DPCNN与ResNet对比分析:文本分类新视角
版权申诉
110 浏览量
更新于2024-08-04
收藏 691KB PDF 举报
"文本分类问题不需要ResNet?小夕解析DPCNN设计原理(下)"
在自然语言处理(NLP)领域,文本分类是一项基础且重要的任务,它涉及将文本数据分配到预定义的类别中。本文主要讨论了为何在文本分类问题中,可能并不需要ResNet这样的深度网络架构,而是转向了DPCNN(Depthwise Separable Convolutional Neural Network)的设计原理。
DPCNN是一种针对文本分类优化的卷积神经网络模型,其设计思路与ResNet有所不同。ResNet以其残差连接而闻名,这种设计允许信息直接跨过多层,从而缓解梯度消失和网络训练的难题。然而,DPCNN则采用了一种不同的策略来处理文本序列。
在DPCNN中,作者提出了“Region Embedding”的概念,这是对一段文本(例如3-gram)进行一组卷积操作后生成的嵌入表示。与TextCNN相比,DPCNN在处理3-gram时选择了不保留词序的方法,即将3个词的词嵌入取平均得到一个大小为D的向量,然后应用一维卷积核进行卷积。这种方法类似于词袋模型,被认为能够减少过拟合的风险,同时保持与保留词序方法相近的性能。
DPCNN的结构在底层与TextCNN相似,但其改进在于如何提取文本特征。在TextCNN中,通常采用全局最大池化层(max-over-time pooling layer)来获取每个特征图中最显著的特征,形成文本的特征向量。然而,这种方法的一个问题是它忽略了词序信息,相当于采用了词袋模型,可能导致丢失重要的上下文信息。
为了解决这个问题,DPCNN引入了创新的池化机制。在生成region embedding之后,DPCNN不直接使用全局最大池化,而是通过步长为1的一维最大池化层和一个称为“Interval Max Pooling”的步骤来捕获局部和全局信息。Interval Max Pooling允许网络在不同尺度上捕获信息,增强了模型对不同长度文本的适应性,同时保持了词序的敏感性。
此外,DPCNN还使用了深度可分离卷积(Depthwise Separable Convolution),这是一种轻量级的卷积操作,它将标准卷积分解为深度卷积和点卷积两步,减少了计算复杂度,使得网络能够在保持性能的同时降低参数数量。
DPCNN通过其独特的region embedding和改进的池化策略,在文本分类任务中提供了一种有效的替代方案,它无需ResNet的复杂结构也能实现良好的性能。对于NLP研究者和实践者来说,理解DPCNN的设计原理有助于在特定场景下选择更合适的模型架构,以提高文本分类任务的效率和准确性。
⽂本分类问题不需要ResNet?⼩⼣解析DPCNN设计原理(下)
原创
⼣⼩瑶
2018-04-07⼣⼩瑶的卖萌屋
来⾃专辑
卖萌屋@⾃然语⾔处理
哎呀呀,说好的不拖稿的⼜拖了两天T_T,⼩⼣过⼀阵⼦分享给你们这两天的开⼼事哦。后台催稿调参系列的⼩伙伴们不要急,
下⼀篇就是第⼆篇调参⽂啦。
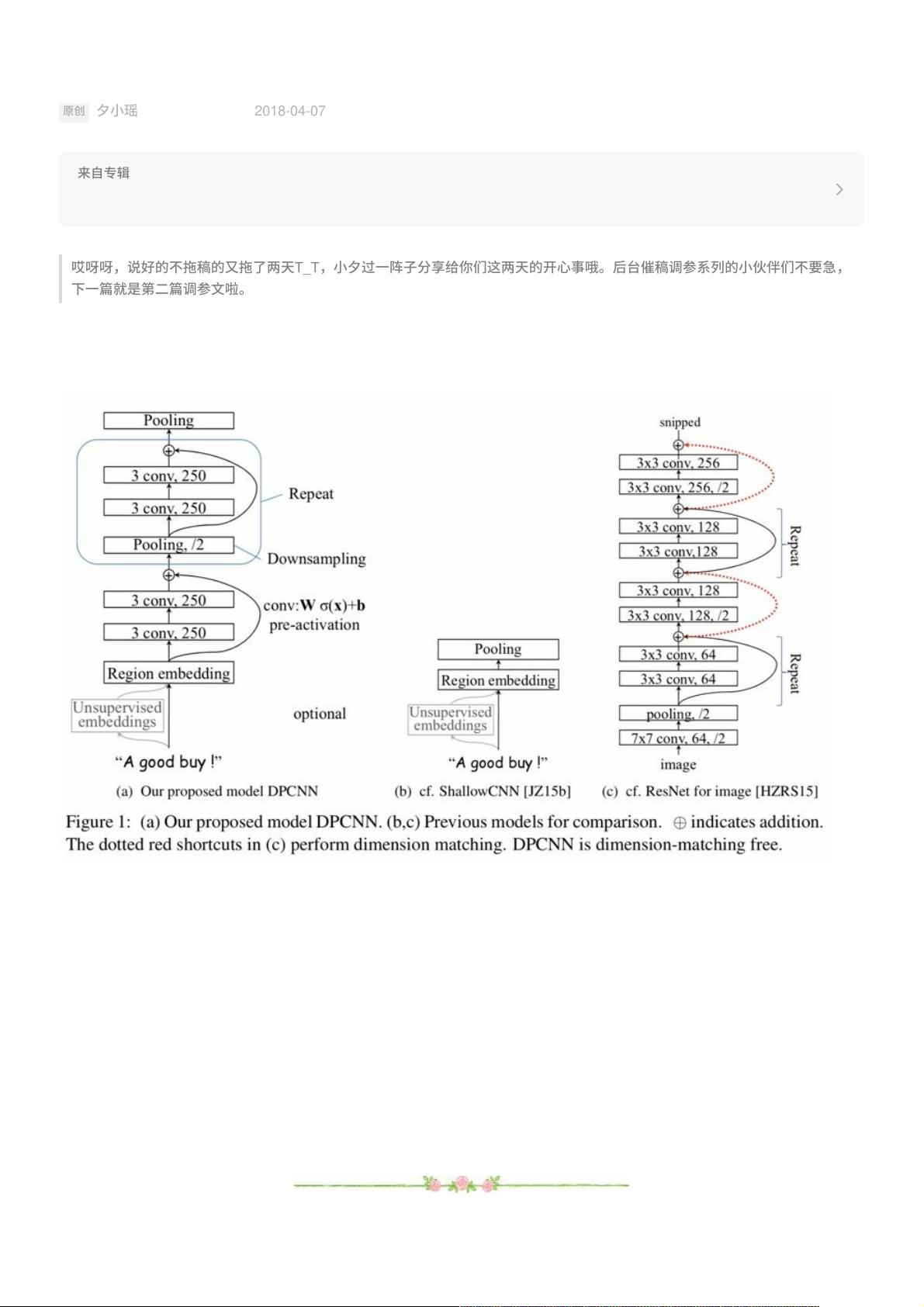
好啦,接着上⼀篇⽂章,直接搬来DPCNN、ShallowCNN、ResNet的对⽐图。
从图中的a和c的对⽐可以看出,DPCNN与ResNet差异还是蛮⼤的。同时DPCNN的底层貌似保持了跟TextCNN⼀样
的结构,这⾥作者将TextCNN的包含多尺⼨卷积滤波器的卷积层的卷积结果称之为Region embedding,意思就是对
⼀个⽂本区域/⽚段(⽐如3gram)进⾏⼀组卷积操作后⽣成的embedding。
对⼀个3gram进⾏卷积操作时可以有两种选择,⼀种是保留词序,也就是设置⼀组size=3*D的⼆维卷积核对3gram进
⾏卷积(其中D是word embedding维度); 还有⼀种是不保留词序(即使⽤词袋模型),即⾸先对3gram中的3个词
的embedding取均值得到⼀个size=D的向量,然后设置⼀组size=D的⼀维卷积核对该3gram进⾏卷积。显然
TextCNN⾥使⽤的是保留词序的做法,⽽DPCNN使⽤的是词袋模型的做法,DPCNN作者argue前者做法更容易造成
过拟合,后者的性能却跟前者差不多(其实这个跟DAN⽹络(Deep averaging networks)中argue的原理和结论差
不多,有兴趣的可以下拉到下⼀部分的知乎传送⻔中了解⼀下)。
产⽣region embedding后,按照经典的TextCNN的做法的话,就是从每个特征 图中挑选出最有代表性的特征,也就
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-08-12 上传
2023-10-13 上传
2023-10-18 上传
180 浏览量

普通网友
- 粉丝: 1283
 我的内容管理
展开
我的内容管理
展开







最新资源
- 多功能字模信息获取工具应用详解
- ADV2FITS开源工具:视频帧转换为FITS格式
- Tropico 6内存读取工具:游戏数据提取与分析
- TcpUdp-v2.1:便捷网络端口管理小工具
- 专业笔记本BIOS刷新软件InsydeFlash 3.53汉化版
- GridView中加入全选复选框的客户端操作技巧
- 基于JAVA和ORACLE的网吧计费系统解决方案
- Linux环境下Vim插件vim-silicon:源代码图像化解决方案
- xhEditor:轻量级开源Web可视化HTML编辑器
- 全面掌握Excel技能的视频课程指南
- QDashBoard:基于QML的仪表盘开发教程
- 基于MATLAB的图片文字定位技术
- Proteus万年历仿真项目:附源代码与Proteus6.9SP4测试
- STM32 LED实验教程:点亮你的第一个LED灯
- 基于HTML的音乐推荐系统开发
- 全中文注释的轻量级Vim配置教程
