SQL数据库实战:一步步教你创建表分区
需积分: 34 182 浏览量
更新于2024-09-14
收藏 448KB DOC 举报
"本文将详细指导如何在SQL数据库中创建表分区,提高数据处理性能。"
在数据库管理中,表分区是一种优化策略,它能够提高大数据量查询的效率,通过将大表的数据分散到多个物理存储单元(如磁盘)上,从而减少I/O操作,加快数据检索速度。本文以SQL为例,手把手教你如何建立表分区。
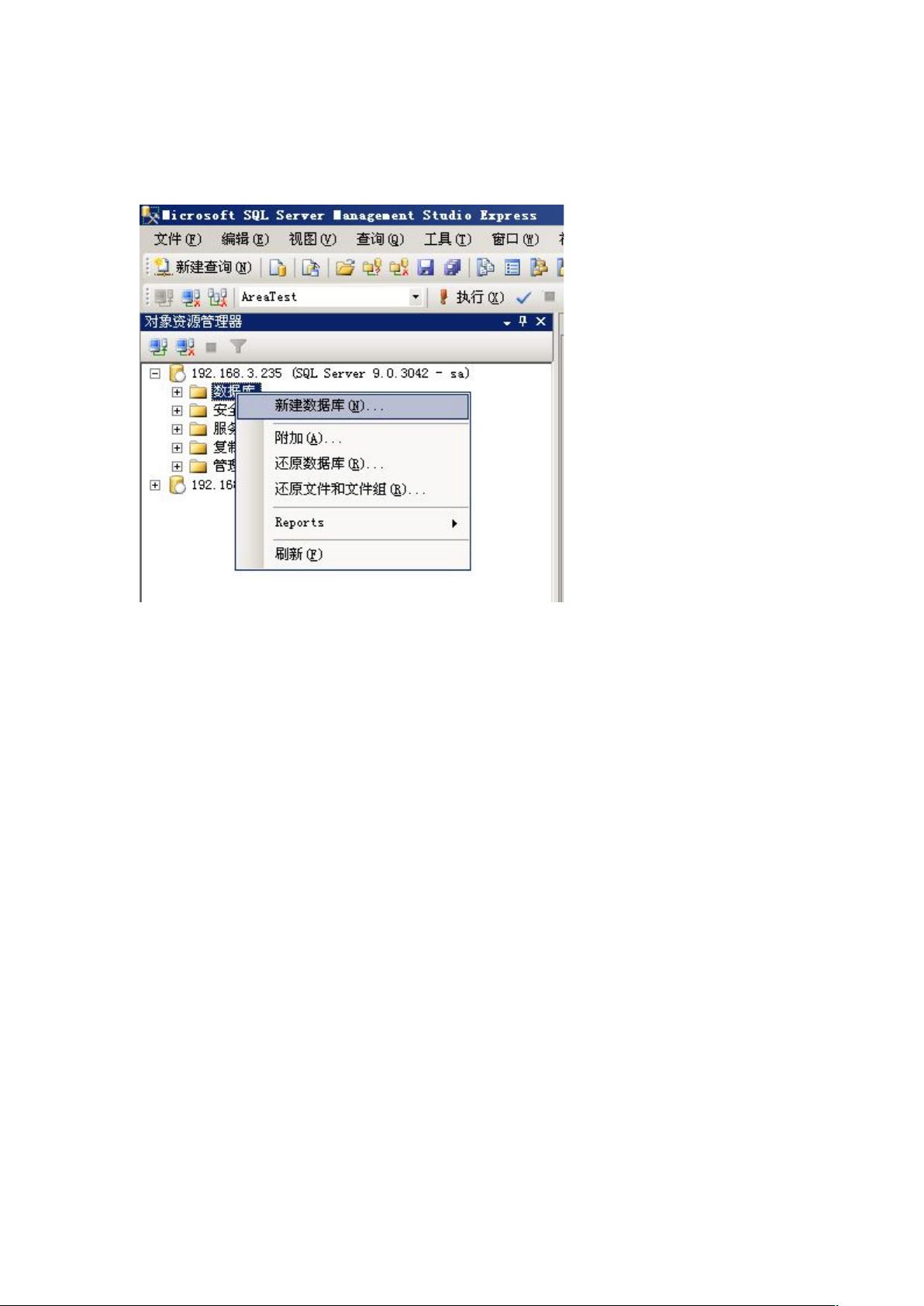
首先,我们需要新建一个数据库。在SQL Server Management Studio (SSMS) 中,选择"数据库" -> "新建数据库",在弹出的对话框中设置数据库名称,并在"文件"选项卡下添加多个文件组。每个文件组对应一个物理文件,建议将这些文件分布在不同的磁盘上,以利用并行读写提升性能。点击"确定"完成数据库的创建。
接着,我们需要创建一个分区函数。分区函数定义了数据如何根据指定的列(如日期时间列)进行划分。例如,以下SQL语句创建了一个名为PartFuncForExample的分区函数,基于Datetime列,以每年的1月1日作为分区边界:
```sql
CREATE PARTITION FUNCTION PartFuncForExample(Datetime)
AS RANGE RIGHT FOR VALUES ('20000101', '20010101', '20020101', '20030101');
```
在这个例子中,"RIGHT"关键字意味着大于或等于每个边界值的数据将被分配到下一个分区。创建后,你可以在"系统目录视图"中查看到这个分区函数。
然后,我们需要创建一个分区方案,它会将分区函数创建的分区映射到具体的文件组。下面的SQL语句创建了一个名为PartSchForExample的分区方案:
```sql
CREATE PARTITION SCHEME PartSchForExample
AS PARTITION PartFuncForExample
TO (PRIMARY, Partition1, Partition2, Partition3);
```
这个分区方案将根据分区函数PartFuncForExample将数据分布到 PRIMARY 文件组和另外三个自定义的文件组。
最后,当我们创建一个表时,可以指定该表使用我们定义的分区方案。例如:
```sql
CREATE TABLE MyPartitionedTable (
Id INT IDENTITY,
DateTimeCol DATETIME,
...
) ON PartSchForExample(DateTimeCol);
```
在这个例子中,DateTimeCol 列将用于分区,MyPartitionedTable 的数据将根据PartSchForExample 分区方案自动分布到相应的文件组。
通过这种方式,我们可以有效地管理和优化大数据量的表,提高SQL查询的执行效率。值得注意的是,分区策略需要根据实际业务需求和数据分布情况来设计,以确保最佳性能。同时,创建和维护分区可能会带来额外的存储开销和复杂性,因此在实施前应充分评估其必要性和效益。
手把手教你建立 SQL 数据库的表分区
1)新建一个数据库
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-03-07 上传
2019-12-27 上传
2010-05-12 上传
2019-12-01 上传
2008-01-22 上传

wenzhiguo96
- 粉丝: 0
- 资源: 4
 我的内容管理
展开
我的内容管理
展开







最新资源
- Angular实现MarcHayek简历展示应用教程
- Crossbow Spot最新更新 - 获取Chrome扩展新闻
- 量子管道网络优化与Python实现
- Debian系统中APT缓存维护工具的使用方法与实践
- Python模块AccessControl的Windows64位安装文件介绍
- 掌握最新*** Fisher资讯,使用Google Chrome扩展
- Ember应用程序开发流程与环境配置指南
- EZPCOpenSDK_v5.1.2_build***版本更新详情
- Postcode-Finder:利用JavaScript和Google Geocode API实现
- AWS商业交易监控器:航线行为分析与营销策略制定
- AccessControl-4.0b6压缩包详细使用教程
- Python编程实践与技巧汇总
- 使用Sikuli和Python打造颜色求解器项目
- .Net基础视频教程:掌握GDI绘图技术
- 深入理解数据结构与JavaScript实践项目
- 双子座在线裁判系统:提高编程竞赛效率
