置存储组件:开源解决方案
- 全面技术源码合集:CcVita Php Check v1.1
- 中军创易语言抢购软件:付款功能解析
- Python手动实现图像滤波教程
- MATLAB源代码实现基于DFT的量子传输分析
- 开源程序Hukoch.exe:简化食谱管理与导入功能
