李宏毅机器学习课程:深度自编码器与无监督学习
需积分: 0 110 浏览量
更新于2024-06-18
收藏 2.45MB PPTX 举报
"该资源是台湾大学李宏毅教授在B站发布的机器学习课程相关课件,主要涉及无监督学习中的深度自编码器(Deep Auto-encoder)技术。"
深度自编码器是一种无监督学习方法,它由两部分组成:编码器(Encoder)和解码器(Decoder)。编码器负责将输入数据压缩成一个紧凑的表示形式,称为编码(code),而解码器则尝试根据这个编码重构原始输入。这种模型的目标是在尽可能保持重构误差最小的前提下,学习到输入数据的有效表示。
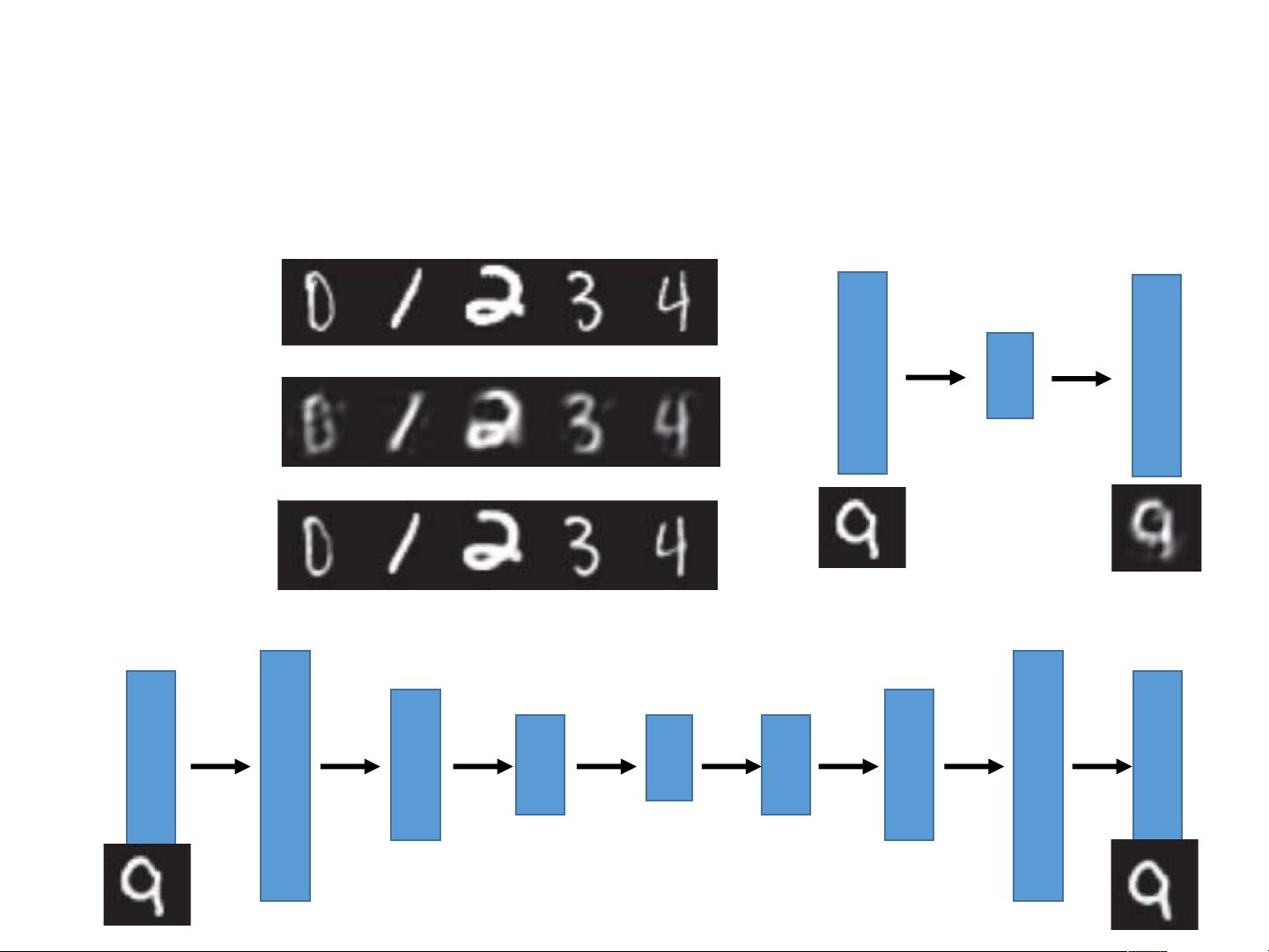
自编码器的基本架构通常包括输入层、隐藏层和输出层。在简单的自编码器中,输入层与输出层神经元数量相等,如图所示,对于28x28大小的图像,会有784个神经元。隐藏层作为瓶颈层,其神经元数量小于输入层,如500或250个。这一设计迫使模型在压缩过程中学习数据的主要特征,从而实现数据降维。隐藏层的输出即为编码,通过解码器可以重构出原始输入。
深度自编码器(Deep Auto-encoder)则是在此基础之上增加了更多隐藏层,形成更深的网络结构。这些额外的层次可以捕获更复杂的数据模式,提供更精细的特征表示。深度自编码器的每一层可以逐层训练,通常使用受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)进行预训练,然后再进行端到端的微调。
Hinton和Salakhutdinov在2006年的科学论文中提出,神经网络可以用于减少数据的维度性。自编码器不仅可以用于数据降维,还可以应用于特征学习、数据去噪、文本检索等多个领域。例如,课件中提到了用自编码器处理精灵宝可梦图像(Pokemon)的例子,展示了如何利用自编码器对图像进行降维和可视化。
此外,自编码器在文本检索中也有应用。例如,对于输入的一段文本,如"This is an apple",可以将其转化为一个编码向量,然后在解码器中恢复为原来的词序列。在文本处理中,自编码器可以用于构建词的表示,比如使用bag-of-words模型捕捉语义信息,从而实现文本的检索和分析。
李宏毅教授的课件深入浅出地介绍了深度自编码器的概念、结构及其在无监督学习中的应用,是学习机器学习特别是无监督学习方法的宝贵资源。
Deep Auto-encoder
Original
Image
PCA
Deep
Auto-encoder
784
784
784
1000
500
250
30
250
500
1000
784
30
剩余23页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-01-08 上传
2020-09-30 上传
141 浏览量
2017-12-17 上传

程序猿2023
- 粉丝: 343
- 资源: 16
 我的内容管理
展开
我的内容管理
展开







最新资源
- MessageBoard:一个用 Ember.js 编写的留言板应用
- abiramen.github.io
- SourceCodeViewer:网页原始码查看器
- 【精品推荐】智慧档案馆大数据智慧档案馆信息化解决方案汇总共5份.zip
- demandanalysis,java源码学习,java源码教学
- pybind11-initialsteps:一些可能对pybind11有用的示例程序
- cv-lin:网页简历原始码
- React-Codeial
- chan65chancleta20:Basi HTML页面
- GGOnItsOwnYo:带有 Yeoman 脚手架的 MEAN 堆栈
- 支持部署动态网站和静态网站
- Shopping,java源码之家,java授权系统
- scottzirkel:在https上找到的个人站点
- chan65chancleta19:Basi HTML页面
- Mihirvijdeshpande
- cure:Cure.js 是 JavaScript Polyfill 的集合,可帮助确保您的项目跨浏览器兼容
