数据挖掘:概念与技术解答手册
需积分: 5 86 浏览量
更新于2024-07-09
收藏 953KB PDF 举报
"《2017 Data Mining Solutions》是数据挖掘领域的一本经典教材《数据挖掘:概念与技术》的第三版课后习题解答,由Jiawei Han、Micheline Kamber和Jian Pei三位专家编写,涵盖了从基础到高级的数据挖掘知识。本书旨在帮助读者理解和掌握数据挖掘的核心概念和技术,包括数据预处理、数据仓库、在线分析处理、数据立方体、频繁模式挖掘、分类、聚类等。"
在数据挖掘这一领域中,理解和应用相关技术至关重要。以下是对标题和描述中涉及知识点的详细说明:
1. **数据挖掘**:数据挖掘是从大量数据中发现有价值知识的过程。它结合了数据库技术、机器学习、统计学和人工智能等多个领域的技术。数据挖掘不仅仅是简单的数据转换或应用,而是通过复杂算法和模型,从数据中提炼出潜在模式、关联规则和趋势,以支持决策。
2. **数据预处理**:在实际的数据挖掘过程中,数据预处理是非常关键的步骤,包括数据清洗(处理缺失值、异常值和不一致性)、数据集成(合并来自多个源的数据)、数据转换(标准化、规范化)和数据规约(减少数据量,如特征选择)。
3. **数据仓库和在线分析处理(OLAP)**:数据仓库是用于决策支持的集成、非易失性、面向主题的数据集合。OLAP则是对数据仓库进行多维分析的技术,支持快速、交互式的查询和报表生成,帮助用户从不同角度理解数据。
4. **数据立方体**:数据立方体是OLAP的核心,它将多维数据集预先计算并存储在立方体结构中,便于用户快速访问和分析。数据立方体的构建涉及到聚集操作,如求和、平均等。
5. **频繁模式、关联规则和相关性**:这些是数据挖掘中的模式发现方法,用于找出数据集中频繁出现的项集(频繁模式)以及项集之间的关系(关联规则)。例如,“啤酒和尿布”案例就展示了商品购买之间的关联性。
6. **分类**:分类是预测性建模技术,通过学习已知类别的样本来构建模型,然后用这个模型对未知类别数据进行预测。基本概念包括决策树、贝叶斯分类、神经网络和支持向量机等。
7. **聚类**:聚类是无监督学习的一种,目的是根据数据的相似性或距离将数据分成不同的组或簇。常用的方法有K均值、层次聚类和DBSCAN等。
8. **高级方法**:在分类和聚类中,还包括一些更复杂的技术,如集成学习(如随机森林)、半监督学习、主动学习和深度学习等,它们在处理大规模数据和复杂问题时更为有效。
每个章节的习题设计都是为了帮助学生深入理解这些概念,通过实践来巩固理论知识,提高数据挖掘的实际应用能力。书中的解答提供了对这些问题的解析,有助于读者自我检查和提高。

7
The median is
median=(50+52)/2=51
The standard deviation is 12.85.
For the variable %fat the mean is 28.78, sortting the %fat is
7.8, 9.5, 17.8, 25.9, 26.5, 27.2, 27.4, 28.8, 30.2, 31.2, 31.4, 32.9, 33.4, 34.1, 34.6,
35.7, 41.2, 42.5
the median is (30.2+31.2)/2=30.7, and the standard deviation is 8.99.
(b) Draw the boxplots for age and %fat.
(18+1)/4=4.75, 3(18+1)/4=14.25,
Age: min=23, max=61, median=51
Q
1
=270.25+390.75=36, Q
3
=570.75+580.25=57.25,
Inter-quartile range: IQR=Q
3
Q
1
=21.25
%fat: min=9.5, max=42.5, median=30.7
Q
1
=25.90.25+26.50.75=26.35, Q
3
=34.10.75+34.60.25=34.225,
Inter-quartile range: IQR=Q
3
Q
1
=7.875
See Figure 2.2.
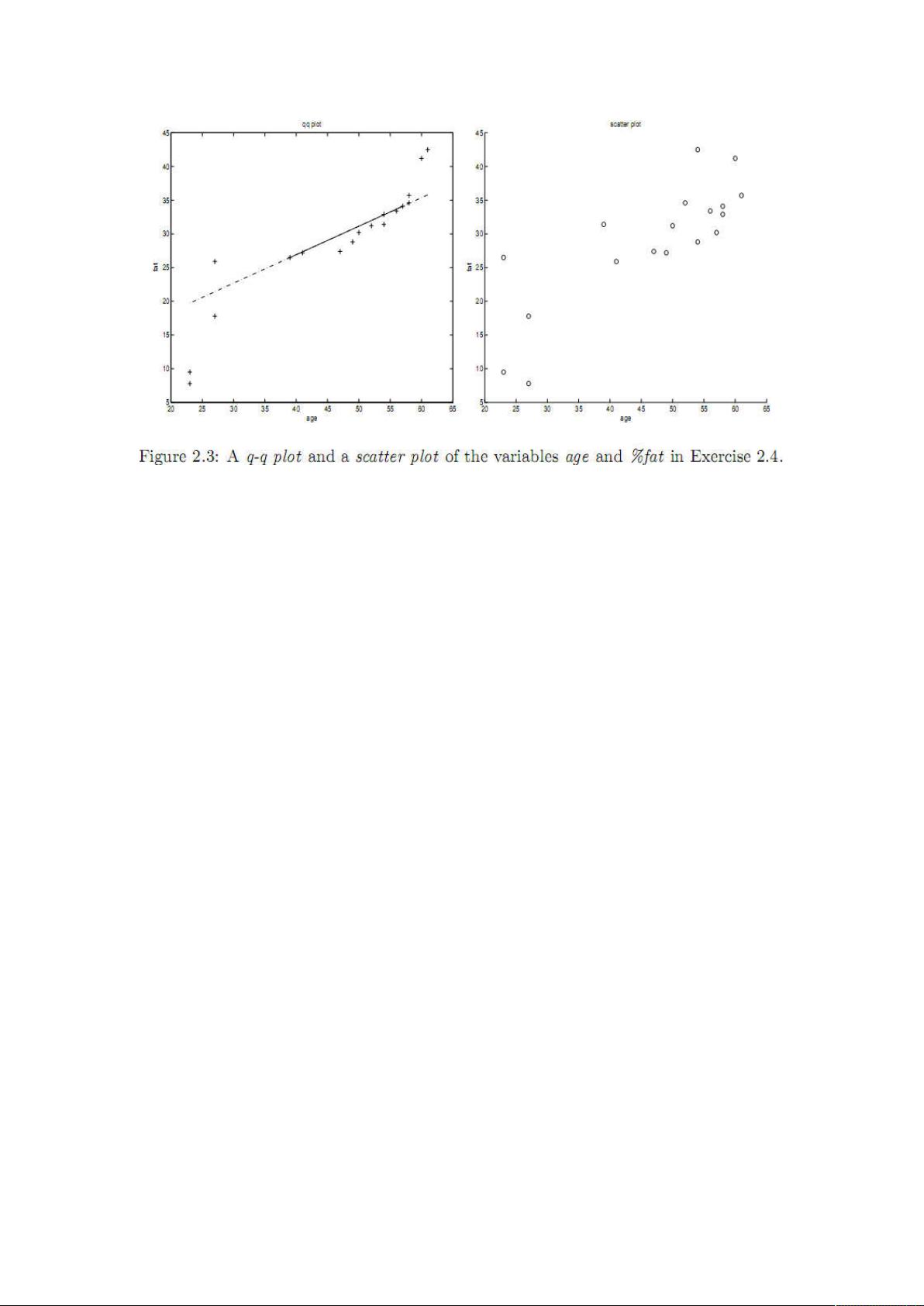
(c) Draw a scatter plot and a q-q plot based on these two variables.
See Figure 2.3.
剩余47页未读,继续阅读
2018-03-29 上传
2018-01-09 上传
2019-09-04 上传
2018-02-09 上传
2009-11-01 上传
2021-09-30 上传
2018-01-23 上传
106 浏览量
2016-12-25 上传

一个鸡翅根
- 粉丝: 1
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- 深入浅出:自定义 Grunt 任务的实践指南
- 网络物理突变工具的多点路径规划实现与分析
- multifeed: 实现多作者间的超核心共享与同步技术
- C++商品交易系统实习项目详细要求
- macOS系统Python模块whl包安装教程
- 掌握fullstackJS:构建React框架与快速开发应用
- React-Purify: 实现React组件纯净方法的工具介绍
- deck.js:构建现代HTML演示的JavaScript库
- nunn:现代C++17实现的机器学习库开源项目
- Python安装包 Acquisition-4.12-cp35-cp35m-win_amd64.whl.zip 使用说明
- Amaranthus-tuberculatus基因组分析脚本集
- Ubuntu 12.04下Realtek RTL8821AE驱动的向后移植指南
- 掌握Jest环境下的最新jsdom功能
- CAGI Toolkit:开源Asterisk PBX的AGI应用开发
- MyDropDemo: 体验QGraphicsView的拖放功能
- 远程FPGA平台上的Quartus II17.1 LCD色块闪烁现象解析
