京东Squirrel团队Redis Rehash问题及解决方案
需积分: 50 118 浏览量
更新于2024-07-16
收藏 1.24MB DOCX 举报
本文主要介绍了京东内部基于Redis Cluster构建的分布式缓存系统Squirrel,在长期的运维和优化过程中,团队遇到了Redis Rehash机制的问题,并针对这些问题进行了深入研究和解决。文章分享了在满容状态下Rehash导致的大规模Key驱逐问题,以及RootCause的定位方法。文中还详细探讨了Redis的Rehash内部实现,并提到了Redis高负载下的中断优化问题。
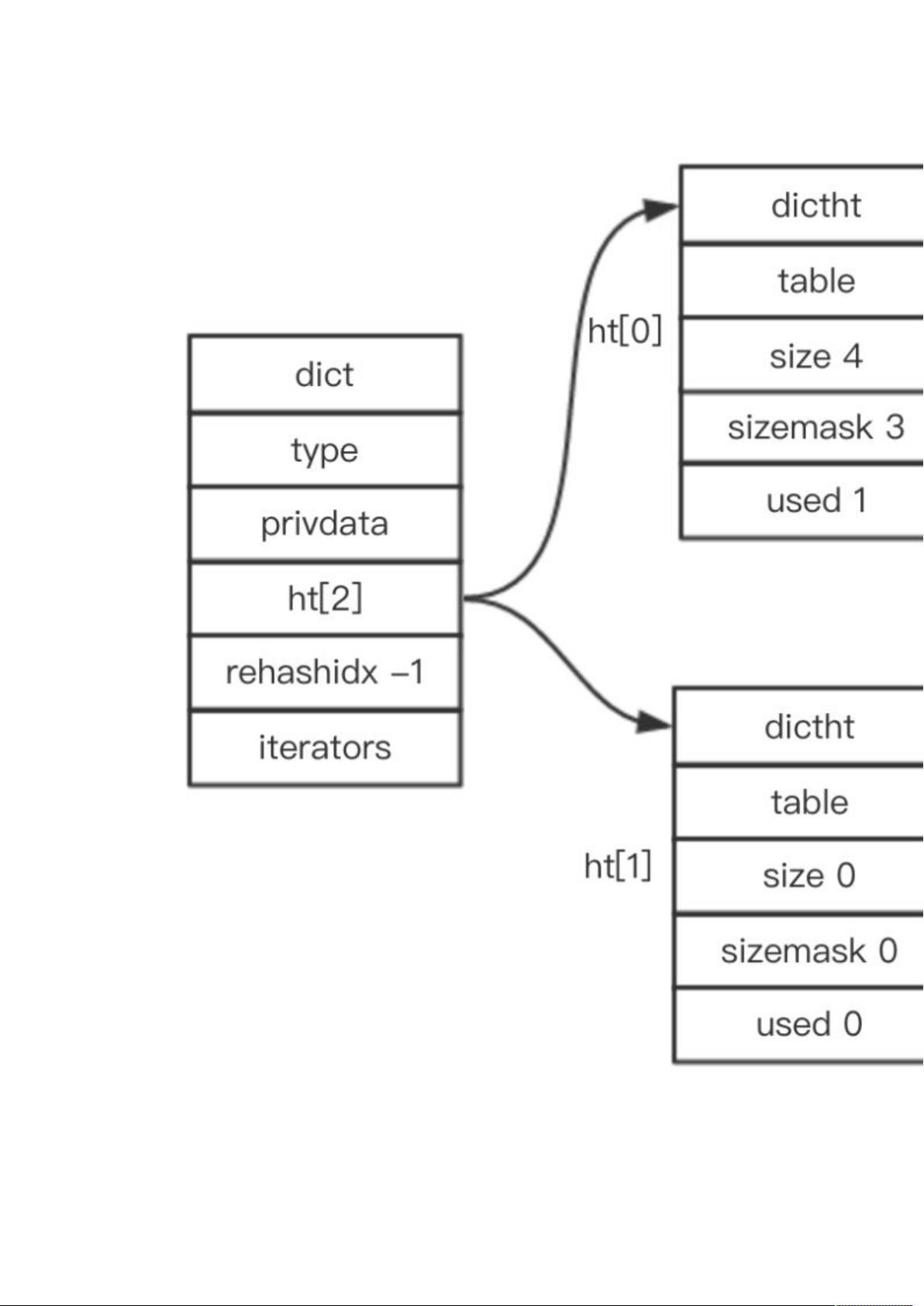
在Redis中,Rehash是一个关键操作,用于在字典(Dict)中动态调整哈希表大小,以应对内存中键值对数量的变化。当哈希表负载因子(已用节点数/总节点数)达到一定阈值时,Redis会启动Rehash过程,以保持高效查找性能。这个过程涉及到将旧哈希表的数据转移到新的更大或更小的哈希表中。
在Redis满容状态下,如果有驱逐策略,当Master节点执行Rehash时,可能会大量淘汰Key,这些Key会被同步到Slave节点。但由于Slave内存空间比Master少了一个repl-backlog-buffer,所以在某些条件下,Slave可能会因满容触发额外的Key驱逐,导致主从数据不一致。这种情况在监控图表中表现为Master和Slave都有大量Key被驱逐。
在问题定位过程中,团队发现常规的外部因素排查并未能解决问题,最终通过对Redis源码的深入分析,发现了Rehash机制可能是罪魁祸首。Redis的哈希表由节点组成,每个节点存储一个键值对,通过哈希函数映射到相应位置。Rehash时,Redis会创建一个新的哈希表,并逐步将旧表中的键值对迁移过去,直到所有数据迁移完成。这个过程中如果处理不当,可能导致内存消耗异常,尤其是在高负载情况下。
为了解决这个问题,Squirrel团队可能采取了以下策略:
1. 调整Rehash策略:比如控制Rehash的速度,避免一次性迁移大量数据,减少对内存和CPU的影响。
2. 增加Slave的内存预留:为Slave节点分配更多内存,以减少因满容触发的额外驱逐。
3. 监控优化:增强对Rehash过程的监控,及时发现并处理异常情况。
4. 客户端优化:限制客户端的并发请求,避免在Rehash期间造成过大压力。
5. 网络优化:改善网络环境,减少丢包现象,确保数据同步的稳定性。
此外,文章提到了针对Redis高负载下中断优化的博客,这部分可能涵盖了如何在系统高负载时保持服务的稳定性和数据一致性,包括但不限于优化网络通信、限制Rehash频率、平滑扩容等措施。
Squirrel团队通过深入理解Redis Rehash机制,成功地解决了在满容状态下因Rehash导致的Key驱逐问题,保证了京东内部缓存系统的稳定性和数据一致性,体现了他们对复杂运维场景的应对能力和持续优化的精神。对于其他使用Redis的企业和开发者来说,这些经验和教训提供了宝贵的参考。
总结一下:

剩余35页未读,继续阅读
2021-10-14 上传
2024-06-06 上传
2024-06-10 上传
2022-07-09 上传
2019-12-12 上传
2021-05-18 上传
2021-02-11 上传
2020-07-28 上传

探索未知的自己
- 粉丝: 143
- 资源: 14
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
