Hadoop集群部署实战:从HA到MongoDB
下载需积分: 11 | DOCX格式 | 1.41MB |
更新于2024-07-15
| 123 浏览量 | 举报
"该文档详细介绍了大数据工程师在部署Hadoop生态圈时所涉及的各个组件,包括Hadoop HA(高可用性)部署、Zookeeper安装、Hive、Hbase、Sqoop、Flume、Spark、Storm、Kafka以及MongoDB的部署。在部署过程中,会遇到可能出现的错误,文档提供了必要的解决方法。"
在大数据环境中,Hadoop是一个关键的开源框架,用于处理和存储大量数据。Hadoop HA部署是确保系统高可用性和容错性的关键步骤。在部署Hadoop HA之前,需要完成一系列的准备工作:
1. 首先,需要在服务器上安装基础操作系统,如CentOS 7。然后,配置网络设置,确保服务器能够正确通信,这包括设置静态IP地址、网关和DNS服务器。
2. 安装Java运行环境是必不可少的,因为Hadoop和其他组件依赖于Java。使用`yum`命令安装OpenJDK 1.8,并更新系统环境变量,使得系统能够识别Java路径。
3. 在完成了基本环境的配置后,可以克隆虚拟机以创建集群。通常,Hadoop HA部署需要至少三个节点:一个NameNode主节点和两个DataNode从节点。克隆后的虚拟机需要分别配置不同的IP地址,以避免IP冲突。
4. 对于Hadoop HA,需要配置HDFS的NameNode高可用,这通常涉及到Active和Standby两种状态的NameNode,以及JournalNode来记录HDFS元数据的更改。Zookeeper集群在此过程中起到仲裁角色,决定哪个NameNode是活动的。
5. Hive是基于Hadoop的数据仓库工具,用于数据ETL(提取、转换、加载)和查询。在部署Hive时,需要配置Hive Metastore,它存储着Hive表的元数据信息。
6. Hbase是NoSQL数据库,与Hadoop紧密集成,提供实时数据访问。其部署涉及设置Hbase的Master和RegionServer。
7. Sqoop是一个工具,用于在Hadoop和关系型数据库之间导入导出数据。Flume则用于收集、聚合和移动日志数据。两者都是大数据分析链路中的重要环节。
8. Spark是一个快速且通用的大数据处理引擎,支持批处理、流处理和交互式查询。Storm则是实时数据处理系统,适合连续计算。
9. Kafka是一个分布式流处理平台,用于构建实时数据管道和流应用。它在消息传递中扮演重要角色,提供低延迟的数据传输。
10. MongoDB是一个流行的NoSQL数据库,可用于存储非结构化或半结构化数据。部署MongoDB时,需考虑复制集以实现高可用性。
整个部署过程不仅包含组件的安装,还需要进行相应的配置,如修改配置文件、启动服务、检查集群状态等。每个组件的部署都有可能遇到各种问题,因此在实施过程中,需要对Hadoop生态圈的原理有深入理解,并具备故障排查能力。文档中提到的“可能会出现差错”提示读者在实际操作中应做好应对可能出现问题的准备。

大数据工程师实训 – 课程设计
ssh-copy-id slave1
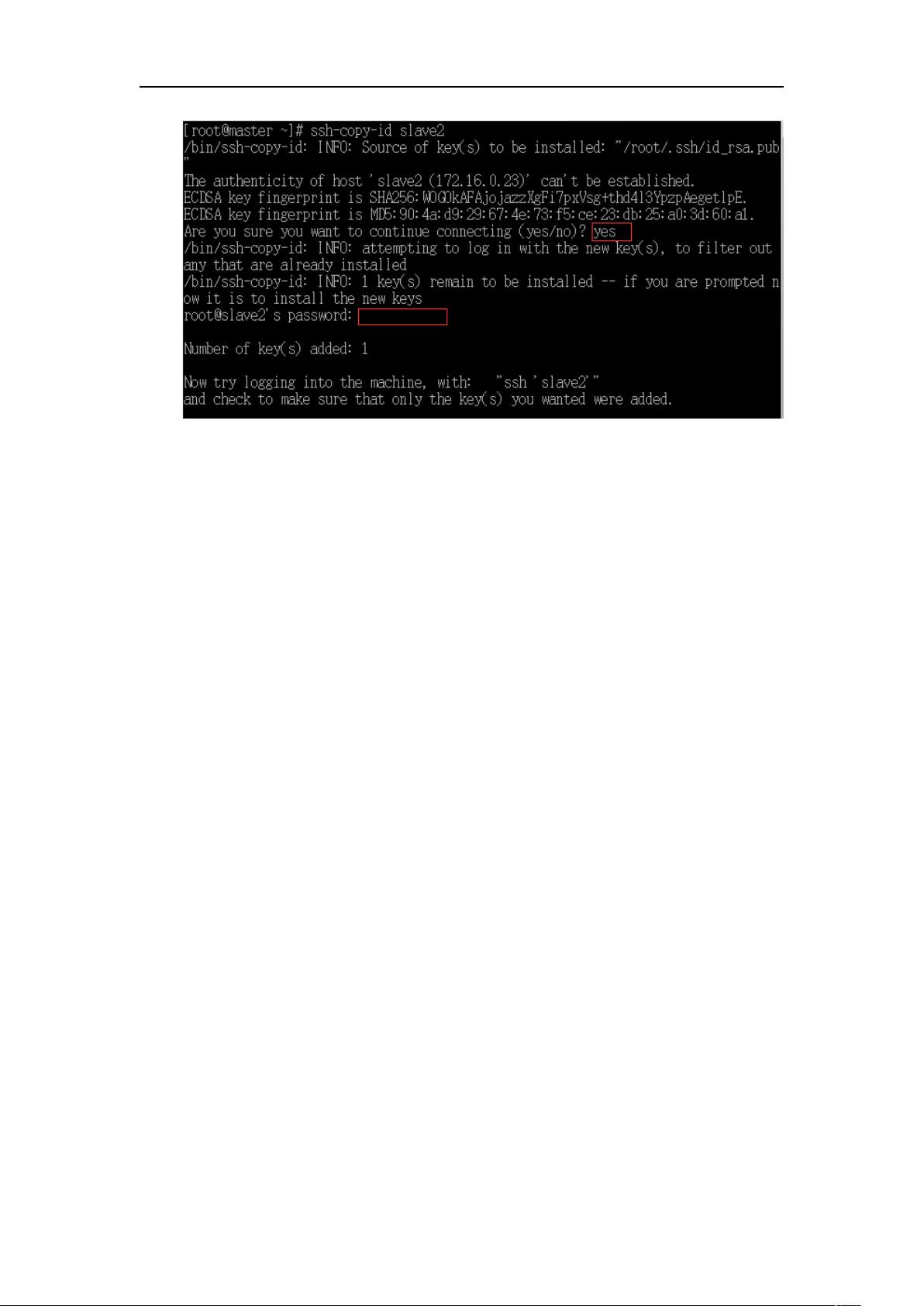
将公钥拷贝到从第三台虚拟机(slave2)上
(第一个红框位置输入 yes,第二个红输位置输入 slave2 的 root 密码)
ssh-copy-id slave2
7 / 41
剩余40页未读,继续阅读
相关推荐

但丁GG
- 粉丝: 26
 我的内容管理
展开
我的内容管理
展开







最新资源
- 山东大学单片机实验教程之LCD 1602显示实验详解
- Dockerized Debian/Ubuntu deb包构建器:一站式解决方案
- 数字五笔:电脑上的手机笔划输入法
- 轻松实现自定义标签输入,Bootstrap-tagsinput组件教程
- Android页面跳转与数据传递的入门示例
- 又拍图片下载器:批量下载相册图片的利器
- 探索《Learning Python》第五版英文原版精髓
- Spring Cloud应用演示:掌握云计算开发
- 如何撰写奖学金申请书的完整指南
- 全面学成管理系统源码:涵盖多技术领域
- LiipContainerWrapperBundle废弃指南:细粒度控制DI注入
- CHM电子书反编译工具:一键还原内容
- 理解PopupWindows回调接口的实现案例
- Osprey网络可视化系统:开源软件平台介绍
- React组件:在谷歌地图上渲染自定义UI
- LiipUrlAutoConverterBundle不再维护:自动转换URL和邮件链接
