自监督学习框架SelfLinKG:链接知识图谱的新方法
需积分: 8 23 浏览量
更新于2024-08-04
收藏 3MB PDF 举报
"Self-supervised Learning for Linking Knowledge Graphs(TKDE21)" 是一篇关于自监督学习在知识图谱链接中的应用的学术论文。该研究提出了一种新的无监督嵌入学习框架——SelfLinKG,用于异构知识图谱中概念的链接。即使在没有标注数据的情况下,SelfLinKG也能与有监督方法相媲美,并在线性分类协议下显著优于现有的无监督方法,提升性能26%到50%。
论文的关键词包括:概念链接、自监督学习、对比学习和知识库。
1
**INTRODUCTION**
概念链接是将知识图谱中的实体或概念正确关联起来的关键任务。传统的方法通常依赖于大量的人工标注数据,这在大规模知识图谱中往往是不切实际的。自监督学习为解决这一问题提供了一种新的途径,它可以在无需额外标注数据的情况下训练模型。
**SelfLinKG框架**
SelfLinKG的核心组成部分包括局部注意力编码和动量对比学习。局部注意力编码利用注意力网络来学习图的表示,强调了图中不同节点和边的重要性,从而捕捉到更丰富的结构信息。而动量对比学习则是一种自监督策略,通过在不同的知识图谱之间构建对比任务,让模型学习区分不同的知识表示,增强了模型的泛化能力。
**方法详解**
局部注意力编码:通过注意力机制,模型可以聚焦于对链接任务重要的部分,忽略不相关的特征,这有助于提取更有效的概念表示。
动量对比学习:在这一过程中,模型通过不断比较同一概念在不同知识图谱中的表示,学习到一个稳定的、区分度高的表示。这种方法增强了模型的学习能力,使其能在未见过的数据上表现良好。
**实验与结果**
SelfLinKG在一系列实验中验证了其优越性,尤其是在与有监督和无监督方法的对比中,其性能提升显著。此外,该框架已被应用于构建OAGknow,这是Open Academic Graph (OAG)的最新版本,所有数据和代码都已公开,可供研究社区使用。
**结论与未来工作**
SelfLinKG的出色表现展示了自监督学习在知识图谱领域的巨大潜力。未来的研究可能会探索如何进一步优化模型,提高链接预测的准确性和效率,同时可能扩展到更复杂的知识图谱任务,如实体消歧和知识图谱完善。
"Self-supervised Learning for Linking Knowledge Graphs" 提供了一种创新的无监督学习方法,对知识图谱领域的研究和实践有着重要的贡献,尤其在减少对标注数据的依赖方面,为知识图谱的自动链接和扩展开辟了新的道路。
3
The problem is challenging, as it is difficult to acquire
sufficiently labeled data to train an effective machine learning
model. To deal with this issue, we desire to have a powerful
unsupervised or semi-supervised model. Second, there is
also the name disambiguation issue. For example, there are
four different “entropy” entries in Wikipedia, and how to link
different ones with those in academic graphs is challenging.
Finally, the model needs to handle the scalability, as to train
and deploy a model to deal with thousands of millions of
concepts is not an easy task.
To deal with the aforementioned issues, especially the
first one, we further clarify the supervised and unsupervised
(or self-supervised) embedding learning for concept linking
in the following definition.
Definition 3. Embedding Learning for Concept Linking
Given m knowledge bases represented as m graphs
G
p
=
{C
p
,R
p
,A
p
}(p =1, ··· ,m)
, a embedding function
f : c|G !
R
d
is learned such that for each concept
c
(p)
i
2 C
p
, embedding
v
(p)
i
= f(c
(p)
i
|G
p
)
could be efficiently utilized to recover the full
concept linkings
L = {(c
(p)
i
,c
(q)
j
)|c
(p)
i
2 C
p
,c
(q)
j
2 C
q
,p6= q}
in:
1) Supervised
setting: part of
L
is provided as the training set
for training f.
2) Unsupervised (Self-supervised)
setting: none of
L
is
provided for training f.
3THE SELFLINKG FRAMEWORK
In this section, we present the self-supervised embedding
learning framework—SelfLinKG—for linking concepts across
knowledge bases. We will first discuss the motivation of
SelfLinKG and then introduce its two components.
3.1 Motivation
In related fields of concept linking, such as entity align-
ment, embedding-based methods are generally based on
supervised learning. Supervised learning has achieved great
success in the last decade, but it suffers from heavy depen-
dency on manual labels and poor scalability on unseen data.
These problems are especially fatal to large-scale concept
linking and entity alignment. A large amount of manually
labeled data is too expensive, and to make the linking system
online, we need to make the algorithm scalable.
Despite the drawbacks of supervised learning, however,
previously people have few choices but to choose it because
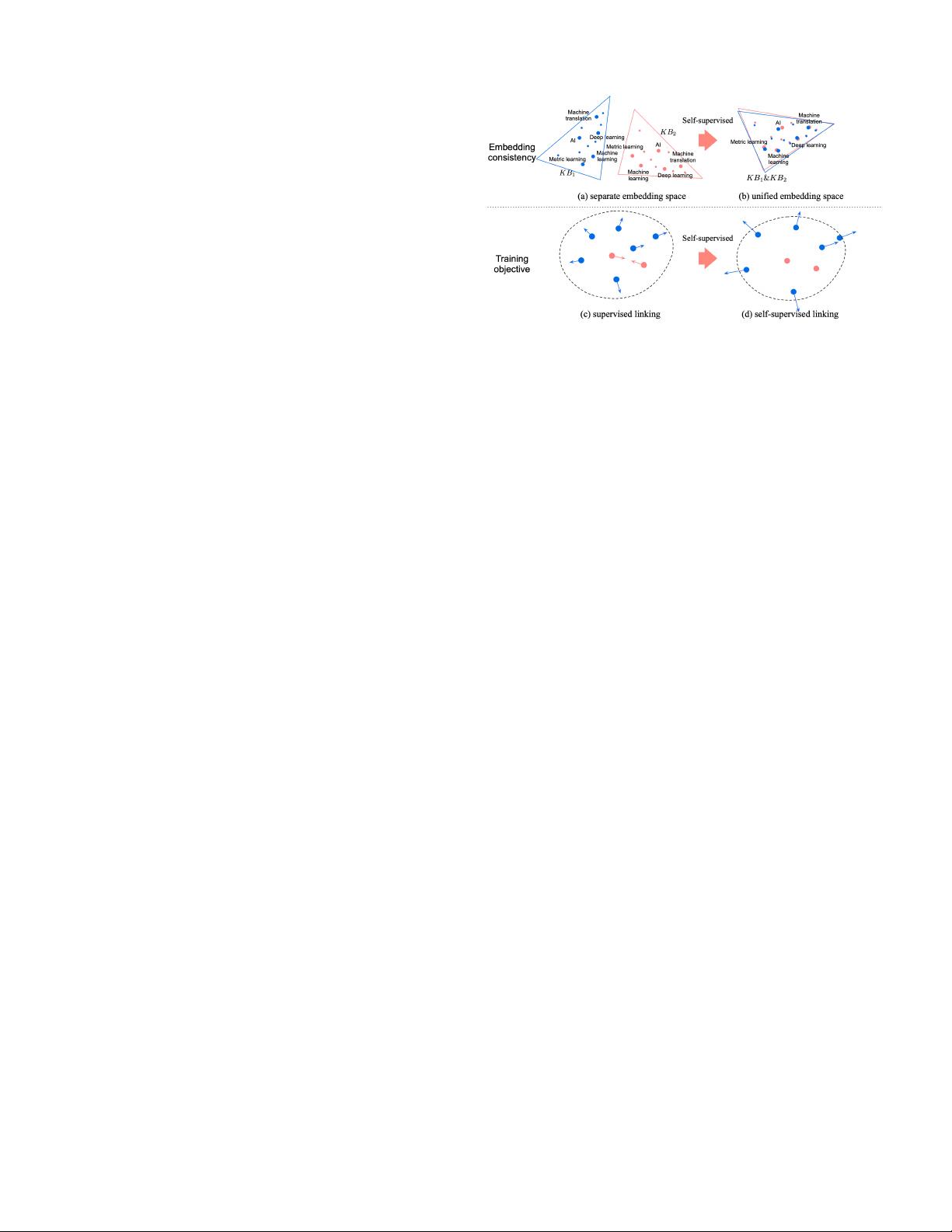
of two important reasons as shown in Figure 2:
1) Lack of embedding consistency.
For concepts in differ-
ent KBs, their representations are located in different
and inconsistent embedding spaces (just like two people
using two languages). To make their embeddings consis-
tent, we can either use a supervised classifier to bridge
the gap (a translator [16]) or let them fall into the same
embedding space by anchor nodes (both turn to use the
third language [2], [18], [31], [45]). Both methods require
external supervision.
2) Lack of training objective.
In supervised learning,
labels serve as objectives for encoders to draw near
positive samples and push away negative samples.
Without labels, such a goal seems to be impossible
because we can not draw near positive pairs.
Fig. 2: Motivation of SelfLinKG from perspectives of embed-
ding consistency and training objective.
Are there any means to cope with these problems, or part
of them, without labels? Fortunately, recent breakthroughs
in self-supervised learning shed light on this question.
In terms of embedding consistency, if KBs are in the same
language, we can leverage the inherent embedding space of
it. Instead of using word embeddings trained separately on
different KBs, pre-trained language models such as BERT can
provide a unified initial embedding space for concepts from
different KBs. During the training, a shared encoder that yields
embeddings for concepts from different KBs will further
ensure the consistency.
In terms of training objectives, without labels, we cannot
draw near positive sample pairs. However, there are always
abundant negative samples. If we can push away negative
samples from each other as much as possible, it equals we
relatively draw near positive ones that share similarity to
some extent. The instance discrimination pretext task with
contrastive loss are born for that purpose.
To sum up, we propose SelfLinKG, a concept learn-
ing framework to deal with the large-scale heterogeneous
concept linking problem without an arduously expensive
process for producing massive labeled data. We propose
to leverage self-supervised learning to learn the intrinsic
relations between concepts across the two knowledge bases,
which also help mitigate the scalability issue for handling
large-scale data. In the following sections, we will introduce
two components that SelfLinKG comprises of in details: 1)
local attention-based encoding and 2) global momentum
contrastive learning. Figure 3 illustrates the architecture of
SelfLinKG.
Local Attention-based Encoding. The local attention-based
encoding aims to tackle the data heterogeneity and map both
data into the same latent space at both entity-level and graph-
level. For entity-level, both semantic information and struc-
tural information are involved. We design a heterogeneous
graph-attention-based encoder to aggregate information from
the taxonomy structures (both hierarchy and neighborhood).
For graph-level, we formulate taxonomies, encyclopedias,
and knowledge graphs into unified attributed graphs with
two types of relations (hyponym and related) to simplify the
problem.
Global Momentum Contrastive Learning. After encoding
concepts’ into vectors in the first step, we propose to use
剩余12页未读,继续阅读
2021-11-17 上传
2022-03-22 上传
2022-12-20 上传
2021-09-23 上传
2021-09-25 上传
2022-12-20 上传
2021-04-02 上传
点击了解资源详情
2023-02-22 上传

那后来呢z
- 粉丝: 3
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- Android圆角进度条控件的设计与应用
- mui框架实现带侧边栏的响应式布局
- Android仿知乎横线直线进度条实现教程
- SSM选课系统实现:Spring+SpringMVC+MyBatis源码剖析
- 使用JavaScript开发的流星待办事项应用
- Google Code Jam 2015竞赛回顾与Java编程实践
- Angular 2与NW.js集成:通过Webpack和Gulp构建环境详解
- OneDayTripPlanner:数字化城市旅游活动规划助手
- TinySTM 轻量级原子操作库的详细介绍与安装指南
- 模拟PHP序列化:JavaScript实现序列化与反序列化技术
- ***进销存系统全面功能介绍与开发指南
- 掌握Clojure命名空间的正确重新加载技巧
- 免费获取VMD模态分解Matlab源代码与案例数据
- BuglyEasyToUnity最新更新优化:简化Unity开发者接入流程
- Android学生俱乐部项目任务2解析与实践
- 掌握Elixir语言构建高效分布式网络爬虫
