Python3模拟登录GitHub爬取教程
56 浏览量
更新于2024-09-01
收藏 559KB PDF 举报
"本文主要介绍如何使用Python3模拟登录GitHub并进行网页爬取。通过模拟登录,我们可以访问登录后才能看到的个人动态等信息。首先,我们需要了解模拟登录的原理,即保持登录状态的Cookies维护。然后,我们将分析GitHub的登录过程,包括查看登录请求的URL、POST数据和Headers信息,特别是重点解析authenticity_token和Cookies的获取。在环境准备阶段,确保已安装requests和lxml库。最后,我们将详细介绍如何编写Python代码来模拟登录并爬取数据。"
模拟登录GitHub的关键步骤如下:
1. 分析登录请求:首先,我们需要打开GitHub的登录页面(https://github.com/login),并在登录时启用开发者工具的Preserve Log功能,以便查看登录请求的详细信息。
2. 查看POST请求:登录按钮被点击后,会触发一个POST请求到https://github.com/session。这个请求包含必要的数据,如用户名、密码以及两个难以直接构造的参数:Cookies和authenticity_token。
3. 解析请求数据:POST请求的FormData包含固定字符串“commit=Signin”、utf8字符、较长的authenticity_token(可能是Base64编码的加密字符串)以及登录的用户名和密码。Headers部分包括Cookies、Host、Origin、Referer和User-Agent等信息。
4. 获取authenticity_token:authenticity_token通常用于防止跨站请求伪造(CSRF)。在未登录状态下,访问登录页面时,可以通过分析页面源代码或使用JavaScript执行来获取该token。
5. 保持登录状态:登录成功后,服务器会返回一个包含登录状态的Cookies,我们需要在后续的HTTP请求中携带这个Cookies,以表明我们已登录。
6. 编写Python代码:使用requests库发送登录请求,构造POST数据,包括用户名、密码以及通过分析得到的authenticity_token。登录成功后,保存返回的Cookies。然后,使用相同的Cookies发起新的请求,以访问登录后的内容。
7. 爬取数据:有了有效的登录状态,我们可以遍历和解析登录后才能访问的页面,例如用户动态、个人信息等,使用requests库发送GET请求,并在请求头中设置登录时得到的Cookies。
在实际操作中,还需要注意以下几点:
- 错误处理:模拟登录时可能会遇到验证码、账户验证等问题,需要编写相应的错误处理代码。
- 遵守GitHub的robots.txt规则和使用条款,避免因为频繁请求而被封禁。
- 使用代理IP或设置请求间隔,减少对GitHub服务器的压力,提高爬虫的持久性。
通过以上步骤,我们可以编写出一个能够模拟登录GitHub并爬取相关数据的Python程序。这个程序不仅适用于GitHub,还可以应用到其他需要模拟登录的网站,只要理解其登录机制并适当地调整代码即可。
Python3以以GitHub为例来实现模拟登录和爬取的实例讲解为例来实现模拟登录和爬取的实例讲解
在本篇内容里小编给大家分享的是关于Python3以GitHub为例来实现模拟登录和爬取的实例讲解,需要的朋友们
可以参考下。
我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后 Cookies 的维护。
1. 本节目标本节目标
本节将讲解以 GitHub 为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态、个人信息等内容。
我们应该都听说过 GitHub,如果在我们在 Github 上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近
收藏了哪个 Repository,创建了哪个组织,推送了哪些代码。但是退出登录之后,我们就无法再看到这些信息。
如果希望爬取 GitHub 上所关注人的最近动态,我们就需要模拟登录 GitHub。
2. 环境准备环境准备
请确保已经安装好了 requests 和 lxml 库,如没有安装可以参考第 1 章的安装说明。
3. 分析登录过程分析登录过程
首先要分析登录的过程,需要探究后台的登录请求是怎样发送的,登录之后又有怎样的处理过程。
如果已经登录 GitHub,先退出登录,同时清除 Cookies。
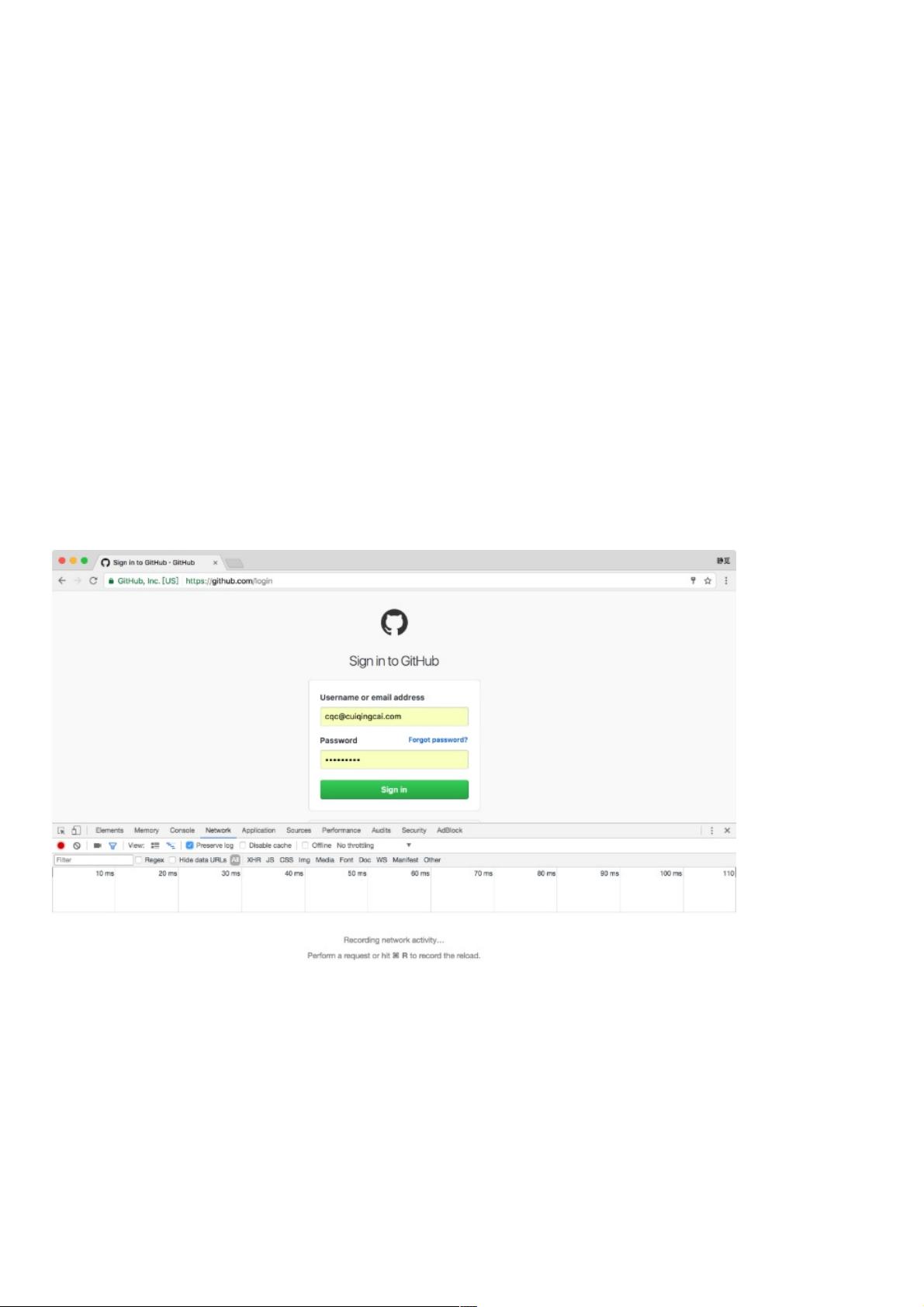
打开 GitHub 的登录页面,链接为 https://github.com/login,输入 GitHub 的用户名和密码,打开开发者工具,将 Preserve Log
选项勾选上,这表示显示持续日志,如图 10-1 所示。
点击登录按钮,这时便会看到开发者工具下方显示了各个请求过程,如图 10-2 所示。
下载后可阅读完整内容,剩余4页未读,立即下载
2020-12-25 上传
2023-11-09 上传
2022-12-13 上传
2021-05-19 上传
2024-04-03 上传
2024-01-20 上传
2020-09-16 上传
点击了解资源详情

weixin_38712279
- 粉丝: 6
- 资源: 949
 我的内容管理
展开
我的内容管理
展开







最新资源
- 高清艺术文字图标资源,PNG和ICO格式免费下载
- mui框架HTML5应用界面组件使用示例教程
- Vue.js开发利器:chrome-vue-devtools插件解析
- 掌握ElectronBrowserJS:打造跨平台电子应用
- 前端导师教程:构建与部署社交证明页面
- Java多线程与线程安全在断点续传中的实现
- 免Root一键卸载安卓预装应用教程
- 易语言实现高级表格滚动条完美控制技巧
- 超声波测距尺的源码实现
- 数据可视化与交互:构建易用的数据界面
- 实现Discourse外聘回复自动标记的简易插件
- 链表的头插法与尾插法实现及长度计算
- Playwright与Typescript及Mocha集成:自动化UI测试实践指南
- 128x128像素线性工具图标下载集合
- 易语言安装包程序增强版:智能导入与重复库过滤
- 利用AJAX与Spotify API在Google地图中探索世界音乐排行榜
