Databricks使用指南:数据读写与集群配置
版权申诉
136 浏览量
更新于2024-07-19
收藏 8.12MB DOCX 举报
"Project DNA Databricks Guide 是一个关于如何使用Databricks进行数据操作的文档,涵盖了历史、环境设置、挂载点信息以及Python编程的相关知识。文档中提到了如何在Databricks集群上安装库,并展示了读取和写入数据的通用语法,包括两种不同的方法。"
在Databricks环境中,Python被广泛用于数据处理,特别是通过Apache Spark API。以下是对文档中提到的一些关键知识点的详细解释:
1. **背景**:Project DNA Databricks Guide可能是一个项目团队用来指导成员使用Databricks平台进行数据处理的文档。Databricks是基于Apache Spark的云服务,提供了一个协作的工作环境,便于数据科学家和工程师进行大数据分析。
2. **环境**:文档提到了两个挂载点——"Rawzone"和"Curzone",它们都是在Databricks中用于存储和访问数据的目录。例如,`dbfs:///mnt/raw_zone`是原始数据区,而`dbfs:///mnt/cur_zone`是当前工作区。DBFS(Databricks File System)是一个分布式文件系统,用于在Databricks集群间共享数据。
3. **挂载点**:挂载点允许用户将外部数据源(如AWS S3或Azure Blob存储)连接到Databricks的DBFS,以便在Spark作业中使用。在Databricks中,可以通过配置集群来创建和管理挂载点。
4. **Databricks Cluster配置**:配置Databricks集群涉及到选择合适的硬件规格(如节点数、内存和CPU),并安装必要的库。文档指出,目前的安装库过程是通过向特定人员(Kobe)发送邮件请求帮助。
5. **库安装**:在Databricks中安装Python库通常是通过Databricks的Libraries功能完成的,它可以自动将库分发到集群的所有节点。然而,文档中的现有流程似乎依赖于手动干预,这可能不是一个自动化和高效的过程。
6. **读取数据**:在Python中,使用`spark.read`函数可以读取各种数据格式。文档提供了两种方法:
- 方法1:使用`.format()`指定文件格式,然后通过`.option()`设置选项,最后用`.load()`加载文件路径。
- 方法2:对于内置的Spark文件格式,可以直接调用如`.read.csv()`,然后设置选项和加载路径。
7. **写入数据**:写入数据也有类似的方法:
- 方法1:使用`.write.format()`指定输出格式,`.mode()`定义保存模式(如追加、覆盖或忽略),再设置选项和加载路径。
- 方法2:对于某些内置格式,可以直接使用如`.write.csv()`,然后设置模式和选项。
8. **注意**:文件路径支持通配符“*”来匹配多个文件,例如`/tmp/*.csv`可以匹配所有位于`/tmp`目录下的CSV文件。
以上就是Databricks Guide中涉及的主要知识点,这些知识对于在Databricks环境中进行数据处理和分析是非常基础且重要的。

‘quote’:'"', # sets a single character used for escaping quoted values where the separator can be
part of the value. If None is set, it uses the default value, ". If you would like to turn off
quotations, you need to set an empty string. "escape":'"', # sets a single character used for
escaping quotes inside an already quoted value. If None is set, it uses the default value, \.
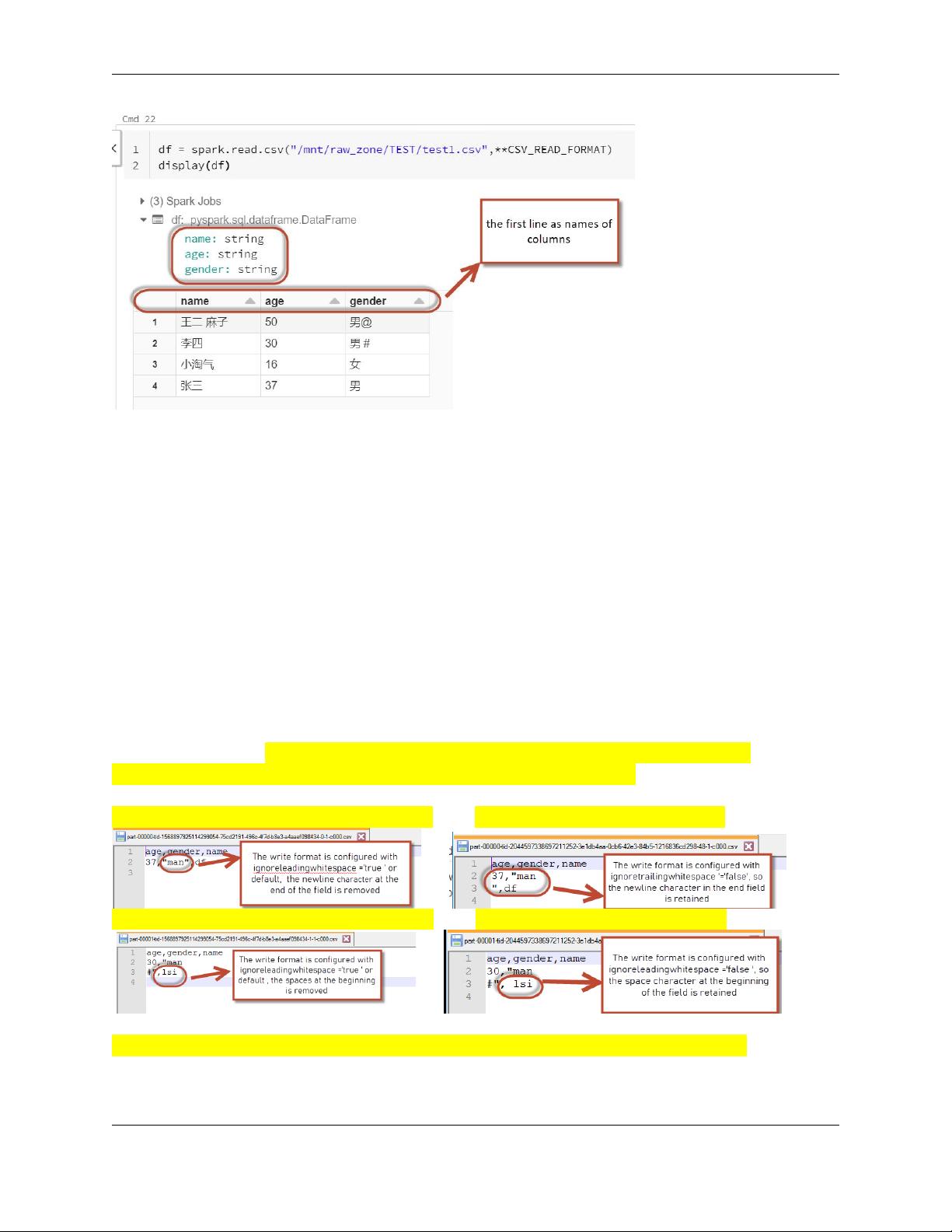
"header":True, # uses the first line as names of columns. If None is set, it uses the default value,
false.
'ignoreLeadingWhiteSpace':False, # A flag indicating whether or not leading whitespaces from
values being read should be skipped. If None is set, it uses the default value, false.
'ignoreTrailingWhiteSpace':False,# flag indicating whether or not trailing whitespaces from
values being read should be skipped. If None is set, it uses the default value, false.
'multiLine':True, # using the multiline option; Spark considers you have multiline rows in
double-quotes or any special escape characters
'encoding':'utf-8',# decodes the CSV files by the given encoding type. If None is set, it uses the
default value, UTF-8.
'lineSep':'\n', # defines the line separator that should be used for parsing. If None is set, it covers
all \\r, \\r\\n and \\n. Maximum length is 1 character.
'nullValue':None, # sets the string representation of a null value. If None is set, it uses the
default value, empty string. Since 2.0.1, thisnullValueparam applies to all supported types
including the string type.
'emptyValue':'' # sets the string representation of an empty value. If None is set, it uses the
default value, empty string.
3.2.2 Common Option setting example
header
csv_format: "header":False or default
After use define csv_format: "header":True
剩余32页未读,继续阅读
2022-07-11 上传
2021-07-05 上传
2024-09-30 上传
2023-07-25 上传
2024-10-31 上传

虾稿
- 粉丝: 186
- 资源: 27
 我的内容管理
展开
我的内容管理
展开







最新资源
- 基于Python和Opencv的车牌识别系统实现
- 我的代码小部件库:统计、MySQL操作与树结构功能
- React初学者入门指南:快速构建并部署你的第一个应用
- Oddish:夜潜CSGO皮肤,智能爬虫技术解析
- 利用REST HaProxy实现haproxy.cfg配置的HTTP接口化
- LeetCode用例构造实践:CMake和GoogleTest的应用
- 快速搭建vulhub靶场:简化docker-compose与vulhub-master下载
- 天秤座术语表:glossariolibras项目安装与使用指南
- 从Vercel到Firebase的全栈Amazon克隆项目指南
- ANU PK大楼Studio 1的3D声效和Ambisonic技术体验
- C#实现的鼠标事件功能演示
- 掌握DP-10:LeetCode超级掉蛋与爆破气球
- C与SDL开发的游戏如何编译至WebAssembly平台
- CastorDOC开源应用程序:文档管理功能与Alfresco集成
- LeetCode用例构造与计算机科学基础:数据结构与设计模式
- 通过travis-nightly-builder实现自动化API与Rake任务构建
